🚀 huggingface/transformers - Release Notes
Deepseek v3 (based on 4.50.3) (2025-03-28)
A new model is added to transformers: DeepSeek 3 (Also known as DeepSeek R1).
It is added on top of the v4.50.3 release, and can be installed from the following tag: v4.50.3-DeepSeek-3.
In order to install this version, please install with the following command:
```
pip install git+https://github.com/huggingface/transformers@v4.50.3-DeepSeek-3
```
If fixes are needed, they will be applied to this release; this installation may therefore be considered as stable and improving.
## DeepSeek 3 (Also known as DeepSeek R1)

The model is detailed in the following [paper](https://huggingface.co/papers/2501.12948).
## Overview
The DeepSeek-V3 model was proposed in [DeepSeek-V3 Technical Report](https://arxiv.org/abs/2412.19437) by DeepSeek-AI Team.
The abstract from the paper is the following:
*We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.*
## Limitations and call for contribution!
We are super happy to make this code community-powered, and would love to see how you can help optimize the following:
- current implementation uses the "naive" attention compution (so not really MLA)
- current implementation loops through the experts. This should be replaced. Pointers to use `get_packed_weights` from `intetrations/tensor_parallel`.
- current implementation uses the eleuther formula for ROPE, using the orginal one would be more efficient! (should still follow our API)
- static cache is not supported (this should be just a generation config issue / config shape issues)
### Usage tips
The model uses Multi-head Latent Attention (MLA) and DeepSeekMoE architectures for efficient inference and cost-effective training. It employs an auxiliary-loss-free strategy for load balancing and multi-token prediction training objective. The model can be used for various language tasks after being pre-trained on 14.8 trillion tokens and going through Supervised Fine-Tuning and Reinforcement Learning stages.
You can run the model in `FP8` automatically, using 2 nodes of 8 H100 should be more than enough!
```python
# `run_deepseek_v1.py`
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(30)
tokenizer = AutoTokenizer.from_pretrained("deepseek-r1")
chat = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
model = AutoModelForCausalLM.from_pretrained("deepseek-r1", device_map="auto", torch_dtype=torch.bfloat16)
inputs = tokenizer.apply_chat_template(chat, tokenize=True, add_generation_prompt=True, return_tensors="pt").to(model.device)
outputs = model.generate(inputs, max_new_tokens=50)
print(tokenizer.batch_decode(outputs))
```
This generated:
``````
<|Assistant|>
Okay, the user wants to demonstrate how chat templating works. Let me break down what that means. Chat templating is about structuring the conversation data, especially for models that need specific input formats. Maybe they're referring to something like how messages are formatted with roles (user, assistant, system) in APIs like OpenAI.
First, I should explain what chat templating is. It's the process of formatting conversation data into a structured format that the model can understand. This usually includes roles and content. For example, user messages, assistant responses, and system messages each have their own role tags.
They might want an example. Let me think of a simple conversation. The user says "Hello, how are you?" and the assistant responds "I'm doing great. How can I help you today?" Then the user follows up with wanting to show off chat templating. So the example should include the history and the new message.
In some frameworks, like Hugging Face's Transformers, chat templates are applied using Jinja2 templates. The template might look something like combining system messages, then looping through user and assistant messages with appropriate tags. For instance, using {% for message in messages %} and assigning roles like <|user|>, <|assistant|>, etc.
I should structure the example with the messages array, showing each role and content. Then apply a hypothetical template to convert that into a formatted string the model uses. Also, mention that different models have different templating requirements, like using special tokens or varying role labels.
Wait, the user mentioned "chat templating" in the context of showing off. Maybe they want a practical example they can present. So providing a code snippet or a structured data example would be helpful. Let me outline a typical messages array and then the templated output.
Also, it's important to note that proper templating ensures the model knows the conversation flow, which is crucial for generating coherent responses. Maybe include a note about why it's important, like maintaining context and role-specific processing.
Let me check if there are any common mistakes or things to avoid. For example, not closing tags properly, or mismatching roles. But maybe that's too detailed unless the user asks. Focus on the positive example first.
Putting it all together, the response should have an example messages array, the applied template, and the final formatted string. Maybe use angle brackets or special tokens as placeholders. Also, mention that this helps in training or fine-tuning models with structured data.
I think that's a solid approach. Let me structure it step by step to make it clear.
Chat templating is a way to structure conversation data (e.g., user/assistant interactions) into a format that language models understand. This is especially important for models trained to handle multi-turn dialogues, where the input must explicitly separate roles (user, assistant, system, etc.) and messages. Let’s break this down with an example!
---
### **Step 1: Raw Conversation History**
Suppose we have this conversation:
- **User**: "Hello, how are you?"
- **Assistant**: "I'm doing great. How can I help you today?"
- **User**: "I'd like to show off how chat templating works!"
---
### **Step 2: Structured Messages**
In frameworks like Hugging Face Transformers or OpenAI, conversations are often formatted as a list of dictionaries with `role` and `content`:
```python
messages = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
```
---
### **Step 3: Apply a Chat Template**
A **chat template** converts this structured data into a single string formatted for the model. For example, using a Jinja-style template (common in Hugging Face):
```jinja
{% for message in messages %}
{% if message['role'] == 'user' %}
<|user|>{{ message['content'] }}<|end|>
{% elif message['role'] == 'assistant' %}
<|assistant|>{{ message['content'] }}<|end|>
{% endif %}
{% endfor %}
<|assistant|>
```
---
### **Step 4: Final Templated Output**
Applying the template to our `messages` list would produce:
```text
<|user|>Hello, how are you?<|end|>
<|assistant|>I'm doing great. How can I help you today?<|end|>
<|user|>I'd like to show off how chat templating works!<|end|>
<|assistant|>
```
This tells the model:
1. The conversation history (user/assistant turns).
2. The model’s turn to generate a response (`<|assistant|>` at the end).
---
### **Key Notes**:
- **Role Separation**: Tags like `<|user|>` and `<|assistant|>` help the model distinguish speakers.
- **Special Tokens**: Models often use unique tokens (e.g., `<|end|>`) to mark message boundaries.
- **Flexibility**: Templates vary by model (e.g., OpenAI uses `{"role": "user", "content": "..."}` instead of tags).
---
### **Why This Matters**:
- **Consistency**: Ensures the model understands dialogue structure.
- **Context Preservation**: Maintains the flow of multi-turn conversations.
- **Alignment**: Matches the format the model was trained on for better performance.
Want to dive deeper or see a specific framework’s implementation (e.g., OpenAI, Llama, Mistral)? Let me know! 😊<|end▁of▁sentence|>
``````
Use the following to run it
```bash
torchrun --nproc_per_node=8 --nnodes=2 --node_rank=0|1 --rdzv-id an_id --rdzv-backend c10d --rdzv-endpoint master_addr:master_port run_deepseek_r1.py
```
If you have:
```bash
[rank0]: ncclInternalError: Internal check failed.
[rank0]: Last error:
[rank0]: Bootstrap : no socket interface found
```
error, it means NCCL was probably not loaded.
Patch release v4.50.3 (2025-03-28)
# Patch release v4.50.3
Thanks to the vllm team we have a few more bugs that slipped in!
- [generate] beam search -- fix output cropping (#37080) by @gante
- [blip-2] Fix dtype mismatch when keep in fp32 (#37068) by @zucchini-nlp
- Fix PixtralProcessor patch_size when spatial_merge_size is used (#37019)
Patch release v4.50.2 (2025-03-27)
# Patch release v4.50.2
I completely forgot to put these in the previous patch sorry!
Should put the transformers backend in a good spot!
* [Utils] torch version checks optionally accept dev versions (#36847) by @gante
* Fix processor kwargs qwen2 vl (#36890) by @yonigozlan
* Fix Pan and Scan on batched images Gemma3 (#36864) by @yonigozlan
Patch release v4.50.1 (2025-03-25)
# Patch release v4.50.1
There were some very minor bugs with the new hub kernels, and with remote code that we had to fix
- Deprecate #36741 and map Causal to Conditional (#36917) by @zucchini-nlp
- Fix pytorch deform attn path (#36923) by @qubvel
- [chameleon] fix num image token check (#36918) by @zucchini-nlp
- Fix torch version guard at import (#36907) by @zucchini-nlp
Release v4.50.0 (2025-03-21)
# Release v4.50.0
## New Model Additions
### Model-based releases
Starting with version v4.49.0, we have been doing model-based releases, additionally to our traditional, software-based monthly releases. These model-based releases provide a tag from which models may be installed.
Contrarily to our software-releases; these are not pushed to pypi and are kept on our GitHub. Each release has a tag attributed to it, such as:
- `v4.49.0-Gemma-3`
- `v4.49.0-AyaVision`
⚠️ As bugs are identified and fixed on each model, the release tags are updated so that installing from that tag always gives the best experience possible with that model.
Each new model release will always be based on the current state of the main branch at the time of its creation. This ensures that new models start with the latest features and fixes available.
For example, if two models—Gemma-3 and AyaVision—are released from main, and then a fix for gemma3 is merged, it will look something like this:
```
o---- v4.49.0-Gemma-3 (includes AyaVision, plus main fixes)
/ \
---o--o--o--o--o-- (fix for gemma3) --o--o--o main
\
o---- v4.49.0-AyaVision
```
We strive to merge model specific fixes on their respective branches as fast as possible!
### Gemma 3

Gemma 3 is heavily referenced in the following [model-based release](https://github.com/huggingface/transformers/releases/tag/v4.49.0-Gemma-3) and we recommend reading these if you want all the information relative to that model.
The Gemma 3 model was proposed by Google. It is a vision-language model composed by a [SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip) vision encoder and a [Gemma 2](https://huggingface.co/docs/transformers/model_doc/gemma_2) language decoder linked by a multimodal linear projection.
It cuts an image into a fixed number of tokens same way as Siglip if the image does not exceed certain aspect ratio. For images that exceed the given aspect ratio, it crops the image into multiple smaller pacthes and concatenates them with the base image embedding.
One particularity is that the model uses bidirectional attention on all the image tokens. Also, the model interleaves sliding window local attention with full causal attention in the language backbone, where each sixth layer is a full causal attention layer.
* Gemma3 by @RyanMullins in #36658
### Shield Gemma2
ShieldGemma 2 is built on [Gemma 3](https://ai.google.dev/gemma/docs/core/model_card_3), is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
- No Sexually Explicit content: The image shall not contain content that depicts explicit or graphic sexual acts (e.g., pornography, erotic nudity, depictions of rape or sexual assault).
- No Dangerous Content: The image shall not contain content that facilitates or encourages activities that could cause real-world harm (e.g., building firearms and explosive devices, promotion of terrorism, instructions for suicide).
- No Violence/Gore content: The image shall not contain content that depicts shocking, sensational, or gratuitous violence (e.g., excessive blood and gore, gratuitous violence against animals, extreme injury or moment of death).
We recommend using ShieldGemma 2 as an input filter to vision language models, or as an output filter of image generation systems. To train a robust image safety model, we curated training datasets of natural and synthetic images and instruction-tuned Gemma 3 to demonstrate strong performance.
* Shieldgemma2 #36678 by @RyanMullins
### Aya Vision
AyaVision is heavily referenced in the following [model-based release](https://github.com/huggingface/transformers/releases/tag/v4.49.0-AyaVision) and we recommend reading these if you want all the information relative to that model.

The Aya Vision 8B and 32B models is a state-of-the-art multilingual multimodal models developed by Cohere For AI. They build on the Aya Expanse recipe to handle both visual and textual information without compromising on the strong multilingual textual performance of the original model.
Aya Vision 8B combines the `Siglip2-so400-384-14` vision encoder with the Cohere CommandR-7B language model further post-trained with the Aya Expanse recipe, creating a powerful vision-language model capable of understanding images and generating text across 23 languages. Whereas, Aya Vision 32B uses Aya Expanse 32B as the language model.
Key features of Aya Vision include:
- Multimodal capabilities in 23 languages
- Strong text-only multilingual capabilities inherited from CommandR-7B post-trained with the Aya Expanse recipe and Aya Expanse 32B
- High-quality visual understanding using the Siglip2-so400-384-14 vision encoder
- Seamless integration of visual and textual information in 23 languages.
* Add aya by @ArthurZucker in #36521
### Mistral 3.1
Mistral 3.1 is heavily referenced in the following [model-based release](https://github.com/huggingface/transformers/releases/tag/v4.49.0-Mistral-3) and we recommend reading these if you want all the information relative to that model.

Building upon Mistral Small 3 (2501), Mistral Small 3.1 (2503) adds state-of-the-art vision understanding and enhances long context capabilities up to 128k tokens without compromising text performance. With 24 billion parameters, this model achieves top-tier capabilities in both text and vision tasks.
It is ideal for:
- Fast-response conversational agents.
- Low-latency function calling.
- Subject matter experts via fine-tuning.
- Local inference for hobbyists and organizations handling sensitive data.
- Programming and math reasoning.
- Long document understanding.
- Visual understanding.
* Add Mistral3 by @Cyrilvallez in #36790
### Smol VLM 2
SmolVLM-2 is heavily referenced in the following [model-based release](https://github.com/huggingface/transformers/releases/tag/v4.49.0-SmolVLM-2) and we recommend reading these if you want all the information relative to that model.

SmolVLM2 is an adaptation of the Idefics3 model with two main differences:
- It uses SmolLM2 for the text model.
- It supports multi-image and video inputs
* SmolVLM2 by @orrzohar in #36126
### SigLIP-2
SigLIP-2 is heavily referenced in the following [model-based release](https://github.com/huggingface/transformers/releases/tag/v4.49.0-SigLIP-2) and we recommend reading these if you want all the information relative to that model.

The SigLIP2 model was proposed in [SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features](https://huggingface.co/papers/2502.14786) by Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin,
Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen,
Andreas Steiner and Xiaohua Zhai.
The model comes in two variants
1) FixRes - model works with fixed resolution images (backward compatible with SigLIP v1)
2) NaFlex - model works with variable image aspect ratios and resolutions (SigLIP2 in `transformers`)
* Add SigLIP 2 by @qubvel in #36323
### Prompt Depth Anything
PromptDepthAnything is a high-resolution, accurate metric depth estimation model that leverages prompting, inspired by its success in vision-language (VLMs) and large language models (LLMs). Using iPhone LiDAR as a prompt, the model generates precise depth maps at up to 4K resolution, unlocking the potential of depth foundation models.
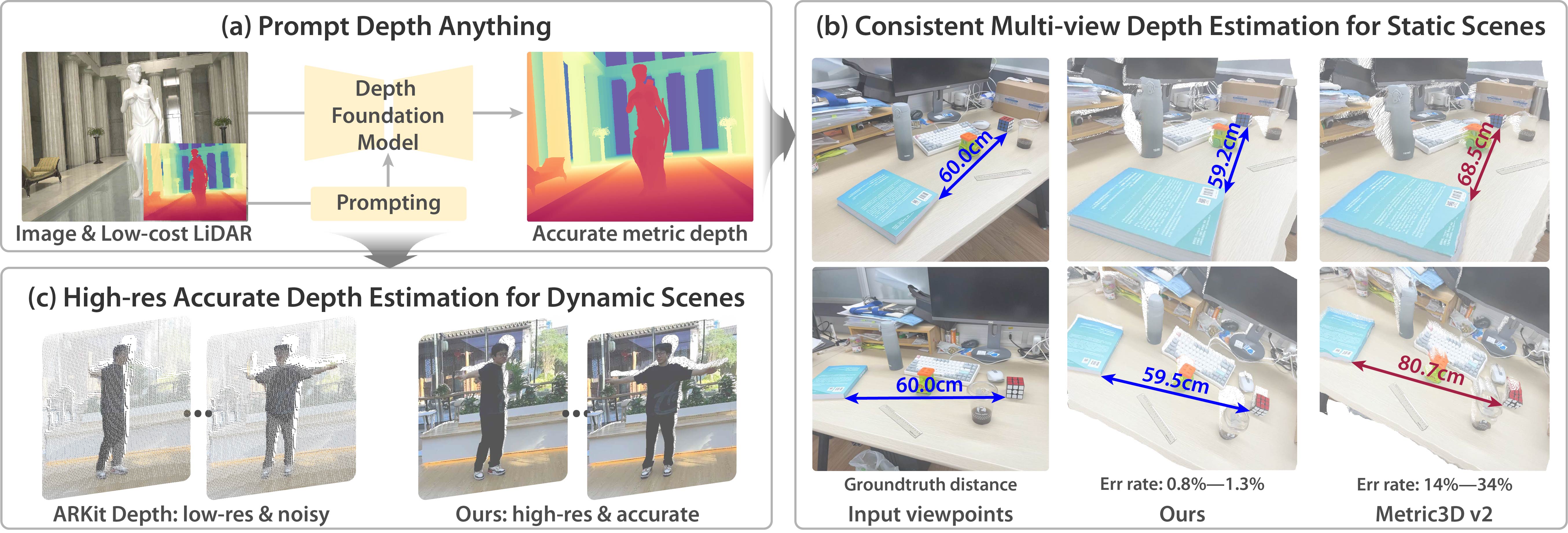
* Add Prompt Depth Anything Model by @haotongl in #35401
## New tool: attention visualization
We add a new tool to `transformers` to visualize the attention layout of a given model. It only requires a model ID as input, and will load the relevant tokenizer/model and display what the attention mask looks like. Some examples:
```py
from transformers.utils.attention_visualizer import AttentionMaskVisualizer
visualizer = AttentionMaskVisualizer("meta-llama/Llama-3.2-3B-Instruct")
visualizer("A normal attention mask")
visualizer = AttentionMaskVisualizer("mistralai/Mistral-Small-24B-Instruct-2501")
visualizer("A normal attention mask with a long text to see how it is displayed, and if it is displayed correctly")
visualizer = AttentionMaskVisualizer("google/paligemma2-3b-mix-224")
visualizer("![]() You are an assistant.", suffix = "What is on the image?")
visualizer = AttentionMaskVisualizer("google/gemma-2b")
visualizer("You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
visualizer = AttentionMaskVisualizer("google/gemma-3-27b-it")
visualizer("
You are an assistant.", suffix = "What is on the image?")
visualizer = AttentionMaskVisualizer("google/gemma-2b")
visualizer("You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
visualizer = AttentionMaskVisualizer("google/gemma-3-27b-it")
visualizer("![]() You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
```

* Add attention visualization tool by @ArthurZucker in #36630
## Deprecating transformers.agents in favor of smolagents
We are deprecating `transformers.agents` in favour of the `smolagents` library. Read more about smolagents [here](https://huggingface.co/docs/smolagents/index).
* Deprecate transformers.agents by @aymeric-roucher in #36415
# Quantization
We support adding custom quantization method by using the `@register_quantization_config` and `@register_quantizer` decorator:
```python
@register_quantization_config("custom")
class CustomConfig(QuantizationConfigMixin):
pass
@register_quantizer("custom")
class CustomQuantizer(HfQuantizer):
pass
quantized_model = AutoModelForCausalLM.from_pretrained(
"facebook/opt-350m", quantization_config=CustomConfig(), torch_dtype="auto"
)
```
* Added Support for Custom Quantization by @keetrap in #35915
* Add Example for Custom quantization by @MekkCyber in #36286
AMD is developing its in-house quantizer named [Quark](https://quark.docs.amd.com/latest/) released under MIT license, which supports a broad range of quantization pre-processing, algorithms, dtypes and target hardware. You can now load a model quantized by quark library:
```python
# pip install amd-quark
model_id = "EmbeddedLLM/Llama-3.1-8B-Instruct-w_fp8_per_channel_sym"
model = AutoModelForCausalLM.from_pretrained(model_id)
model = model.to("cuda")
```
* Support loading Quark quantized models in Transformers by @fxmarty-amd and @BowenBao in #36372
Torchao is augmented with `autoquant` support, CPU-quantization, as well as new `AOBaseConfig` object instances for more advanced configuration.
* Add autoquant support for torchao quantizer by @jerryzh168 in #35503
* enable torchao quantization on CPU by @jiqing-feng in #36146
* Add option for ao base configs by @drisspg in #36526
## Tensor Parallelism implementation changes
At loading time, the parallelization is now applied module-by-module, so that no memory overhead is required compared to what the final weight distribution will be!
* TP initialization module-by-module by @Cyrilvallez in #35996
## Generation
This release includes two speed upgrades to `generate`:
1. Assisted generation now works with ANY model as an assistant, even with `do_sample=True`;
```py
from transformers import pipeline
import torch
prompt = "Alice and Bob"
checkpoint = "google/gemma-2-9b"
assistant_checkpoint = "double7/vicuna-68m"
pipe = pipeline(
"text-generation",
model=checkpoint,
assistant_model=assistant_checkpoint,
do_sample=True
)
pipe_output = pipe(prompt, max_new_tokens=50, do_sample=True)
print(pipe_output[0]["generated_text"])
```
2. Beam search was vectorized, and should be significantly faster with a large `num_beams`. The speedup is more visible on smaller models, where `model.forward` doesn't dominate the total run time.
* Universal Speculative Decoding `CandidateGenerator` by @keyboardAnt, @jmamou, and @gauravjain14 in #35029
* [generate] ✨ vectorized beam search ✨ by @gante in #35802
## Documentation
A significant redesign of our documentation has wrapped-up. The goal was to greatly simplify the `transformers` documentation, making it much more easy to navigate. Let us know what you think!
* [docs] Redesign by @stevhliu in #31757
## Notable repo maintenance
The research examples folder that was hosted in `transformers` is no more. We have moved it out of `transformers` and in the following repo: github.com/huggingface/transformers-research-projects/
* Remove research projects by @Rocketknight1 in #36645
We have updated our flex attention support so as to have it be on-par with our Flash Attention 2 support.
* Proper_flex by @ArthurZucker in #36643
### More models support flex attention now thanks to @qubvel
* Refactor Attention implementation for ViT-based models by @qubvel in #36545
### First integration of hub kernels for deformable detr!
- Use deformable_detr kernel from the Hub (#36853) by @danieldk
## Bugfixes and improvements
* [tests] fix `EsmModelIntegrationTest::test_inference_bitsandbytes` by @faaany in #36225
* Fix `LlavaForConditionalGenerationModelTest::test_config` after #36077 by @ydshieh in #36230
* AMD DeepSpeed image additional HIP dependencies by @ivarflakstad in #36195
* [generate] remove cache v4.47 deprecations by @gante in #36212
* Add missing atol to torch.testing.assert_close where rtol is specified by @ivarflakstad in #36234
* [tests] remove tf/flax tests in `/generation` by @gante in #36235
* [generate] Fix encoder decoder models attention mask by @eustlb in #36018
* Add compressed tensor in quant dockerfile by @SunMarc in #36239
* [tests] remove `test_export_to_onnx` by @gante in #36241
* Au revoir flaky `test_fast_is_faster_than_slow` by @ydshieh in #36240
* Fix TorchAoConfig not JSON serializable by @andrewor14 in #36206
* Remove flakiness in VLMs by @zucchini-nlp in #36242
* feat: add support for tensor parallel training workflow with accelerate by @kmehant in #34194
* Fix XGLM loss computation (PyTorch and TensorFlow) by @damianoamatruda in #35878
* GitModelIntegrationTest - flatten the expected slice tensor by @ivarflakstad in #36260
* Added Support for Custom Quantization by @keetrap in #35915
* Qwen2VL fix cos,sin dtypes to float when used with deepspeed by @ArdalanM in #36188
* Uniformize LlavaNextVideoProcessor kwargs by @yonigozlan in #35613
* Add support for post-processing kwargs in image-text-to-text pipeline by @yonigozlan in #35374
* Add dithering to the `Speech2TextFeatureExtractor` API. by @KarelVesely84 in #34638
* [tests] remove `pt_tf` equivalence tests by @gante in #36253
* TP initialization module-by-module by @Cyrilvallez in #35996
* [tests] deflake dither test by @gante in #36284
* [tests] remove flax-pt equivalence and cross tests by @gante in #36283
* [tests] make `test_from_pretrained_low_cpu_mem_usage_equal` less flaky by @gante in #36255
* Add Example for Custom quantization by @MekkCyber in #36286
* docs: Update README_zh-hans.md by @hyjbrave in #36269
* Fix callback handler reference by @SunMarc in #36250
* Make cache traceable by @IlyasMoutawwakil in #35873
* Fix broken CI on release branch due to missing conversion files by @ydshieh in #36275
* Ignore conversion files in test fetcher by @ydshieh in #36251
* SmolVLM2 by @orrzohar in #36126
* Fix typo in Pixtral example by @12v in #36302
* fix: prevent second save in the end of training if last step was saved already by @NosimusAI in #36219
* [smolvlm] make CI green by @gante in #36306
* Fix default attention mask of generate in MoshiForConditionalGeneration by @cyan-channel-io in #36171
* VLMs: even more clean-up by @zucchini-nlp in #36249
* Add SigLIP 2 by @qubvel in #36323
* [CI] Check test if the `GenerationTesterMixin` inheritance is correct 🐛 🔫 by @gante in #36180
* [tests] make quanto tests device-agnostic by @faaany in #36328
* Uses Collection in transformers.image_transforms.normalize by @CalOmnie in #36301
* Fix exploitable regexes in Nougat and GPTSan/GPTJNeoXJapanese by @Rocketknight1 in #36121
* [tests] enable bnb tests on xpu by @faaany in #36233
* Improve model loading for compressed tensor models by @rahul-tuli in #36152
* Change slack channel for mi250 CI to amd-hf-ci by @ivarflakstad in #36346
* Add autoquant support for torchao quantizer by @jerryzh168 in #35503
* Update amd pytorch index to match base image by @ivarflakstad in #36347
* fix(type): padding_side type should be Optional[str] by @shenxiangzhuang in #36326
* [Modeling] Reduce runtime when loading missing keys by @kylesayrs in #36312
* notify new model merged to `main` by @ydshieh in #36375
* Update modeling_llava_onevision.py by @yinsong1986 in #36391
* Load models much faster on accelerator devices!! by @Cyrilvallez in #36380
* [modular] Do not track imports in functions by @Cyrilvallez in #36279
* Fix `is_causal` fail with compile by @Cyrilvallez in #36374
* enable torchao quantization on CPU by @jiqing-feng in #36146
* Update _get_eval_sampler to reflect Trainer.tokenizer is deprecation self.tokenizer -> self.processing_class by @yukiman76 in #36315
* Fix doc formatting in forward passes & modular by @Cyrilvallez in #36243
* Added handling for length <2 of suppress_tokens for whisper by @andreystarenky in #36336
* addressing the issue #34611 to make FlaxDinov2 compatible with any batch size by @MHRDYN7 in #35138
* tests: revert change of torch_require_multi_gpu to be device agnostic by @dvrogozh in #35721
* [tests] enable autoawq tests on XPU by @faaany in #36327
* fix audio classification pipeline fp16 test on cuda by @jiqing-feng in #36359
* chore: fix function argument descriptions by @threewebcode in #36392
* Fix pytorch integration tests for SAM by @qubvel in #36397
* [CLI] add import guards by @gante in #36376
* Fix convert_to_rgb for SAM ImageProcessor by @MSt-10 in #36369
* Security fix for `benchmark.yml` by @ydshieh in #36402
* Fixed VitDet for non-squre Images by @cjfghk5697 in #35969
* Add retry hf hub decorator by @muellerzr in #35213
* Deprecate transformers.agents by @aymeric-roucher in #36415
* Fixing the docs corresponding to the breaking change in torch 2.6. by @Narsil in #36420
* add recommendations for NPU using flash_attn by @zheliuyu in #36383
* fix: prevent model access error during Optuna hyperparameter tuning by @emapco in #36395
* Universal Speculative Decoding `CandidateGenerator` by @keyboardAnt in #35029
* Fix compressed tensors config by @MekkCyber in #36421
* Update form pretrained to make TP a first class citizen by @ArthurZucker in #36335
* Fix Expected output for compressed-tensors tests by @MekkCyber in #36425
* restrict cache allocator to non quantized model by @SunMarc in #36428
* Change PR to draft when it is (re)opened by @ydshieh in #36417
* Fix permission by @ydshieh in #36443
* Fix another permission by @ydshieh in #36444
* Add `contents: write` by @ydshieh in #36445
* [save_pretrained ] Skip collecting duplicated weight by @wejoncy in #36409
* [generate] `torch.distributed`-compatible `DynamicCache` by @gante in #36373
* Lazy import libraries in `src/transformers/image_utils.py` by @hmellor in #36435
* Fix `hub_retry` by @ydshieh in #36449
* [GroundingDino] Fix grounding dino loss 🚨 by @EduardoPach in #31828
* Fix loading models with mismatched sizes by @qubvel in #36463
* [docs] fix bug in deepspeed config by @faaany in #36081
* Add Got-OCR 2 Fast image processor and refactor slow one by @yonigozlan in #36185
* Fix couples of issues from #36335 by @SunMarc in #36453
* Fix _load_state_dict_into_meta_model with device_map=None by @hlky in #36488
* Fix loading zero3 weights by @muellerzr in #36455
* Check `TRUST_REMOTE_CODE` for `RealmRetriever` for security by @ydshieh in #36511
* Fix kwargs UserWarning in SamImageProcessor by @MSt-10 in #36479
* fix torch_dtype, contiguous, and load_state_dict regression by @SunMarc in #36512
* Fix some typos in docs by @co63oc in #36502
* chore: fix message descriptions in arguments and comments by @threewebcode in #36504
* Fix pipeline+peft interaction by @Rocketknight1 in #36480
* Fix edge case for continue_final_message by @Rocketknight1 in #36404
* [Style] fix E721 warnings by @kashif in #36474
* Remove unused code by @Rocketknight1 in #36459
* [docs] Redesign by @stevhliu in #31757
* Add aya by @ArthurZucker in #36521
* chore: Fix typos in docs and examples by @co63oc in #36524
* Fix bamba tests amd by @ivarflakstad in #36535
* Fix links in quantization doc by @MekkCyber in #36528
* chore: enhance messages in docstrings by @threewebcode in #36525
* guard torch version for uint16 by @SunMarc in #36520
* Fix typos in tests by @co63oc in #36547
* Fix typos . by @zhanluxianshen in #36551
* chore: enhance message descriptions in parameters,comments,logs and docstrings by @threewebcode in #36554
* Delete redundancy if case in model_utils by @zhanluxianshen in #36559
* Modular Conversion --fix_and_overwrite on Windows by @hlky in #36583
* Integrate SwanLab for offline/online experiment tracking and local visualization by @ShaohonChen in #36433
* [bark] fix loading of generation config by @gante in #36587
* [XGLM] tag tests as slow by @gante in #36592
* fix: argument by @ariG23498 in #36558
* Mention UltraScale Playbook 🌌 in docs by @NouamaneTazi in #36589
* avoid errors when the size of `input_ids` passed to `PrefixConstrainedLogitsProcessor` is zero by @HiDolen in #36489
* Export base streamer. by @AndreasAbdi in #36500
* Github action for auto-assigning reviewers by @Rocketknight1 in #35846
* Update chat_extras.md with content correction by @krishkkk in #36599
* Update "who to tag" / "who can review" by @gante in #36394
* Fixed datatype related issues in `DataCollatorForLanguageModeling` by @capemox in #36457
* Fix check for XPU. PyTorch >= 2.6 no longer needs ipex. by @tripzero in #36593
* [`HybridCache`] disable automatic compilation by @gante in #36620
* Fix auto-assign reviewers by @Rocketknight1 in #36631
* chore: fix typos in language models by @threewebcode in #36586
* [docs] Serving LLMs by @stevhliu in #36522
* Refactor some core stuff by @ArthurZucker in #36539
* Fix bugs in mllama image processing by @tjohnson31415 in #36156
* Proper_flex by @ArthurZucker in #36643
* Fix AriaForConditionalGeneration flex attn test by @ivarflakstad in #36604
* Remove remote code warning by @Rocketknight1 in #36285
* Stop warnings from unnecessary torch.tensor() overuse by @Rocketknight1 in #36538
* [docs] Update docs dependency by @stevhliu in #36635
* Remove research projects by @Rocketknight1 in #36645
* Fix gguf docs by @SunMarc in #36601
* fix typos in the docs directory by @threewebcode in #36639
* Gemma3 by @RyanMullins in #36658
* HPU support by @IlyasMoutawwakil in #36424
* fix block mask typing by @ArthurZucker in #36661
* [CI] gemma 3 `make fix-copies` by @gante in #36664
* Fix bnb regression due to empty state dict by @SunMarc in #36663
* [core] Large/full refactor of `from_pretrained` by @Cyrilvallez in #36033
* Don't accidentally mutate the base_model_tp_plan by @Rocketknight1 in #36677
* Fix Failing GPTQ tests by @MekkCyber in #36666
* Remove hardcoded slow image processor class in processors supporting fast ones by @yonigozlan in #36266
* [quants] refactor logic for modules_to_not_convert by @SunMarc in #36672
* Remove differences between init and preprocess kwargs for fast image processors by @yonigozlan in #36186
* Refactor siglip2 fast image processor by @yonigozlan in #36406
* Fix rescale normalize inconsistencies in fast image processors by @yonigozlan in #36388
* [Cache] Don't initialize the cache on `meta` device by @gante in #36543
* Update config.torch_dtype correctly by @SunMarc in #36679
* Fix slicing for 0-dim param by @SunMarc in #36580
* Changing the test model in Quanto kv cache by @MekkCyber in #36670
* fix wandb hp search unable to resume from sweep_id by @bd793fcb in #35883
* Upgrading torch version and cuda version in quantization docker by @MekkCyber in #36264
* Change Qwen2_VL image processors to have init and call accept the same kwargs by @yonigozlan in #36207
* fix type annotation for ALL_ATTENTION_FUNCTIONS by @WineChord in #36690
* Fix dtype for params without tp_plan by @Cyrilvallez in #36681
* chore: fix typos in utils module by @threewebcode in #36668
* [CI] Automatic rerun of certain test failures by @gante in #36694
* Add loading speed test by @Cyrilvallez in #36671
* fix: fsdp sharded state dict wont work for save_only_model knob by @kmehant in #36627
* Handling an exception related to HQQ quantization in modeling by @MekkCyber in #36702
* Add GGUF support to T5-Encoder by @Isotr0py in #36700
* Final CI cleanup by @Rocketknight1 in #36703
* Add support for fast image processors in add-new-model-like CLI by @yonigozlan in #36313
* Gemma3 processor typo by @Kuangdd01 in #36710
* Make the flaky list a little more general by @Rocketknight1 in #36704
* Cleanup the regex used for doc preprocessing by @Rocketknight1 in #36648
* [model loading] don't `gc.collect()` if only 1 shard is used by @gante in #36721
* Fix/best model checkpoint fix by @seanswyi in #35885
* Try working around the processor registration bugs by @Rocketknight1 in #36184
* [tests] Parameterized `test_eager_matches_sdpa_inference` by @gante in #36650
* 🌐 [i18n-KO] Translated codegen.md to Korean by @maximizemaxwell in #36698
* Fix post_init() code duplication by @Cyrilvallez in #36727
* Fix grad accum arbitrary value by @IlyasMoutawwakil in #36691
* [Generation, Gemma 3] When passing a custom `generation_config`, overwrite default values with the model's base `generation_config` by @gante in #36684
* 🚨🚨🚨 Fix sdpa in SAM and refactor relative position embeddings by @geetu040 in #36422
* enable/disable compile for quants methods by @SunMarc in #36519
* fix can_generate by @jiqing-feng in #36570
* Allow ray datasets to be used with trainer by @FredrikNoren in #36699
* fix xpu tests by @jiqing-feng in #36656
* Fix test isolation for clear_import_cache utility by @sambhavnoobcoder in #36345
* Fix `TrainingArguments.torch_empty_cache_steps` post_init check by @pkuderov in #36734
* [MINOR:TYPO] Update hubert.md by @cakiki in #36733
* [CI] remove redundant checks in `test_eager_matches_sdpa_inference` by @gante in #36740
* [docs] Update README by @stevhliu in #36265
* doc: Clarify `is_decoder` usage in PretrainedConfig documentation by @d-kleine in #36724
* fix typos in the tests directory by @threewebcode in #36717
* chore: fix typos in tests directory by @threewebcode in #36785
* Fixing typo in gemma3 image_processor_fast and adding a small test by @Zebz13 in #36776
* Fix gemma3_text tokenizer in mapping by @LysandreJik in #36793
* Add Mistral3 by @Cyrilvallez in #36790
* fix hqq due to recent modeling changes by @SunMarc in #36771
* Update SHA for `tj-actions/changed-files` by @ydshieh in #36795
* Loading optimizations by @Cyrilvallez in #36742
* Fix Mistral3 tests by @yonigozlan in #36797
* Fix casting dtype for qunatization by @SunMarc in #36799
* Fix chameleon's TypeError because inputs_embeds may None by @YenFuLin in #36673
* Support custom dosctrings in modular by @yonigozlan in #36726
* [generate] ✨ vectorized beam search ✨ by @gante in #35802
* Expectations test utils by @ivarflakstad in #36569
* fix "Cannot copy out of meta tensor; no data!" issue for BartForConditionalGeneration model by @yao-matrix in #36572
* Remove `dist": "loadfile"` for `pytest` in CircleCI jobs by @ydshieh in #36811
* Fix Device map for bitsandbytes tests by @MekkCyber in #36800
* [Generation] remove leftover code from end-to-end compilation by @gante in #36685
* Add attention visualization tool by @ArthurZucker in #36630
* Add option for ao base configs by @drisspg in #36526
* enable OffloadedCache on XPU from PyTorch 2.7 by @yao-matrix in #36654
* [gemma 3] multimodal checkpoints + AutoModelForCausalLM by @gante in #36741
* One more fix for reviewer assignment by @Rocketknight1 in #36829
* Support tracable dynamicKVcache by @tugsbayasgalan in #36311
* Add Space to Bitsandbytes doc by @MekkCyber in #36834
* quick fix fast_image_processor register error by @JJJYmmm in #36716
* Update configuration_qwen2.py by @michaelfeil in #36735
* Just import torch AdamW instead by @Rocketknight1 in #36177
* Move the warning to the documentation for DataCollatorWithFlattening by @qgallouedec in #36707
* Fix swanlab global step by @Zeyi-Lin in #36728
* Disable inductor config setter by default by @HDCharles in #36608
* [ForCausalLMLoss] allow users to pass shifted labels by @stas00 in #36607
* fix tiktoken convert to pass AddedToken to Tokenizer by @itazap in #36566
* Saving `Trainer.collator.tokenizer` in when `Trainer.processing_class` is `None` by @innerNULL in #36552
* Pass num_items_in_batch directly to loss computation by @eljandoubi in #36753
* Fix fp16 ONNX export for RT-DETR and RT-DETRv2 by @qubvel in #36460
* Update deprecated Jax calls by @rasmi in #35919
* [qwen2 audio] remove redundant code and update docs by @gante in #36282
* Pass state dict by @phos-phophy in #35234
* [modular] Sort modular skips by @gante in #36304
* [generate] clarify docstrings: when to inherit `GenerationMixin` by @gante in #36605
* Update min safetensors bis by @SunMarc in #36823
* Fix import for torch 2.0, 2.1 - guard typehint for "device_mesh" by @qubvel in #36768
* Gemma 3: Adding explicit GenerationConfig and refactoring conversion … by @RyanMullins in #36833
* Fix: remove the redundant snippet of _whole_word_mask by @HuangBugWei in #36759
* Shieldgemma2 by @RyanMullins in #36678
* Fix ONNX export for sequence classification head by @echarlaix in #36332
* Fix hqq skipped modules and dynamic quant by @mobicham in #36821
* Use pyupgrade --py39-plus to improve code by @cyyever in #36843
* Support loading Quark quantized models in Transformers by @fxmarty-amd in #36372
* DeepSpeed tensor parallel+ZeRO by @inkcherry in #36825
* Refactor Attention implementation for ViT-based models by @qubvel in #36545
* Add Prompt Depth Anything Model by @haotongl in #35401
* Add model visual debugger by @molbap in #36798
* [torchao] revert to get_apply_tensor_subclass by @SunMarc in #36849
* Gemma3: fix test by @zucchini-nlp in #36820
* [CI] fix update metadata job by @gante in #36850
* Add support for seed in `DataCollatorForLanguageModeling` by @capemox in #36497
* Refactor Aya Vision with modular by @yonigozlan in #36688
* Mllama: raise better error by @zucchini-nlp in #35934
* [CI] doc builder without custom image by @gante in #36862
* FIX FSDP plugin update for QLoRA by @BenjaminBossan in #36720
* Remove call to `.item` in `get_batch_samples` by @regisss in #36861
* chore: fix typos in the tests directory by @threewebcode in #36813
* Make ViTPooler configurable by @sebbaur in #36517
* Revert "Update deprecated Jax calls by @ArthurZucker in #35919)"
* [generate] model defaults being inherited only happens for newer models by @gante in #36881
* :red_circle: :red_circle: :red_circle: supersede paligemma forward to shift pos id indexing by @molbap in #36859
* Gemma 3 tests expect greedy decoding by @molbap in #36882
* Use `deformable_detr` kernel from the Hub by @danieldk in #36853
* Minor Gemma 3 fixes by @molbap in #36884
* Fix: dtype cannot be str by @zucchini-nlp in #36262
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @IlyasMoutawwakil
* Make cache traceable (#35873)
* HPU support (#36424)
* Fix grad accum arbitrary value (#36691)
* @orrzohar
* SmolVLM2 (#36126)
* @threewebcode
* chore: fix function argument descriptions (#36392)
* chore: fix message descriptions in arguments and comments (#36504)
* chore: enhance messages in docstrings (#36525)
* chore: enhance message descriptions in parameters,comments,logs and docstrings (#36554)
* chore: fix typos in language models (#36586)
* fix typos in the docs directory (#36639)
* chore: fix typos in utils module (#36668)
* fix typos in the tests directory (#36717)
* chore: fix typos in tests directory (#36785)
* chore: fix typos in the tests directory (#36813)
* @aymeric-roucher
* Deprecate transformers.agents (#36415)
* @keyboardAnt
* Universal Speculative Decoding `CandidateGenerator` (#35029)
* @EduardoPach
* [GroundingDino] Fix grounding dino loss 🚨 (#31828)
* @co63oc
* Fix some typos in docs (#36502)
* chore: Fix typos in docs and examples (#36524)
* Fix typos in tests (#36547)
* @RyanMullins
* Gemma3 (#36658)
* Gemma 3: Adding explicit GenerationConfig and refactoring conversion … (#36833)
* Shieldgemma2 (#36678)
* @cyyever
* Use pyupgrade --py39-plus to improve code (#36843)
* @haotongl
* Add Prompt Depth Anything Model (#35401)
* @danieldk
* Use `deformable_detr` kernel from the Hub (#36853)
You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
```

* Add attention visualization tool by @ArthurZucker in #36630
## Deprecating transformers.agents in favor of smolagents
We are deprecating `transformers.agents` in favour of the `smolagents` library. Read more about smolagents [here](https://huggingface.co/docs/smolagents/index).
* Deprecate transformers.agents by @aymeric-roucher in #36415
# Quantization
We support adding custom quantization method by using the `@register_quantization_config` and `@register_quantizer` decorator:
```python
@register_quantization_config("custom")
class CustomConfig(QuantizationConfigMixin):
pass
@register_quantizer("custom")
class CustomQuantizer(HfQuantizer):
pass
quantized_model = AutoModelForCausalLM.from_pretrained(
"facebook/opt-350m", quantization_config=CustomConfig(), torch_dtype="auto"
)
```
* Added Support for Custom Quantization by @keetrap in #35915
* Add Example for Custom quantization by @MekkCyber in #36286
AMD is developing its in-house quantizer named [Quark](https://quark.docs.amd.com/latest/) released under MIT license, which supports a broad range of quantization pre-processing, algorithms, dtypes and target hardware. You can now load a model quantized by quark library:
```python
# pip install amd-quark
model_id = "EmbeddedLLM/Llama-3.1-8B-Instruct-w_fp8_per_channel_sym"
model = AutoModelForCausalLM.from_pretrained(model_id)
model = model.to("cuda")
```
* Support loading Quark quantized models in Transformers by @fxmarty-amd and @BowenBao in #36372
Torchao is augmented with `autoquant` support, CPU-quantization, as well as new `AOBaseConfig` object instances for more advanced configuration.
* Add autoquant support for torchao quantizer by @jerryzh168 in #35503
* enable torchao quantization on CPU by @jiqing-feng in #36146
* Add option for ao base configs by @drisspg in #36526
## Tensor Parallelism implementation changes
At loading time, the parallelization is now applied module-by-module, so that no memory overhead is required compared to what the final weight distribution will be!
* TP initialization module-by-module by @Cyrilvallez in #35996
## Generation
This release includes two speed upgrades to `generate`:
1. Assisted generation now works with ANY model as an assistant, even with `do_sample=True`;
```py
from transformers import pipeline
import torch
prompt = "Alice and Bob"
checkpoint = "google/gemma-2-9b"
assistant_checkpoint = "double7/vicuna-68m"
pipe = pipeline(
"text-generation",
model=checkpoint,
assistant_model=assistant_checkpoint,
do_sample=True
)
pipe_output = pipe(prompt, max_new_tokens=50, do_sample=True)
print(pipe_output[0]["generated_text"])
```
2. Beam search was vectorized, and should be significantly faster with a large `num_beams`. The speedup is more visible on smaller models, where `model.forward` doesn't dominate the total run time.
* Universal Speculative Decoding `CandidateGenerator` by @keyboardAnt, @jmamou, and @gauravjain14 in #35029
* [generate] ✨ vectorized beam search ✨ by @gante in #35802
## Documentation
A significant redesign of our documentation has wrapped-up. The goal was to greatly simplify the `transformers` documentation, making it much more easy to navigate. Let us know what you think!
* [docs] Redesign by @stevhliu in #31757
## Notable repo maintenance
The research examples folder that was hosted in `transformers` is no more. We have moved it out of `transformers` and in the following repo: github.com/huggingface/transformers-research-projects/
* Remove research projects by @Rocketknight1 in #36645
We have updated our flex attention support so as to have it be on-par with our Flash Attention 2 support.
* Proper_flex by @ArthurZucker in #36643
### More models support flex attention now thanks to @qubvel
* Refactor Attention implementation for ViT-based models by @qubvel in #36545
### First integration of hub kernels for deformable detr!
- Use deformable_detr kernel from the Hub (#36853) by @danieldk
## Bugfixes and improvements
* [tests] fix `EsmModelIntegrationTest::test_inference_bitsandbytes` by @faaany in #36225
* Fix `LlavaForConditionalGenerationModelTest::test_config` after #36077 by @ydshieh in #36230
* AMD DeepSpeed image additional HIP dependencies by @ivarflakstad in #36195
* [generate] remove cache v4.47 deprecations by @gante in #36212
* Add missing atol to torch.testing.assert_close where rtol is specified by @ivarflakstad in #36234
* [tests] remove tf/flax tests in `/generation` by @gante in #36235
* [generate] Fix encoder decoder models attention mask by @eustlb in #36018
* Add compressed tensor in quant dockerfile by @SunMarc in #36239
* [tests] remove `test_export_to_onnx` by @gante in #36241
* Au revoir flaky `test_fast_is_faster_than_slow` by @ydshieh in #36240
* Fix TorchAoConfig not JSON serializable by @andrewor14 in #36206
* Remove flakiness in VLMs by @zucchini-nlp in #36242
* feat: add support for tensor parallel training workflow with accelerate by @kmehant in #34194
* Fix XGLM loss computation (PyTorch and TensorFlow) by @damianoamatruda in #35878
* GitModelIntegrationTest - flatten the expected slice tensor by @ivarflakstad in #36260
* Added Support for Custom Quantization by @keetrap in #35915
* Qwen2VL fix cos,sin dtypes to float when used with deepspeed by @ArdalanM in #36188
* Uniformize LlavaNextVideoProcessor kwargs by @yonigozlan in #35613
* Add support for post-processing kwargs in image-text-to-text pipeline by @yonigozlan in #35374
* Add dithering to the `Speech2TextFeatureExtractor` API. by @KarelVesely84 in #34638
* [tests] remove `pt_tf` equivalence tests by @gante in #36253
* TP initialization module-by-module by @Cyrilvallez in #35996
* [tests] deflake dither test by @gante in #36284
* [tests] remove flax-pt equivalence and cross tests by @gante in #36283
* [tests] make `test_from_pretrained_low_cpu_mem_usage_equal` less flaky by @gante in #36255
* Add Example for Custom quantization by @MekkCyber in #36286
* docs: Update README_zh-hans.md by @hyjbrave in #36269
* Fix callback handler reference by @SunMarc in #36250
* Make cache traceable by @IlyasMoutawwakil in #35873
* Fix broken CI on release branch due to missing conversion files by @ydshieh in #36275
* Ignore conversion files in test fetcher by @ydshieh in #36251
* SmolVLM2 by @orrzohar in #36126
* Fix typo in Pixtral example by @12v in #36302
* fix: prevent second save in the end of training if last step was saved already by @NosimusAI in #36219
* [smolvlm] make CI green by @gante in #36306
* Fix default attention mask of generate in MoshiForConditionalGeneration by @cyan-channel-io in #36171
* VLMs: even more clean-up by @zucchini-nlp in #36249
* Add SigLIP 2 by @qubvel in #36323
* [CI] Check test if the `GenerationTesterMixin` inheritance is correct 🐛 🔫 by @gante in #36180
* [tests] make quanto tests device-agnostic by @faaany in #36328
* Uses Collection in transformers.image_transforms.normalize by @CalOmnie in #36301
* Fix exploitable regexes in Nougat and GPTSan/GPTJNeoXJapanese by @Rocketknight1 in #36121
* [tests] enable bnb tests on xpu by @faaany in #36233
* Improve model loading for compressed tensor models by @rahul-tuli in #36152
* Change slack channel for mi250 CI to amd-hf-ci by @ivarflakstad in #36346
* Add autoquant support for torchao quantizer by @jerryzh168 in #35503
* Update amd pytorch index to match base image by @ivarflakstad in #36347
* fix(type): padding_side type should be Optional[str] by @shenxiangzhuang in #36326
* [Modeling] Reduce runtime when loading missing keys by @kylesayrs in #36312
* notify new model merged to `main` by @ydshieh in #36375
* Update modeling_llava_onevision.py by @yinsong1986 in #36391
* Load models much faster on accelerator devices!! by @Cyrilvallez in #36380
* [modular] Do not track imports in functions by @Cyrilvallez in #36279
* Fix `is_causal` fail with compile by @Cyrilvallez in #36374
* enable torchao quantization on CPU by @jiqing-feng in #36146
* Update _get_eval_sampler to reflect Trainer.tokenizer is deprecation self.tokenizer -> self.processing_class by @yukiman76 in #36315
* Fix doc formatting in forward passes & modular by @Cyrilvallez in #36243
* Added handling for length <2 of suppress_tokens for whisper by @andreystarenky in #36336
* addressing the issue #34611 to make FlaxDinov2 compatible with any batch size by @MHRDYN7 in #35138
* tests: revert change of torch_require_multi_gpu to be device agnostic by @dvrogozh in #35721
* [tests] enable autoawq tests on XPU by @faaany in #36327
* fix audio classification pipeline fp16 test on cuda by @jiqing-feng in #36359
* chore: fix function argument descriptions by @threewebcode in #36392
* Fix pytorch integration tests for SAM by @qubvel in #36397
* [CLI] add import guards by @gante in #36376
* Fix convert_to_rgb for SAM ImageProcessor by @MSt-10 in #36369
* Security fix for `benchmark.yml` by @ydshieh in #36402
* Fixed VitDet for non-squre Images by @cjfghk5697 in #35969
* Add retry hf hub decorator by @muellerzr in #35213
* Deprecate transformers.agents by @aymeric-roucher in #36415
* Fixing the docs corresponding to the breaking change in torch 2.6. by @Narsil in #36420
* add recommendations for NPU using flash_attn by @zheliuyu in #36383
* fix: prevent model access error during Optuna hyperparameter tuning by @emapco in #36395
* Universal Speculative Decoding `CandidateGenerator` by @keyboardAnt in #35029
* Fix compressed tensors config by @MekkCyber in #36421
* Update form pretrained to make TP a first class citizen by @ArthurZucker in #36335
* Fix Expected output for compressed-tensors tests by @MekkCyber in #36425
* restrict cache allocator to non quantized model by @SunMarc in #36428
* Change PR to draft when it is (re)opened by @ydshieh in #36417
* Fix permission by @ydshieh in #36443
* Fix another permission by @ydshieh in #36444
* Add `contents: write` by @ydshieh in #36445
* [save_pretrained ] Skip collecting duplicated weight by @wejoncy in #36409
* [generate] `torch.distributed`-compatible `DynamicCache` by @gante in #36373
* Lazy import libraries in `src/transformers/image_utils.py` by @hmellor in #36435
* Fix `hub_retry` by @ydshieh in #36449
* [GroundingDino] Fix grounding dino loss 🚨 by @EduardoPach in #31828
* Fix loading models with mismatched sizes by @qubvel in #36463
* [docs] fix bug in deepspeed config by @faaany in #36081
* Add Got-OCR 2 Fast image processor and refactor slow one by @yonigozlan in #36185
* Fix couples of issues from #36335 by @SunMarc in #36453
* Fix _load_state_dict_into_meta_model with device_map=None by @hlky in #36488
* Fix loading zero3 weights by @muellerzr in #36455
* Check `TRUST_REMOTE_CODE` for `RealmRetriever` for security by @ydshieh in #36511
* Fix kwargs UserWarning in SamImageProcessor by @MSt-10 in #36479
* fix torch_dtype, contiguous, and load_state_dict regression by @SunMarc in #36512
* Fix some typos in docs by @co63oc in #36502
* chore: fix message descriptions in arguments and comments by @threewebcode in #36504
* Fix pipeline+peft interaction by @Rocketknight1 in #36480
* Fix edge case for continue_final_message by @Rocketknight1 in #36404
* [Style] fix E721 warnings by @kashif in #36474
* Remove unused code by @Rocketknight1 in #36459
* [docs] Redesign by @stevhliu in #31757
* Add aya by @ArthurZucker in #36521
* chore: Fix typos in docs and examples by @co63oc in #36524
* Fix bamba tests amd by @ivarflakstad in #36535
* Fix links in quantization doc by @MekkCyber in #36528
* chore: enhance messages in docstrings by @threewebcode in #36525
* guard torch version for uint16 by @SunMarc in #36520
* Fix typos in tests by @co63oc in #36547
* Fix typos . by @zhanluxianshen in #36551
* chore: enhance message descriptions in parameters,comments,logs and docstrings by @threewebcode in #36554
* Delete redundancy if case in model_utils by @zhanluxianshen in #36559
* Modular Conversion --fix_and_overwrite on Windows by @hlky in #36583
* Integrate SwanLab for offline/online experiment tracking and local visualization by @ShaohonChen in #36433
* [bark] fix loading of generation config by @gante in #36587
* [XGLM] tag tests as slow by @gante in #36592
* fix: argument by @ariG23498 in #36558
* Mention UltraScale Playbook 🌌 in docs by @NouamaneTazi in #36589
* avoid errors when the size of `input_ids` passed to `PrefixConstrainedLogitsProcessor` is zero by @HiDolen in #36489
* Export base streamer. by @AndreasAbdi in #36500
* Github action for auto-assigning reviewers by @Rocketknight1 in #35846
* Update chat_extras.md with content correction by @krishkkk in #36599
* Update "who to tag" / "who can review" by @gante in #36394
* Fixed datatype related issues in `DataCollatorForLanguageModeling` by @capemox in #36457
* Fix check for XPU. PyTorch >= 2.6 no longer needs ipex. by @tripzero in #36593
* [`HybridCache`] disable automatic compilation by @gante in #36620
* Fix auto-assign reviewers by @Rocketknight1 in #36631
* chore: fix typos in language models by @threewebcode in #36586
* [docs] Serving LLMs by @stevhliu in #36522
* Refactor some core stuff by @ArthurZucker in #36539
* Fix bugs in mllama image processing by @tjohnson31415 in #36156
* Proper_flex by @ArthurZucker in #36643
* Fix AriaForConditionalGeneration flex attn test by @ivarflakstad in #36604
* Remove remote code warning by @Rocketknight1 in #36285
* Stop warnings from unnecessary torch.tensor() overuse by @Rocketknight1 in #36538
* [docs] Update docs dependency by @stevhliu in #36635
* Remove research projects by @Rocketknight1 in #36645
* Fix gguf docs by @SunMarc in #36601
* fix typos in the docs directory by @threewebcode in #36639
* Gemma3 by @RyanMullins in #36658
* HPU support by @IlyasMoutawwakil in #36424
* fix block mask typing by @ArthurZucker in #36661
* [CI] gemma 3 `make fix-copies` by @gante in #36664
* Fix bnb regression due to empty state dict by @SunMarc in #36663
* [core] Large/full refactor of `from_pretrained` by @Cyrilvallez in #36033
* Don't accidentally mutate the base_model_tp_plan by @Rocketknight1 in #36677
* Fix Failing GPTQ tests by @MekkCyber in #36666
* Remove hardcoded slow image processor class in processors supporting fast ones by @yonigozlan in #36266
* [quants] refactor logic for modules_to_not_convert by @SunMarc in #36672
* Remove differences between init and preprocess kwargs for fast image processors by @yonigozlan in #36186
* Refactor siglip2 fast image processor by @yonigozlan in #36406
* Fix rescale normalize inconsistencies in fast image processors by @yonigozlan in #36388
* [Cache] Don't initialize the cache on `meta` device by @gante in #36543
* Update config.torch_dtype correctly by @SunMarc in #36679
* Fix slicing for 0-dim param by @SunMarc in #36580
* Changing the test model in Quanto kv cache by @MekkCyber in #36670
* fix wandb hp search unable to resume from sweep_id by @bd793fcb in #35883
* Upgrading torch version and cuda version in quantization docker by @MekkCyber in #36264
* Change Qwen2_VL image processors to have init and call accept the same kwargs by @yonigozlan in #36207
* fix type annotation for ALL_ATTENTION_FUNCTIONS by @WineChord in #36690
* Fix dtype for params without tp_plan by @Cyrilvallez in #36681
* chore: fix typos in utils module by @threewebcode in #36668
* [CI] Automatic rerun of certain test failures by @gante in #36694
* Add loading speed test by @Cyrilvallez in #36671
* fix: fsdp sharded state dict wont work for save_only_model knob by @kmehant in #36627
* Handling an exception related to HQQ quantization in modeling by @MekkCyber in #36702
* Add GGUF support to T5-Encoder by @Isotr0py in #36700
* Final CI cleanup by @Rocketknight1 in #36703
* Add support for fast image processors in add-new-model-like CLI by @yonigozlan in #36313
* Gemma3 processor typo by @Kuangdd01 in #36710
* Make the flaky list a little more general by @Rocketknight1 in #36704
* Cleanup the regex used for doc preprocessing by @Rocketknight1 in #36648
* [model loading] don't `gc.collect()` if only 1 shard is used by @gante in #36721
* Fix/best model checkpoint fix by @seanswyi in #35885
* Try working around the processor registration bugs by @Rocketknight1 in #36184
* [tests] Parameterized `test_eager_matches_sdpa_inference` by @gante in #36650
* 🌐 [i18n-KO] Translated codegen.md to Korean by @maximizemaxwell in #36698
* Fix post_init() code duplication by @Cyrilvallez in #36727
* Fix grad accum arbitrary value by @IlyasMoutawwakil in #36691
* [Generation, Gemma 3] When passing a custom `generation_config`, overwrite default values with the model's base `generation_config` by @gante in #36684
* 🚨🚨🚨 Fix sdpa in SAM and refactor relative position embeddings by @geetu040 in #36422
* enable/disable compile for quants methods by @SunMarc in #36519
* fix can_generate by @jiqing-feng in #36570
* Allow ray datasets to be used with trainer by @FredrikNoren in #36699
* fix xpu tests by @jiqing-feng in #36656
* Fix test isolation for clear_import_cache utility by @sambhavnoobcoder in #36345
* Fix `TrainingArguments.torch_empty_cache_steps` post_init check by @pkuderov in #36734
* [MINOR:TYPO] Update hubert.md by @cakiki in #36733
* [CI] remove redundant checks in `test_eager_matches_sdpa_inference` by @gante in #36740
* [docs] Update README by @stevhliu in #36265
* doc: Clarify `is_decoder` usage in PretrainedConfig documentation by @d-kleine in #36724
* fix typos in the tests directory by @threewebcode in #36717
* chore: fix typos in tests directory by @threewebcode in #36785
* Fixing typo in gemma3 image_processor_fast and adding a small test by @Zebz13 in #36776
* Fix gemma3_text tokenizer in mapping by @LysandreJik in #36793
* Add Mistral3 by @Cyrilvallez in #36790
* fix hqq due to recent modeling changes by @SunMarc in #36771
* Update SHA for `tj-actions/changed-files` by @ydshieh in #36795
* Loading optimizations by @Cyrilvallez in #36742
* Fix Mistral3 tests by @yonigozlan in #36797
* Fix casting dtype for qunatization by @SunMarc in #36799
* Fix chameleon's TypeError because inputs_embeds may None by @YenFuLin in #36673
* Support custom dosctrings in modular by @yonigozlan in #36726
* [generate] ✨ vectorized beam search ✨ by @gante in #35802
* Expectations test utils by @ivarflakstad in #36569
* fix "Cannot copy out of meta tensor; no data!" issue for BartForConditionalGeneration model by @yao-matrix in #36572
* Remove `dist": "loadfile"` for `pytest` in CircleCI jobs by @ydshieh in #36811
* Fix Device map for bitsandbytes tests by @MekkCyber in #36800
* [Generation] remove leftover code from end-to-end compilation by @gante in #36685
* Add attention visualization tool by @ArthurZucker in #36630
* Add option for ao base configs by @drisspg in #36526
* enable OffloadedCache on XPU from PyTorch 2.7 by @yao-matrix in #36654
* [gemma 3] multimodal checkpoints + AutoModelForCausalLM by @gante in #36741
* One more fix for reviewer assignment by @Rocketknight1 in #36829
* Support tracable dynamicKVcache by @tugsbayasgalan in #36311
* Add Space to Bitsandbytes doc by @MekkCyber in #36834
* quick fix fast_image_processor register error by @JJJYmmm in #36716
* Update configuration_qwen2.py by @michaelfeil in #36735
* Just import torch AdamW instead by @Rocketknight1 in #36177
* Move the warning to the documentation for DataCollatorWithFlattening by @qgallouedec in #36707
* Fix swanlab global step by @Zeyi-Lin in #36728
* Disable inductor config setter by default by @HDCharles in #36608
* [ForCausalLMLoss] allow users to pass shifted labels by @stas00 in #36607
* fix tiktoken convert to pass AddedToken to Tokenizer by @itazap in #36566
* Saving `Trainer.collator.tokenizer` in when `Trainer.processing_class` is `None` by @innerNULL in #36552
* Pass num_items_in_batch directly to loss computation by @eljandoubi in #36753
* Fix fp16 ONNX export for RT-DETR and RT-DETRv2 by @qubvel in #36460
* Update deprecated Jax calls by @rasmi in #35919
* [qwen2 audio] remove redundant code and update docs by @gante in #36282
* Pass state dict by @phos-phophy in #35234
* [modular] Sort modular skips by @gante in #36304
* [generate] clarify docstrings: when to inherit `GenerationMixin` by @gante in #36605
* Update min safetensors bis by @SunMarc in #36823
* Fix import for torch 2.0, 2.1 - guard typehint for "device_mesh" by @qubvel in #36768
* Gemma 3: Adding explicit GenerationConfig and refactoring conversion … by @RyanMullins in #36833
* Fix: remove the redundant snippet of _whole_word_mask by @HuangBugWei in #36759
* Shieldgemma2 by @RyanMullins in #36678
* Fix ONNX export for sequence classification head by @echarlaix in #36332
* Fix hqq skipped modules and dynamic quant by @mobicham in #36821
* Use pyupgrade --py39-plus to improve code by @cyyever in #36843
* Support loading Quark quantized models in Transformers by @fxmarty-amd in #36372
* DeepSpeed tensor parallel+ZeRO by @inkcherry in #36825
* Refactor Attention implementation for ViT-based models by @qubvel in #36545
* Add Prompt Depth Anything Model by @haotongl in #35401
* Add model visual debugger by @molbap in #36798
* [torchao] revert to get_apply_tensor_subclass by @SunMarc in #36849
* Gemma3: fix test by @zucchini-nlp in #36820
* [CI] fix update metadata job by @gante in #36850
* Add support for seed in `DataCollatorForLanguageModeling` by @capemox in #36497
* Refactor Aya Vision with modular by @yonigozlan in #36688
* Mllama: raise better error by @zucchini-nlp in #35934
* [CI] doc builder without custom image by @gante in #36862
* FIX FSDP plugin update for QLoRA by @BenjaminBossan in #36720
* Remove call to `.item` in `get_batch_samples` by @regisss in #36861
* chore: fix typos in the tests directory by @threewebcode in #36813
* Make ViTPooler configurable by @sebbaur in #36517
* Revert "Update deprecated Jax calls by @ArthurZucker in #35919)"
* [generate] model defaults being inherited only happens for newer models by @gante in #36881
* :red_circle: :red_circle: :red_circle: supersede paligemma forward to shift pos id indexing by @molbap in #36859
* Gemma 3 tests expect greedy decoding by @molbap in #36882
* Use `deformable_detr` kernel from the Hub by @danieldk in #36853
* Minor Gemma 3 fixes by @molbap in #36884
* Fix: dtype cannot be str by @zucchini-nlp in #36262
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @IlyasMoutawwakil
* Make cache traceable (#35873)
* HPU support (#36424)
* Fix grad accum arbitrary value (#36691)
* @orrzohar
* SmolVLM2 (#36126)
* @threewebcode
* chore: fix function argument descriptions (#36392)
* chore: fix message descriptions in arguments and comments (#36504)
* chore: enhance messages in docstrings (#36525)
* chore: enhance message descriptions in parameters,comments,logs and docstrings (#36554)
* chore: fix typos in language models (#36586)
* fix typos in the docs directory (#36639)
* chore: fix typos in utils module (#36668)
* fix typos in the tests directory (#36717)
* chore: fix typos in tests directory (#36785)
* chore: fix typos in the tests directory (#36813)
* @aymeric-roucher
* Deprecate transformers.agents (#36415)
* @keyboardAnt
* Universal Speculative Decoding `CandidateGenerator` (#35029)
* @EduardoPach
* [GroundingDino] Fix grounding dino loss 🚨 (#31828)
* @co63oc
* Fix some typos in docs (#36502)
* chore: Fix typos in docs and examples (#36524)
* Fix typos in tests (#36547)
* @RyanMullins
* Gemma3 (#36658)
* Gemma 3: Adding explicit GenerationConfig and refactoring conversion … (#36833)
* Shieldgemma2 (#36678)
* @cyyever
* Use pyupgrade --py39-plus to improve code (#36843)
* @haotongl
* Add Prompt Depth Anything Model (#35401)
* @danieldk
* Use `deformable_detr` kernel from the Hub (#36853)
Mistral 3 (Based on v4.49.0) (2025-03-18)
A new model is added to transformers: Mistral 3.
It is added on top of the v4.49.0 release, and can be installed from the following tag: v4.49.0-Mistral-3.
In order to install this version, please install with the following command:
```
pip install git+https://github.com/huggingface/transformers@v4.49.0-Mistral-3
```
If fixes are needed, they will be applied to this release; this installation may therefore be considered as stable and improving.
# Mistral 3

The model is detailed in the following [blog post](https://mistral.ai/news/mistral-small-3-1).
The models are available on the Hub with the following tag: [`mistral3`](https://huggingface.co/models?other=mistral3)
## Overview
Building upon Mistral Small 3 (2501), Mistral Small 3.1 (2503) adds state-of-the-art vision understanding and enhances long context capabilities up to 128k tokens without compromising text performance. With 24 billion parameters, this model achieves top-tier capabilities in both text and vision tasks.
It is ideal for:
- Fast-response conversational agents.
- Low-latency function calling.
- Subject matter experts via fine-tuning.
- Local inference for hobbyists and organizations handling sensitive data.
- Programming and math reasoning.
- Long document understanding.
- Visual understanding.
This model was contributed by [cyrilvallez](https://huggingface.co/cyrilvallez) and [yonigozlan](https://huggingface.co/yonigozlan).
The original code can be found [here](https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/pixtral.py) and [here](https://github.com/mistralai/mistral-common).
## Usage example
### Inference with Pipeline
Here is how you can use the `image-text-to-text` pipeline to perform inference with the `Mistral3` models in just a few lines of code:
```python
>>> from transformers import pipeline
>>> messages = [
... {
... "role": "user",
... "content": [
... {
... "type": "image",
... "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg",
... },
... {"type": "text", "text": "Describe this image."},
... ],
... },
... ]
>>> pipe = pipeline("image-text-to-text", model="mistralai/Mistral-Small-3.1-24B-Instruct-2503", torch_dtype=torch.bfloat16)
>>> outputs = pipe(text=messages, max_new_tokens=50, return_full_text=False)
>>> outputs[0]["generated_text"]
'The image depicts a vibrant and lush garden scene featuring a variety of wildflowers and plants. The central focus is on a large, pinkish-purple flower, likely a Greater Celandine (Chelidonium majus), with a'
```
### Inference on a single image
This example demonstrates how to perform inference on a single image with the Mistral3 models using chat templates.
```python
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
>>> import torch
>>> torch_device = "cuda"
>>> model_checkpoint = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
>>> messages = [
... {
... "role": "user",
... "content": [
... {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
... {"type": "text", "text": "Describe this image"},
... ],
... }
... ]
>>> inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
>>> generate_ids = model.generate(**inputs, max_new_tokens=20)
>>> decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
>>> decoded_output
"The image depicts two cats lying on a pink blanket. The larger cat, which appears to be an"...
```
### Text-only generation
This example shows how to generate text using the Mistral3 model without providing any image input.
````python
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
>>> import torch
>>> torch_device = "cuda"
>>> model_checkpoint = ".mistralai/Mistral-Small-3.1-24B-Instruct-2503"
>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
>>> SYSTEM_PROMPT = "You are a conversational agent that always answers straight to the point, always end your accurate response with an ASCII drawing of a cat."
>>> user_prompt = "Give me 5 non-formal ways to say 'See you later' in French."
>>> messages = [
... {"role": "system", "content": SYSTEM_PROMPT},
... {"role": "user", "content": user_prompt},
... ]
>>> text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
>>> inputs = processor(text=text, return_tensors="pt").to(0, dtype=torch.float16)
>>> generate_ids = model.generate(**inputs, max_new_tokens=50, do_sample=False)
>>> decoded_output = processor.batch_decode(generate_ids[:, inputs["input_ids"].shape[1] :], skip_special_tokens=True)[0]
>>> print(decoded_output)
"1. À plus tard!
2. Salut, à plus!
3. À toute!
4. À la prochaine!
5. Je me casse, à plus!
```
/\_/\
( o.o )
> ^ <
```"
````
### Batched image and text inputs
Mistral3 models also support batched image and text inputs.
```python
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
>>> import torch
>>> torch_device = "cuda"
>>> model_checkpoint = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
>>> messages = [
... [
... {
... "role": "user",
... "content": [
... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
... {"type": "text", "text": "Write a haiku for this image"},
... ],
... },
... ],
... [
... {
... "role": "user",
... "content": [
... {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
... {"type": "text", "text": "Describe this image"},
... ],
... },
... ],
... ]
>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
>>> output = model.generate(**inputs, max_new_tokens=25)
>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
>>> decoded_outputs
["Write a haiku for this imageCalm waters reflect\nWhispers of the forest's breath\nPeace on wooden path"
, "Describe this imageThe image depicts a vibrant street scene in what appears to be a Chinatown district. The focal point is a traditional Chinese"]
```
### Batched multi-image input and quantization with BitsAndBytes
This implementation of the Mistral3 models supports batched text-images inputs with different number of images for each text.
This example also how to use `BitsAndBytes` to load the model in 4bit quantization.
```python
>>> from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
>>> import torch
>>> torch_device = "cuda"
>>> model_checkpoint = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
>>> quantization_config = BitsAndBytesConfig(load_in_4bit=True)
>>> model = AutoModelForImageTextToText.from_pretrained(
... model_checkpoint, quantization_config=quantization_config
... )
>>> messages = [
... [
... {
... "role": "user",
... "content": [
... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
... {"type": "text", "text": "Write a haiku for this image"},
... ],
... },
... ],
... [
... {
... "role": "user",
... "content": [
... {"type": "image", "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"},
... {"type": "image", "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"},
... {"type": "text", "text": "These images depict two different landmarks. Can you identify them?"},
... ],
... },
... ],
>>> ]
>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
>>> output = model.generate(**inputs, max_new_tokens=25)
>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
>>> decoded_outputs
["Write a haiku for this imageSure, here is a haiku inspired by the image:\n\nCalm lake's wooden path\nSilent forest stands guard\n", "These images depict two different landmarks. Can you identify them? Certainly! The images depict two iconic landmarks:\n\n1. The first image shows the Statue of Liberty in New York City."]
```
Gemma 3 (Based on v4.49.0) (2025-03-18)
A new model is added to transformers: Gemma 3.
It is added on top of the v4.49.0 release, and can be installed from the following tag: v4.49.0-Gemma-3.
In order to install this version, please install with the following command:
```
pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3
```
If fixes are needed, they will be applied to this release; this installation may therefore be considered as stable and improving.
# Gemma 3

The model is detailed in the following [blog post](https://huggingface.co/blog/gemma3).
The models and demos using the model are available in the following [collection](https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6d).
A Space to play around with the [12B-it flavor is available here](https://huggingface.co/spaces/huggingface-projects/gemma-3-12b-it).
## Overview
The Gemma 3 model was proposed by Google. It is a vision-language model composed by a [SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip) vision encoder and a [Gemma 2](https://huggingface.co/docs/transformers/model_doc/gemma_2) language decoder linked by a multimodal linear projection.
It cuts an image into a fixed number of tokens same way as Siglip if the image does not exceed certain aspect ratio. For images that exceed the given aspect ratio, it crops the image into multiple smaller pacthes and concatenates them with the base image embedding.
One particularity is that the model uses bidirectional attention on all the image tokens. Also, the model interleaves sliding window local attention with full causal attention in the language backbone, where each sixth layer is a full causal attention layer.
## Usage tips
- For image+text and image-only inputs use `Gemma3ForConditionalGeneration`.
- For text-only inputs use `Gemma3ForCausalLM` for generation to avoid loading the vision tower.
- Each sample can contain multiple images, and the number of images can vary between samples. However make sure to pass correctly batched images to the processor, where each batch is a list of one or more images.
- The text passed to the processor should have the `""` token where the images should be inserted.
- The processor has its own `apply_chat_template` method to convert chat messages to text that can then be passed as text to the processor. You can also get a vectorized output from `apply_chat_template`. See the examples below for more details on how to use it.
### Image cropping for high resolution images
The model supports cropping images into smaller patches when the image aspect ratio exceeds a certain value. By default the images are not cropped and only the base image is forwarded to the model. Users can set `do_pan_and_scan=True` to obtain several crops per image along with the base image to improve the quality in DocVQA or similar tasks requiring higher resolution images.
Pan and scan is an inference time optimization to handle images with skewed aspect ratios. When enabled, it improves performance on tasks related to document understanding, infographics, OCR, etc.
```python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("google/gemma-3-4b-it", padding_side="left")
url = "https://media.istockphoto.com/id/1192867753/photo/cow-in-berchida-beach-siniscola.jpg?s=612x612&w=0&k=20&c=v0hjjniwsMNfJSuKWZuIn8pssmD5h5bSN1peBd1CmH4="
messages = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are a helpful assistant."}
]
},
{
"role": "user", "content": [
{"type": "image", "url": url},
{"type": "text", "text": "What is shown in this image?"},
]
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
do_pan_and_scan=True,
).to(model.device)
```
## Usage Example
### Single-image Inference
```python
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
model_id = "google/gemma-3-4b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(model_id, device_map="auto")
processor = AutoProcessor.from_pretrained(model_id, padding_side="left")
url = "https://media.istockphoto.com/id/1192867753/photo/cow-in-berchida-beach-siniscola.jpg?s=612x612&w=0&k=20&c=v0hjjniwsMNfJSuKWZuIn8pssmD5h5bSN1peBd1CmH4="
messages = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are a helpful assistant."}
]
},
{
"role": "user", "content": [
{"type": "image", "url": url},
{"type": "text", "text": "What is shown in this image?"},
]
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
).to(model.device)
output = model.generate(**inputs, max_new_tokens=50)
print(processor.decode(output[0], skip_special_tokens=True)[inputs.input_ids.shape[1]: ])
```
### Multi-image Inference
```python
from transformers import AutoTokenizer, Gemma3ForCausalLM
model_id = "google/gemma-3-4b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(model_id, device_map="auto")
processor = AutoProcessor.from_pretrained(model_id, padding_side="left")
url_cow = "https://media.istockphoto.com/id/1192867753/photo/cow-in-berchida-beach-siniscola.jpg?s=612x612&w=0&k=20&c=v0hjjniwsMNfJSuKWZuIn8pssmD5h5bSN1peBd1CmH4="
url_stop = "https://www.ilankelman.org/stopsigns/australia.jpg"
messages = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are a helpful assistant."}
]
},
{
"role": "user", "content": [
{"type": "image", "url": url_cow},
{"type": "image", "url": url_stop},
{"type": "text", "text": "Are these two images identical?"},
]
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
return_tensors="pt",
add_generation_prompt=True,
).to(model.device)
output = model.generate(**inputs, max_new_tokens=50)
print(processor.decode(output[0], skip_special_tokens=True)[inputs.input_ids.shape[1]: ])
```
### Text-only inference
```python
from transformers import AutoTokenizer, Gemma3ForCausalLM
model_id = "google/gemma-3-1b-it"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = Gemma3ForCausalLM.from_pretrained(model_id, device_map="auto")
input_ids = tokenizer("Write me a poem about Machine Learning.", return_tensors="pt").to(model.device)
outputs = model.generate(**input_ids, max_new_tokens=100)
text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(text)
```
Aya Vision (Based on v4.49.0) (2025-03-04)
A new model is added to transformers: Aya Vision.
It is added on top of the v4.49.0 release, and can be installed from the following tag: v4.49.0-AyaVision.
In order to install this version, please install with the following command:
```
pip install git+https://github.com/huggingface/transformers@v4.49.0-AyaVision
```
If fixes are needed, they will be applied to this release; this installation may therefore be considered as stable and improving.
# Aya Vision

The model is detailed in the following [blog post](https://huggingface.co/blog/aya-vision).
## Overview
The Aya Vision 8B and 32B models is a state-of-the-art multilingual multimodal models developed by Cohere For AI. They build on the Aya Expanse recipe to handle both visual and textual information without compromising on the strong multilingual textual performance of the original model.
Aya Vision 8B combines the `Siglip2-so400-384-14` vision encoder with the Cohere CommandR-7B language model further post-trained with the Aya Expanse recipe, creating a powerful vision-language model capable of understanding images and generating text across 23 languages. Whereas, Aya Vision 32B uses Aya Expanse 32B as the language model.
Key features of Aya Vision include:
- Multimodal capabilities in 23 languages
- Strong text-only multilingual capabilities inherited from CommandR-7B post-trained with the Aya Expanse recipe and Aya Expanse 32B
- High-quality visual understanding using the Siglip2-so400-384-14 vision encoder
- Seamless integration of visual and textual information in 23 languages.
## Usage Example
Here's an example usage of the Aya Vision model.
```py
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
model_id = "CohereForAI/aya-vision-32b"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForImageTextToText.from_pretrained(
model_id, device_map="auto", torch_dtype=torch.float16
)
# Format message with the aya-vision chat template
messages = [
{"role": "user",
"content": [
{"type": "image", "url": "https://pbs.twimg.com/media/Fx7YvfQWYAIp6rZ?format=jpg&name=medium"},
{"type": "text", "text": "चित्र में लिखा पाठ क्या कहता है?"},
]},
]
inputs = processor.apply_chat_template(
messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt"
).to(model.device)
gen_tokens = model.generate(
**inputs,
max_new_tokens=300,
do_sample=True,
temperature=0.3,
)
print(processor.tokenizer.decode(gen_tokens[0][inputs.input_ids.shape[1]:], skip_special_tokens=True))
```
SigLIP-2 (Based on v4.49.0) (2025-02-21)
A new model is added to transformers: SigLIP-2.
It is added on top of the v4.49.0 release, and can be installed from the following tag: `v4.49.0-SigLIP-2`.
In order to install this version, please install with the following command:
```
pip install git+https://github.com/huggingface/transformers@v4.49.0-SigLIP-2
```
If fixes are needed, they will be applied to this release; this installation may therefore be considered as stable and improving.
# SigLIP2

The paper page for the model is available [here](https://huggingface.co/papers/2502.14786).
It is detailed in the following [blog post](https://huggingface.co/blog/siglip2).
The models and demos using the model are available in the following [collection](https://huggingface.co/collections/google/siglip2-67b5dcef38c175486e240107).
## Overview
The SigLIP2 model was proposed in [SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features](https://huggingface.co/papers/2502.14786) by Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin,
Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen,
Andreas Steiner and Xiaohua Zhai.
The model comes in two variants
1) FixRes - model works with fixed resolution images (backward compatible with SigLIP v1)
2) NaFlex - model works with variable image aspect ratios and resolutions (SigLIP2 in `transformers`)
The abstract from the paper is the following:
*We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success
of the original SigLIP. In this second iteration, we extend the original image-text training objective with
several prior, independently developed techniques into a unified recipe—this includes decoder-based
pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With
these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities,
including zero-shot classification (best SigLIP 2 ViT-g/16 achieves 85.0% ImageNet zero-shot
accuracy), image-text retrieval, and transfer performance when extracting visual representations for
Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements
on localization and dense prediction tasks. We also train variants which support multiple resolutions
and preserve the input’s native aspect ratio. Finally, we train on a more diverse data-mixture that
includes de-biasing techniques, leading to much better multilingual understanding and improved fair-
ness. To provide users with the ability to trade-off inference cost with performance, we release model
checkpoints at four sizes (ViT-B/86M, L/303M, So400m/400M, and g/1B).*
## Usage tips
- Usage of SigLIP2 is similar to [SigLIP](siglip) and [CLIP](clip). The main difference from CLIP is the training loss, which does not require a global view of all the pairwise similarities of images and texts within a batch. One needs to apply the sigmoid activation function to the logits, rather than the softmax.
- Training is supported but does not use `torch.distributed` utilities which may limit the scalability of batch size. However, DDP and FDSP works on single-node multi-gpu setup.
- When using the standalone [`GemmaTokenizerFast`] make sure to pass `padding="max_length"` and `max_length=64` as that's how the model was trained.
- Model was trained with *lowercased* text, make sure you make the same preprocessing for your text labels.
- To get the same results as the pipeline, a prompt template of "this is a photo of {label}" should be used.
- The NaFlex variant supports processing images at higher resolutions by adjusting the `max_num_patches` parameter in the `Processor`. The default value is `max_num_patches=256`. Increasing `max_num_patches` to 1024 (4x) will approximately double processed image height and width, while preserving the aspect ratio.
 This model was contributed by [qubvel](https://huggingface.co/qubvel-hf).
The original code can be found [here](https://github.com/google-research/big_vision/tree/main).
## Usage example
There are 2 main ways to use SigLIP2: either using the pipeline API, which abstracts away all the complexity for you, or by using the `Siglip2Model` class yourself.
### FixRes variant
**Pipeline API**
The pipeline allows to use the model in a few lines of code:
```python
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # load pipe
>>> image_classifier = pipeline(
... task="zero-shot-image-classification",
... model="google/siglip2-base-patch16-224",
... )
>>> # load image
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # inference
>>> candidate_labels = ["2 cats", "a plane", "a remote"]
>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
>>> print(outputs)
[{'score': 0.1499, 'label': '2 cats'}, {'score': 0.0008, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
```
**Using the model yourself**
If you want to do the pre- and postprocessing yourself, here's how to do that:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> candidate_labels = ["2 cats", "2 dogs"]
# follows the pipeline prompt template to get same results
>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
# IMPORTANT: we pass `padding=max_length` and `max_length=64` since the model was trained with this
>>> inputs = processor(text=texts, images=image, padding="max_length", max_length=64, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
15.0% that image 0 is '2 cats'
```
### NaFlex variant
NaFlex combines ideas from FlexiViT, i.e. supporting multiple, predefined sequence lengths
with a single ViT model, and NaViT, namely processing images at their native aspect ratio.
This enables processing different types of images at appropriate resolution, e.g. using a
larger resolution to process document images, while at the same time minimizing the impact
of aspect ratio distortion on certain inference tasks, e.g. on OCR.
Given a patch size and target sequence length, NaFlex preprocesses the data by first resizing
the input image such that the height and width after resizing are multiples of the patch size,
while
1. keeping the aspect ratio distortion as small as possible
2. producing a sequence length of at most the desired target sequence length (`max_num_patches`)
The resulting distortion in width and height is at most `(patch_size - 1) / width` and
`(patch_size - 1) / height`, respectively, which tends to be small for common resolutions and aspect ratios.
After resizing, the image is split into a sequence of patches, and a mask with padding information is added.
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-naflex")
>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-naflex")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> candidate_labels = ["2 cats", "2 dogs"]
# follows the pipeline prompt template to get same results
>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
# default value for `max_num_patches` is 256, but you can increase resulted image resolution providing
# higher values e.g. `max_num_patches=512`
>>> inputs = processor(text=texts, images=image, max_num_patches=256, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
21.1% that image 0 is '2 cats'
```
This model was contributed by [qubvel](https://huggingface.co/qubvel-hf).
The original code can be found [here](https://github.com/google-research/big_vision/tree/main).
## Usage example
There are 2 main ways to use SigLIP2: either using the pipeline API, which abstracts away all the complexity for you, or by using the `Siglip2Model` class yourself.
### FixRes variant
**Pipeline API**
The pipeline allows to use the model in a few lines of code:
```python
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # load pipe
>>> image_classifier = pipeline(
... task="zero-shot-image-classification",
... model="google/siglip2-base-patch16-224",
... )
>>> # load image
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # inference
>>> candidate_labels = ["2 cats", "a plane", "a remote"]
>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
>>> print(outputs)
[{'score': 0.1499, 'label': '2 cats'}, {'score': 0.0008, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
```
**Using the model yourself**
If you want to do the pre- and postprocessing yourself, here's how to do that:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> candidate_labels = ["2 cats", "2 dogs"]
# follows the pipeline prompt template to get same results
>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
# IMPORTANT: we pass `padding=max_length` and `max_length=64` since the model was trained with this
>>> inputs = processor(text=texts, images=image, padding="max_length", max_length=64, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
15.0% that image 0 is '2 cats'
```
### NaFlex variant
NaFlex combines ideas from FlexiViT, i.e. supporting multiple, predefined sequence lengths
with a single ViT model, and NaViT, namely processing images at their native aspect ratio.
This enables processing different types of images at appropriate resolution, e.g. using a
larger resolution to process document images, while at the same time minimizing the impact
of aspect ratio distortion on certain inference tasks, e.g. on OCR.
Given a patch size and target sequence length, NaFlex preprocesses the data by first resizing
the input image such that the height and width after resizing are multiples of the patch size,
while
1. keeping the aspect ratio distortion as small as possible
2. producing a sequence length of at most the desired target sequence length (`max_num_patches`)
The resulting distortion in width and height is at most `(patch_size - 1) / width` and
`(patch_size - 1) / height`, respectively, which tends to be small for common resolutions and aspect ratios.
After resizing, the image is split into a sequence of patches, and a mask with padding information is added.
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-naflex")
>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-naflex")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> candidate_labels = ["2 cats", "2 dogs"]
# follows the pipeline prompt template to get same results
>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
# default value for `max_num_patches` is 256, but you can increase resulted image resolution providing
# higher values e.g. `max_num_patches=512`
>>> inputs = processor(text=texts, images=image, max_num_patches=256, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
21.1% that image 0 is '2 cats'
```
SmolVLM-2 (Based on v4.49.0) (2025-02-20)
A new model is added to `transformers`: SmolVLM-2.
It is added on top of the v4.49.0 release, and can be installed from the following tag: `v4.49.0-SmolVLM-2`.
In order to install this version, please install with the following command:
```bash
pip install git+https://github.com/huggingface/transformers@v4.49.0-SmolVLM-2
```
If fixes are needed, they will be applied to this release; this installation may therefore be considered as stable and improving.
## SmolVLM-2

SmolVLM-2 is detailed in the following [blog post](https://huggingface.co/blog/smolvlm2).
The models and demos using the model are available in the following [collection](https://huggingface.co/collections/HuggingFaceTB/smolvlm2-smallest-video-lm-ever-67ab6b5e84bf8aaa60cb17c7).
## Overview
SmolVLM2 is an adaptation of the Idefics3 model with two main differences:
- It uses SmolLM2 for the text model.
- It supports multi-image and video inputs
## Usage tips
Input images are processed either by upsampling (if resizing is enabled) or at their original resolution. The resizing behavior depends on two parameters: do_resize and size.
Videos should not be upsampled.
If `do_resize` is set to `True`, the model resizes images so that the longest edge is 4*512 pixels by default.
The default resizing behavior can be customized by passing a dictionary to the `size` parameter. For example, `{"longest_edge": 4 * 512}` is the default, but you can change it to a different value if needed.
Here’s how to control resizing and set a custom size:
```python
image_processor = SmolVLMImageProcessor(do_resize=True, size={"longest_edge": 2 * 512}, max_image_size=512)
```
Additionally, the `max_image_size` parameter, which controls the size of each square patch the image is decomposed into, is set to 512 by default but can be adjusted as needed. After resizing (if applicable), the image processor decomposes the images into square patches based on the `max_image_size` parameter.
This model was contributed by [orrzohar](https://huggingface.co/orrzohar).
## Usage example
### Single Media inference
The model can accept both images and videos as input, but you should use only one of the modalities at a time. Here's an example code for that.
```python
import torch
from transformers import AutoProcessor, AutoModelForImageTextToText
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM2-256M-Video-Instruct")
model = AutoModelForImageTextToText.from_pretrained(
"HuggingFaceTB/SmolVLM2-256M-Video-Instruct",
torch_dtype=torch.bfloat16,
device_map="cuda"
)
conversation = [
{
"role": "user",
"content":[
{"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
{"type": "text", "text": "Describe this image."}
]
}
]
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device, dtype=torch.bfloat16)
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_texts = processor.batch_decode(output_ids, skip_special_tokens=True)
print(generated_texts)
# Video
conversation = [
{
"role": "user",
"content": [
{"type": "video", "path": "/path/to/video.mp4"},
{"type": "text", "text": "Describe this video in detail"}
]
},
]
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device, dtype=torch.bfloat16)
generated_ids = model.generate(**inputs, do_sample=False, max_new_tokens=100)
generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts[0])
```
v4.49.0: Helium, Qwen2.5-VL, SuperGlue, Granite Vision, Zamba2, GOT-OCR 2.0, DAB-DETR, Depth Pro, RT-DETRv2, GPTQModel (2025-02-17)
# New models
## Helium
Helium-1 preview is a lightweight language model with 2B parameters, targeting edge and mobile devices. It supports the following languages: English, French, German, Italian, Portuguese, Spanish.
 * Add-helium by @ArthurZucker in #35669
## Qwen2.5-VL
The [Qwen2.5-VL](https://qwenlm.github.io/blog/qwen2_5-vl/) model is an update to [Qwen2-VL](https://arxiv.org/abs/2409.12191) from Qwen team, Alibaba Group.
The abstract from this update is the following:
Qwen2.5-VL marks a major step forward from Qwen2-VL, built upon the latest Qwen2.5 LLM. We’ve accelerated training and testing through the strategic implementation of window attention within the ViT. The ViT architecture itself has been refined with SwiGLU and RMSNorm, aligning it more closely with the LLM’s structure. A key innovation is the expansion of native dynamic resolution to encompass the temporal dimension, in addition to spatial aspects. Furthermore, we’ve upgraded MRoPE, incorporating absolute time alignment on the time axis to allow the model to effectively capture temporal dynamics, regardless of frame rate, leading to superior video understanding.

* add qwen2.5vl by @ShuaiBai623 in #35569
## SuperGlue
The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://arxiv.org/abs/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
This model consists of matching two sets of interest points detected in an image. Paired with the [SuperPoint model](https://huggingface.co/magic-leap-community/superpoint), it can be used to match two images and estimate the pose between them. This model is useful for tasks such as image matching, homography estimation, etc.
* Add-helium by @ArthurZucker in #35669
## Qwen2.5-VL
The [Qwen2.5-VL](https://qwenlm.github.io/blog/qwen2_5-vl/) model is an update to [Qwen2-VL](https://arxiv.org/abs/2409.12191) from Qwen team, Alibaba Group.
The abstract from this update is the following:
Qwen2.5-VL marks a major step forward from Qwen2-VL, built upon the latest Qwen2.5 LLM. We’ve accelerated training and testing through the strategic implementation of window attention within the ViT. The ViT architecture itself has been refined with SwiGLU and RMSNorm, aligning it more closely with the LLM’s structure. A key innovation is the expansion of native dynamic resolution to encompass the temporal dimension, in addition to spatial aspects. Furthermore, we’ve upgraded MRoPE, incorporating absolute time alignment on the time axis to allow the model to effectively capture temporal dynamics, regardless of frame rate, leading to superior video understanding.

* add qwen2.5vl by @ShuaiBai623 in #35569
## SuperGlue
The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://arxiv.org/abs/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
This model consists of matching two sets of interest points detected in an image. Paired with the [SuperPoint model](https://huggingface.co/magic-leap-community/superpoint), it can be used to match two images and estimate the pose between them. This model is useful for tasks such as image matching, homography estimation, etc.
 * Add SuperGlue model by @sbucaille in #29886
## Granite Vision Support
The Granite Vision model is a variant of [LLaVA-NeXT](https://huggingface.co/docs/transformers/main/en/model_doc/llava_next), leveraging a [Granite](https://huggingface.co/docs/transformers/main/en/model_doc/granite) language model alongside a [SigLIP](https://huggingface.co/docs/transformers/main/en/model_doc/SigLIP) visual encoder. It utilizes multiple concatenated vision hidden states as its image features, similar to [VipLlava](https://huggingface.co/docs/transformers/main/en/model_doc/vipllava). It also uses a larger set of image grid pinpoints than the original LlaVa-NeXT models to support additional aspect ratios.
* Granite Vision Support by @alex-jw-brooks in #35579
## Zamba2
Zamba2 is a large language model (LLM) trained by Zyphra, and made available under an Apache 2.0 license.
Zamba2-1.2B, Zamba2-2.7B and Zamba2-7B are hybrid models combining state-space models (Specifically [Mamba](https://github.com/state-spaces/mamba)) and transformer, and were trained using next-token prediction. Zamba2 uses shared transformer layers after every 6 mamba blocks. It uses the [Mistral v0.1 tokenizer](https://huggingface.co/mistralai/Mistral-7B-v0.1). We came to this architecture after a series of ablations at small scales. Zamba2-1.2B, Zamba2-2.7B and Zamba2-7B were pre-trained on 2T and 3T tokens, respectively.

* Add Zamba2 by @pglorio in #34517
## GOT-OCR 2.0
GOT-OCR2 works on a wide range of tasks, including plain document OCR, scene text OCR, formatted document OCR, and even OCR for tables, charts, mathematical formulas, geometric shapes, molecular formulas and sheet music. While this implementation of the model will only output plain text, the outputs can be further processed to render the desired format, with packages like pdftex, mathpix, matplotlib, tikz, verovio or pyecharts. The model can also be used for interactive OCR, where the user can specify the region to be recognized by providing the coordinates or the color of the region’s bounding box.

* Add GOT-OCR 2.0 to Transformers by @yonigozlan in #34721
## DAB-DETR
DAB-DETR is an enhanced variant of Conditional DETR. It utilizes dynamically updated anchor boxes to provide both a reference query point (x, y) and a reference anchor size (w, h), improving cross-attention computation. This new approach achieves 45.7% AP when trained for 50 epochs with a single ResNet-50 model as the backbone.

* Add DAB-DETR for object detection by @conditionedstimulus in #30803
## Depth PRO
DepthPro is a foundation model for zero-shot metric monocular depth estimation, designed to generate high-resolution depth maps with remarkable sharpness and fine-grained details. It employs a multi-scale Vision Transformer (ViT)-based architecture, where images are downsampled, divided into patches, and processed using a shared Dinov2 encoder. The extracted patch-level features are merged, upsampled, and refined using a DPT-like fusion stage, enabling precise depth estimation.

* Add Apple's Depth-Pro for depth estimation by @geetu040 in #34583
## RT-DETRv2
An improved **Real-Time** DEtection TRansformer (RT-DETR). RT-DETRv2 refines RT-DETR by introducing selective multi-scale feature extraction, a discrete sampling operator for broader deployment compatibility. These improvements yield a 0.3 to 1.4 increase in mAP metrics on the COCO dataset, all while maintaining the same parameter count and frames-per-second (FPS) performance.

* Adding RTDETRv2 by @jadechoghari in #34773
## Transformers-CLI
Transformers' CLI welcomes a new command: `chat`. This command starts a conversation with the model of your choosing directly in your terminal.
This feature exists in TRL and has been migrated to `transformers` for easier usage.

* [Chat] Add Chat from TRL 🐈 by @gante in #35714
## Processor Standardization
An ongoing work is to standardize the image processors so that their API is equivalent. Additionally, the processors are given a fast variant so that they are never blockers in the image processing pipelines.
In this release, several processors have been standardized and have seen their fast version be contributed.
* OwlViT/Owlv2 post processing standardization by @qubvel in #34929
* OmDet Turbo processor standardization by @qubvel in #34937
* Grounding DINO Processor standardization by @qubvel in #34853
* Refactoring of ImageProcessorFast by @yonigozlan in #35069
* add Qwen2-VL image processor fast by @yonigozlan in #35733
* Remove Multi-threaded image conversion for fast image processors by @yonigozlan in #36105
## Breaking changes
### DPT segmentation maps
DPT image processors did not support `segmentation_maps`, instead only requiring `images`. This has been fixed.
This adds an argument to the `preprocess` method, therefore users using arguments as positional arguments with that method may see changed behavior. We recommend using keyword arguments for such methods so as to not be bothered by the addition of new features.
* 🔴 🔴 🔴 Added `segmentation maps` support for DPT image processor by @simonreise in #34345
### Image classification pipeline and single vs multi-label
The `problem_type` in the config.json file was read incorrectly by the pipeline, which mapped single-label to multi-label losses, and vice-versa. This has been fixed.
* 🚨🚨🚨 image-classification pipeline single-label and multi-label prob type squashing fns (sigmoid vs softmax) are backwards by @rwightman in #35848
### Fixing the LayerNorm beta/gamma renames
The description of the pull request is the easiest way to understand the problem, why it exists, and how it is solved; please read the description below:
* 🚨🚨🚨 An attempt to fix #29554. Include 'LayerNorm.' in gamma/beta rename scope, optimize string search. by @rwightman in #35615
### VLM cleanup
The `ignore_index` property of the llava configuration has been removed as it was not serving a purpose.
* 🔴 VLM: compile compatibility by @zucchini-nlp in #35724
## Quantization
Quantization has received several improvements and fixes, including the contribution of FP8 quantization and the HIGGS quantization interface.
Additionally, we're replacing the AutoGPTQ implementaiton with GPTQModel from ModelCloud (see repository [here)](https://github.com/ModelCloud/GPTQModel?tab=readme-ov-file)).
GPTQModel originated as major refractor of AutoGPTQ but is now a full-stand-in replacement with cleaner api, up-to-date model support, faster inference, higher quality quants.
* Enable gptqmodel by @ jiqing-feng in #35012
* Split and clean up GGUF quantization tests by @Isotr0py in #35502
* Display warning for unknown quants config instead of an error by @SunMarc in #35963
* Adding FP8 Quantization to transformers by @MekkCyber in #36026
* New HIGGS quantization interfaces, JIT kernel compilation support. by @BlackSamorez in #36148
## Generate
* [generate] revert change in Aria: the maximum cache length must match `max_length` by @gante in #36120
* 🧹 remove `generate`-related objects and methods scheduled for removal in v4.48 by @gante in #35677
* [generate] can instantiate `GenerationConfig(cache_implementation="static")` by @gante in #35679
* [generate] return Cache object even if passed in a legacy format by @gante in #35673
* [generate] update docstring of `SequenceBiasLogitsProcessor` by @gante in #35699
* Test: generate with `torch.compile(model.forward)` as a fast test by @gante in #34544
* [generate] move max time tests by @gante in #35962
* [generate] shape checks in tests compatible with fixed-length caches (+ some minor fixes) by @gante in #35993
## Pipelines
Pipelines have received several bug fixes and improvements which are detailed below.
* Stop mutating input dicts in audio classification pipeline by @Rocketknight1 in #35754
* fix document qa bf16 pipeline by @jiqing-feng in #35456
* fix low-precision audio classification pipeline by @jiqing-feng in #35435
* [pipeline] missing import regarding assisted generation by @gante in #35752
* Output dicts support in text generation pipeline by @jonasrohw in #35092
* Fix Audio Classification Pipeline top_k Documentation Mismatch and Bug #35736 by @sambhavnoobcoder in #35771
## Bugfixes and improvements
* Fix flaky `test_custom_4d_attention_mask` by @ydshieh in #35606
* Use inherit tempdir makers for tests + fix failing DS tests by @muellerzr in #35600
* Added error when sequence length is bigger than max_position_embeddings by @Taha1506 in #32156
* Let `EarlyStoppingCallback` not require `load_best_model_at_end` by @muellerzr in #35101
* Fix flaky `test_beam_search_low_memory` by @ydshieh in #35611
* Skip `MobileNetV1ModelTest::test_batching_equivalence` for now by @ydshieh in #35614
* Update codeowners with individual model owners by @Rocketknight1 in #35595
* Fix device in rope module when using dynamic updates by @Cyrilvallez in #35608
* Fix whisper compile by @jiqing-feng in #35413
* Removed some duplicated code by @Sai-Suraj-27 in #35637
* [`Phi`] bias should be True by @ArthurZucker in #35650
* Enable different torch dtype in sub models by @zucchini-nlp in #34873
* [`Compile`] Only test compiling model forward pass by @ArthurZucker in #35658
* [tests] make cuda-only tests device-agnostic by @faaany in #35607
* [i18n-ar] Translated file : docs/source/ar/tasks/token_classification.md into Arabic by @AhmedAlmaghz in #35193
* Fix `zero_shot_image_classification` documentation guide link in SigLIP by @aretrace in #35671
* Fix : adding einops lib in the CI docker for some bitsandbytes tests by @MekkCyber in #35652
* Update torchao.md: use auto-compilation by @martin0258 in #35490
* Fix : HQQ config when hqq not available by @MekkCyber in #35655
* Fix expected output for ggml test by @MekkCyber in #35686
* Fix : add require_read_token for gemma2 gated model by @MekkCyber in #35687
* Enhanced Installation Section in README.md by @egojoseph in #35094
* Enhance DataCollatorForLanguageModeling with Configurable Token Replacement Probabilities by @mahdibaghbanzadeh in #35251
* Clean-up composite configs by @zucchini-nlp in #34603
* Add future import for Py < 3.10 by @Rocketknight1 in #35666
* Enable gptqmodel by @jiqing-feng in #35012
* Fix : Nemotron Processor in GGUF conversion by @MekkCyber in #35708
* Fix typo in /docs/source/ja/model_doc/decision_transformer.md URL by @hiroaki222 in #35705
* Replace deprecated batch_size with max_batch_size when using HybridCache by @mtreinik in #35498
* Fix: Falcon tie_word_embeddings in GGUF by @MekkCyber in #35715
* Fix condition when GA loss bug fix is not performed by @techkang in #35651
* Fix the bug that `Trainer` cannot correctly call `torch_jit_model_eval` by @Wanguy in #35722
* [generation] fix type hint by @gante in #35725
* Add proper jinja2 error by @Rocketknight1 in #35533
* Optimize ForCausalLMLoss by removing unnecessary contiguous() call to reduce memory overhead by @efsotr in #35646
* Modular: support for importing functions from any file by @Cyrilvallez in #35692
* Remove batch size argument warning when unjustified by @quintenroets in #35519
* [cache] add a test to confirm we can use cache at train time by @gante in #35709
* Remove `pt_to_tf` by @gante in #35672
* Added resource class configuration option for `check_circleci_user` job by @Sai-Suraj-27 in #32866
* Fix some tests by @Cyrilvallez in #35682
* Unable to use `MimiModel` with DeepSpeed ZeRO-3 by @anferico in #34735
* check is added for the report_to variable in TrainingArguments by @alpertunga-bile in #35403
* Added liger_kernel compatibility with `PeftModel` by @ambroser53 in #35680
* Restore is_torch_greater_or_equal_than for backward compatibility by @tlrmchlsmth in #35734
* Revert "Unable to use `MimiModel` with DeepSpeed ZeRO-3" by @eustlb in #35755
* ci: fix xpu skip condition for test_model_parallel_beam_search by @dvrogozh in #35742
* Use AMD CI workflow defined in hf-workflows by @ivarflakstad in #35058
* Fix CI for VLMs by @zucchini-nlp in #35690
* Security fix for `self-comment-ci.yml` by @ydshieh in #35548
* [ViTPose] Convert more checkpoints by @NielsRogge in #35638
* fix register_buffer in MimiEuclideanCodebook by @anferico in #35759
* remove code owners as it was generating too much noise BUT by @ArthurZucker in #35784
* Skip Falcon 7B GGML Test by @MekkCyber in #35783
* [fix] cannot import name 'Pop2PianoFeatureExtractor' from 'transformers' by @faaany in #35604
* transformers.image_transforms.normalize wrong types by @CalOmnie in #35773
* Patch moonshine by @eustlb in #35731
* Don't import torch.distributed when it's not available by @booxter in #35777
* Fix vits low-precision dtype by @jiqing-feng in #35418
* Tool calling: support more types by @aymeric-roucher in #35776
* Fixes, improvements to `timm` import behaviour by @rwightman in #35800
* modular_model_converter bugfix on assignments by @nikosanto13 in #35642
* Deterministic sorting in modular converter when adding new functions by @Cyrilvallez in #35795
* Fix "test_chat_template_dict" in video LLMs by @zucchini-nlp in #35660
* Update AMD Docker image by @ivarflakstad in #35804
* Add LlavaImageProcessor by @NielsRogge in #33191
* Byebye `test_batching_equivalence`'s flakiness by @ydshieh in #35729
* [Doc] Adding blog post to model doc for `TimmWrapper` by @ariG23498 in #35744
* add a new flax example for Bert model inference by @louie-tsai in #34794
* Support adamw_torch_8bit by @fzyzcjy in #34993
* Auto-add `timm` tag to timm-wrapper models. by @pcuenca in #35794
* Fix : BLOOM tie_word_embeddings in GGUF by @MekkCyber in #35812
* Fixed typo in autoawq version number in an error message for IPEX backend requirements. by @InfroLab in #35815
* Remove deprecated `get_cached_models` by @Wauplin in #35809
* Optimized set_initialized_submodules. by @LagPixelLOL in #35493
* [i18n-ar] Translated file: `docs/source/ar/tasks/masked_language_modeling.md` into Arabic by @AhmedAlmaghz in #35198
* move fastspeech to audio models by @eustlb in #35788
* Improve modular documentation by @Cyrilvallez in #35737
* [Mimi] update test expected values for t4 runners by @eustlb in #35696
* Remove old `benchmark` code by @gante in #35730
* Remove pyav pin to allow python 3.11 to be used by @CalOmnie in #35823
* Another security patch for `self-comment-ci.yml` by @ydshieh in #35816
* Init cache on meta device by @zucchini-nlp in #35164
* Hotfix: missing `working-directory` in `self-comment-ci.yml` by @ydshieh in #35833
* [gpt2] fix generation tests by @gante in #35822
* Fix : Nemotron tokenizer for GGUF format by @MekkCyber in #35836
* Fix `head_dim` in config extracted from Gemma2 GGUF model by @Isotr0py in #35818
* [chat] docs fix by @gante in #35840
* Fix compatibility issues when using auto_gptq with these older versions by @LRL-ModelCloud in #35830
* Add PyTorch version check for FA backend on AMD GPUs by @mht-sharma in #35813
* Fix NoneType type as it requires py>=3.10 by @SunMarc in #35843
* [ `tests`] remove some flash attention class tests by @ArthurZucker in #35817
* [Backend support] Allow `num_logits_to_keep` as Tensor + add flag by @Cyrilvallez in #35757
* Fix GA loss for Deepspeed by @timjeffrey10 in #35808
* Fix uploading processors/tokenizers to WandB on train end by @jack89roberts in #35701
* Fix more CI tests by @ArthurZucker in #35661
* [DOC] Fix contamination and missing paragraph in translation by @Yosshi999 in #35851
* Fix typo by @SilverSoldier in #35854
* fix apply_chat_template() padding choice by @baoyf4244 in #35828
* Fix `test_pipelines_video_classification` that was always failing by @CalOmnie in #35842
* Fix Llava-NeXT / Llava-NeXT Video / Llava-OneVision's token unpadding mismatch by @sheryc in #35779
* use torch.testing.assertclose instead to get more details about error in cis by @ArthurZucker in #35659
* add xpu device check in device_placement by @faaany in #35865
* Add `Rocketknight1` to `self-comment-ci.yml` by @ydshieh in #35881
* [doctest] Fixes by @stevhliu in #35863
* Fix fast image processor warnings in object detection examples by @sugendran in #35892
* Update deepspeed amd image by @ivarflakstad in #35906
* Fix typing in audio_utils.chroma_filter_bank by @CalOmnie in #35888
* [docs] uv install by @stevhliu in #35821
* Fix the config class comparison for remote code models by @Rocketknight1 in #35592
* Close Zamba2Config code block by @Rocketknight1 in #35914
* [docs] Fix Zamba2 by @stevhliu in #35916
* Remove `_supports_static_cache = True` for some model classes by @ydshieh in #34975
* Use rocm6.2 for AMD images by @ivarflakstad in #35930
* Add default TP plan for all models with backend support by @Cyrilvallez in #35870
* Fix: loading DBRX back from saved path by @zucchini-nlp in #35728
* Fix mask slicing for models with HybridCache by @Cyrilvallez in #35681
* Qwen-2-5-VL: fix CI by @zucchini-nlp in #35935
* Fix TP initialization by @Cyrilvallez in #35860
* fix(FA): QKV not being casted to target_dtype for FA with dpo lora by @NanoCode012 in #35834
* Remove INC notebook reference in documentation by @echarlaix in #35936
* use torch constraints to check if covariance is positive definite during mean resizing. by @abuelnasr0 in #35693
* fix `test_generated_length_assisted_generation` by @keyboardAnt in #34935
* Update `unwrap_and_save_reload_schedule` to use `weights_only=False` by @ydshieh in #35952
* Update `squad_convert_example_to_features` to work with numpy v2 by @ydshieh in #35955
* Fix flaky `test_assisted_decoding_matches_greedy_search` by @ydshieh in #35951
* Trainer Refactor: Part 1 by @muellerzr in #35567
* update docker file `transformers-pytorch-deepspeed-latest-gpu` by @ydshieh in #35940
* [tests] further fix `Tester object has no attribute '_testMethodName'` by @faaany in #35781
* Update README.md by @BlessedTatonka in #35958
* fix iterator overflow when gradient accumulation is 1 by @winglian in #35960
* Fix is_causal being a tensor by @IlyasMoutawwakil in #35791
* [bart] minor test fixes by @gante in #35965
* Pixtral: vectorize patch embeddings and enable tests by @zucchini-nlp in #35122
* Whisper: fix static cache CI by @zucchini-nlp in #35852
* Less flaky for `TimmBackboneModelTest::test_batching_equivalence` by @ydshieh in #35971
* Support batching for UsefulSensors Moonshine by @njeffrie in #35922
* not to use A100 for `benchmark.yml` by @ydshieh in #35974
* Handle empty change indices in SAM's mask to rle conversion by @MSt-10 in #35665
* Add support for nested images to LLava and VipLLava by @yonigozlan in #35558
* [Moonshine] compute head_dim_padding at init by @eustlb in #35984
* [Moshi] disable automatic compilation if the model can't compile by @gante in #35992
* use torch 2.6 for daily CI by @ydshieh in #35985
* Update-tp test by @ArthurZucker in #35844
* Add mean_resizing for every VLMs' resizing_token_embeddings() by @YenFuLin in #35717
* Update Granite Vision Model Path / Tests by @alex-jw-brooks in #35998
* Qwen2-VL: fix rope delta calculation by @zucchini-nlp in #36013
* Fix custom kernel for DeformableDetr, RT-Detr, GroindingDINO, OmDet-Turbo in Pytorch 2.6.0 by @qubvel in #35979
* apply_chat_template: consistent behaviour for return_assistant_tokens_mask=True return_tensors=True by @mrsndmn in #35582
* layernorm_decay_fix by @Ryoo72 in #35927
* Update Mistral converter by @Cyrilvallez in #35967
* Refactor (and fix) gpt_neox by @Cyrilvallez in #35610
* Fix device mismatch error in Whisper model during feature extraction by @thedebugger in #35866
* Fix RMSNormGated in Zamba2 by @pglorio in #35943
* Commont bot CI for other jobs (`generation` / `quantization`) by @ydshieh in #35341
* Hotfix for `self-comment-ci.yml` by @ydshieh in #36030
* feat(ci): ignore trufflehog unverified results by @McPatate in #36031
* CircleCI with python 3.9 by @ydshieh in #36027
* Update tests regarding attention types after #35235 by @ydshieh in #36024
* Fix Gemma2 synced multi-GPU generation by @ManukyanD in #35232
* Fix synced multi-GPU generation with LLMs and VLMs by @ManukyanD in #35893
* Add XPU type for work-around -inf mask causing sdpa NaN issue in modeling files by @Liangliang-Ma in #35647
* add support for empty list as input to create_model_card by @ROZBEH in #36042
* DeepSpeed github repo move sync by @stas00 in #36021
* [docs] no hard coding cuda as bnb has multi-backend support by @faaany in #35867
* [docs] fix bugs in the bitsandbytes documentation by @faaany in #35868
* [docs] no hard-coding cuda by @faaany in #36043
* Fix how we compute the final non-padding token for ForSequenceClassification models by @Rocketknight1 in #35911
* Add `Qwen2VLImageProcessorFast` into `Qwen2VLProcessor` by @yeliudev in #35987
* Iterative generation using Input embeds and `past_key_values` by @yaswanth19 in #35890
* Fix usage of unpad_input function by @pavelgein in #35925
* Fix repo consistency by @ydshieh in #36063
* Update `test_flash_attn_2_can_dispatch_composite_models` by @ydshieh in #36050
* Paligemma: fix generation with Gemma2 by @zucchini-nlp in #36044
* Save checkpoint to temporary directory to handle partial saves during failures by @SilverSoldier in #35580
* Nail in edge case of torch dtype being overriden permantly in the case of an error by @muellerzr in #35845
* Fix words typos in ggml test. by @zhanluxianshen in #36060
* Fix model kwargs by @muellerzr in #35875
* Fix StopStringCriteria to handle tokens above len(tokenizer) by @Rocketknight1 in #35797
* [docs] fix outdated example code in `trainer.md` by @faaany in #36066
* Adding RT-DETRv2 for object detection by @jadechoghari in #34773
* Fix bug in apply_rotary_pos_emb_flashatt: in Qwen2-5-VL by @DeepWaved in #36065
* Move audio top_k tests to the right file and add slow decorator by @Rocketknight1 in #36072
* Fix OS err by @muellerzr in #36094
* [docs] fix model checkpoint name by @faaany in #36075
* [docs] fix typo by @faaany in #36080
* [docs] fix not-working example code in `perf_infer_gpu_one.md` by @faaany in #36087
* fix MllamaVisionAttention typehint by @kylesayrs in #35975
* Processors: allow tuples of images when checking by @zucchini-nlp in #36084
* Chat template: update for processor by @zucchini-nlp in #35953
* Paligemma: revert #36084 by @zucchini-nlp in #36113
* Support constant lr with cooldown by @LoserCheems in #35453
* Enable pytest live log and show warning logs on GitHub Actions CI runs by @ydshieh in #35912
* Refactor OPT model by @jiqing-feng in #36101
* Revert checkpoint tmp dir by @SunMarc in #36112
* [Bugfix] fix file name of docstring in utils/check_table.py by @kkscilife in #36108
* fix bnb warning by @SunMarc in #36116
* AutoformerForPrediction test add atol by @ivarflakstad in #36017
* Fix nighlty CIs: missing atols by @ArthurZucker in #35903
* Add common test for `torch.export` and fix some vision models by @qubvel in #35124
* fix: typos in documentation files by @maximevtush in #36122
* update awesome-transformers.md. by @zhanluxianshen in #36115
* Fix max size deprecated warning by @HichTala in #34998
* Fix CI issues by @molbap in #35662
* update tiktoken integ to use converted by @ArthurZucker in #36135
* Make `output_dir` Optional in `TrainingArguments` #27866 by @sambhavnoobcoder in #35735
* [docs] minor doc fix by @faaany in #36127
* [docs] update awq doc by @faaany in #36079
* Add pipeline parallel plan to `PretrainedConfig` and `PreTrainedModel` by @hmellor in #36091
* add RAdamScheduleFree optimizer by @nhamanasu in #35313
* added warning to Trainer when label_names is not specified for PeftModel by @MilkClouds in #32085
* Whisper: remove redundant assisted generation tests by @gante in #34814
* Add utility for Reload Transformers imports cache for development workflow #35508 by @sambhavnoobcoder in #35858
* VLM: enable skipped tests by @zucchini-nlp in #35746
* [commands] remove deprecated/inoperational commands by @gante in #35718
* Fix Gradient Checkpointing for Deberta & Deberta-V2 using PEFT / Adapters by @lenglaender in #35898
* 🚨 Remove cache migration script by @Wauplin in #35810
* multi-gpu: fix tensor device placements for various models by @dvrogozh in #35763
* Optim: APOLLO optimizer integration by @zhuhanqing in #36062
* Fix multi gpu loss sync condition, add doc and test by @techkang in #35743
* adding option to save/reload scaler by @hsilva664 in #34932
* Update doc re list of models supporting TP by @kwen2501 in #35864
* Add more rigerous non-slow grad accum tests by @muellerzr in #35668
* Fix test fetcher by @ydshieh in #36129
* skip `test_initialization` for `VitPoseBackboneModelTest` for now by @ydshieh in #36154
* Add git LFS to AMD docker image by @ivarflakstad in #36016
* Mllama fsdp by @blbadger in #36000
* Fix PaliGemma Pad Token Masking During Training #35855 by @sambhavnoobcoder in #35859
* Add reminder config to issue template and print DS version in env by @Ben-Schneider-code in #35156
* Fix Gemma2 dtype issue when storing weights in float16 precision by @Nerogar in #35398
* Replace deprecated update_repo_visibility by @Wauplin in #35970
* Fix tests for vision models by @qubvel in #35654
* qwen2.5vl: fix bugs when using flash2+bf16 or num_return_sequences>1 by @gewenbin0992 in #36083
* docs: fix return type annotation of `get_default_model_revision` by @MarcoGorelli in #35982
* Fix PretrainedTokenizerFast check => Fix PretrainedTokenizerFast Save by @CL-ModelCloud in #35835
* Move `DataCollatorForMultipleChoice` from the docs to the package by @bauwenst in #34763
* Helium documentation fixes by @LysandreJik in #36170
* Remove loading custom kernel for RT-DETRv2 by @qubvel in #36098
* [Modular] skip modular checks based on diff by @gante in #36130
* Fix red CI by @ArthurZucker in #36174
* Fix : fix doc fp8 by @MekkCyber in #36173
* Efficient Inference Kernel for SpQR by @elvircrn in #34976
* fix training issues by @ArthurZucker in #36158
* add disable compile option by @ArthurZucker in #36161
* CI: avoid human error, automatically infer generative models by @gante in #33212
* Use tqdm auto by @SmartManoj in #35726
* Optimize Qwen2VL vision model by precomputing cos/sin embeds before ViT blocks by @li-plus in #35837
* Make `check_repository_consistency` run faster by MP by @ydshieh in #36175
* Fix the key name for _load_rng_state under torch.cuda by @wizyoung in #36138
* Follow up to SpQR integration by @MekkCyber in #36176
* Fix a mistake in #36175 by @ydshieh in #36179
* Fix make_batched_videos and add tests by @yonigozlan in #36143
* Uniformize OwlViT and Owlv2 processors by @yonigozlan in #35700
* Add support for partial rotary embeddings in Phi3 model by @garg-amit in #35947
* CI: fix `test-save-trainer` by @zucchini-nlp in #36191
* Chat template docs by @zucchini-nlp in #36163
* Add ImageProcessorFast to Qwen2.5-VL processor by @Isotr0py in #36164
* Prepare processors for VideoLLMs by @zucchini-nlp in #36149
* Add require_read_token to fp8 tests by @MekkCyber in #36189
* Revert qwen2 breaking changes related to attention refactor by @ArthurZucker in #36162
* Guard against unset resolved_archive_file by @dmlap in #35628
* [Bugfix] Fix reloading of pixtral/llava configs by @kylesayrs in #36077
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @jiqing-feng
* Fix whisper compile (#35413)
* Enable gptqmodel (#35012)
* fix document qa bf16 pipeline (#35456)
* Fix vits low-precision dtype (#35418)
* fix low-precision audio classification pipeline (#35435)
* Refactor OPT model (#36101)
* @AhmedAlmaghz
* [i18n-ar] Translated file : docs/source/ar/tasks/token_classification.md into Arabic (#35193)
* [i18n-ar] Translated file: `docs/source/ar/tasks/masked_language_modeling.md` into Arabic (#35198)
* @sbucaille
* Add SuperGlue model (#29886)
* @Isotr0py
* Fix `head_dim` in config extracted from Gemma2 GGUF model (#35818)
* Split and clean up GGUF quantization tests (#35502)
* Add ImageProcessorFast to Qwen2.5-VL processor (#36164)
* @ShuaiBai623
* add qwen2.5vl (#35569)
* @alex-jw-brooks
* Granite Vision Support (#35579)
* Update Granite Vision Model Path / Tests (#35998)
* @pglorio
* Add Zamba2 (#34517)
* Fix RMSNormGated in Zamba2 (#35943)
* @conditionedstimulus
* Add DAB-DETR for object detection (#30803)
* @jadechoghari
* Adding RT-DETRv2 for object detection (#34773)
* @geetu040
* Add Apple's Depth-Pro for depth estimation (#34583)
* @zhuhanqing
* Optim: APOLLO optimizer integration (#36062)
* @bauwenst
* Move `DataCollatorForMultipleChoice` from the docs to the package (#34763)
* @elvircrn
* Efficient Inference Kernel for SpQR (#34976)
* Add SuperGlue model by @sbucaille in #29886
## Granite Vision Support
The Granite Vision model is a variant of [LLaVA-NeXT](https://huggingface.co/docs/transformers/main/en/model_doc/llava_next), leveraging a [Granite](https://huggingface.co/docs/transformers/main/en/model_doc/granite) language model alongside a [SigLIP](https://huggingface.co/docs/transformers/main/en/model_doc/SigLIP) visual encoder. It utilizes multiple concatenated vision hidden states as its image features, similar to [VipLlava](https://huggingface.co/docs/transformers/main/en/model_doc/vipllava). It also uses a larger set of image grid pinpoints than the original LlaVa-NeXT models to support additional aspect ratios.
* Granite Vision Support by @alex-jw-brooks in #35579
## Zamba2
Zamba2 is a large language model (LLM) trained by Zyphra, and made available under an Apache 2.0 license.
Zamba2-1.2B, Zamba2-2.7B and Zamba2-7B are hybrid models combining state-space models (Specifically [Mamba](https://github.com/state-spaces/mamba)) and transformer, and were trained using next-token prediction. Zamba2 uses shared transformer layers after every 6 mamba blocks. It uses the [Mistral v0.1 tokenizer](https://huggingface.co/mistralai/Mistral-7B-v0.1). We came to this architecture after a series of ablations at small scales. Zamba2-1.2B, Zamba2-2.7B and Zamba2-7B were pre-trained on 2T and 3T tokens, respectively.

* Add Zamba2 by @pglorio in #34517
## GOT-OCR 2.0
GOT-OCR2 works on a wide range of tasks, including plain document OCR, scene text OCR, formatted document OCR, and even OCR for tables, charts, mathematical formulas, geometric shapes, molecular formulas and sheet music. While this implementation of the model will only output plain text, the outputs can be further processed to render the desired format, with packages like pdftex, mathpix, matplotlib, tikz, verovio or pyecharts. The model can also be used for interactive OCR, where the user can specify the region to be recognized by providing the coordinates or the color of the region’s bounding box.

* Add GOT-OCR 2.0 to Transformers by @yonigozlan in #34721
## DAB-DETR
DAB-DETR is an enhanced variant of Conditional DETR. It utilizes dynamically updated anchor boxes to provide both a reference query point (x, y) and a reference anchor size (w, h), improving cross-attention computation. This new approach achieves 45.7% AP when trained for 50 epochs with a single ResNet-50 model as the backbone.

* Add DAB-DETR for object detection by @conditionedstimulus in #30803
## Depth PRO
DepthPro is a foundation model for zero-shot metric monocular depth estimation, designed to generate high-resolution depth maps with remarkable sharpness and fine-grained details. It employs a multi-scale Vision Transformer (ViT)-based architecture, where images are downsampled, divided into patches, and processed using a shared Dinov2 encoder. The extracted patch-level features are merged, upsampled, and refined using a DPT-like fusion stage, enabling precise depth estimation.

* Add Apple's Depth-Pro for depth estimation by @geetu040 in #34583
## RT-DETRv2
An improved **Real-Time** DEtection TRansformer (RT-DETR). RT-DETRv2 refines RT-DETR by introducing selective multi-scale feature extraction, a discrete sampling operator for broader deployment compatibility. These improvements yield a 0.3 to 1.4 increase in mAP metrics on the COCO dataset, all while maintaining the same parameter count and frames-per-second (FPS) performance.

* Adding RTDETRv2 by @jadechoghari in #34773
## Transformers-CLI
Transformers' CLI welcomes a new command: `chat`. This command starts a conversation with the model of your choosing directly in your terminal.
This feature exists in TRL and has been migrated to `transformers` for easier usage.

* [Chat] Add Chat from TRL 🐈 by @gante in #35714
## Processor Standardization
An ongoing work is to standardize the image processors so that their API is equivalent. Additionally, the processors are given a fast variant so that they are never blockers in the image processing pipelines.
In this release, several processors have been standardized and have seen their fast version be contributed.
* OwlViT/Owlv2 post processing standardization by @qubvel in #34929
* OmDet Turbo processor standardization by @qubvel in #34937
* Grounding DINO Processor standardization by @qubvel in #34853
* Refactoring of ImageProcessorFast by @yonigozlan in #35069
* add Qwen2-VL image processor fast by @yonigozlan in #35733
* Remove Multi-threaded image conversion for fast image processors by @yonigozlan in #36105
## Breaking changes
### DPT segmentation maps
DPT image processors did not support `segmentation_maps`, instead only requiring `images`. This has been fixed.
This adds an argument to the `preprocess` method, therefore users using arguments as positional arguments with that method may see changed behavior. We recommend using keyword arguments for such methods so as to not be bothered by the addition of new features.
* 🔴 🔴 🔴 Added `segmentation maps` support for DPT image processor by @simonreise in #34345
### Image classification pipeline and single vs multi-label
The `problem_type` in the config.json file was read incorrectly by the pipeline, which mapped single-label to multi-label losses, and vice-versa. This has been fixed.
* 🚨🚨🚨 image-classification pipeline single-label and multi-label prob type squashing fns (sigmoid vs softmax) are backwards by @rwightman in #35848
### Fixing the LayerNorm beta/gamma renames
The description of the pull request is the easiest way to understand the problem, why it exists, and how it is solved; please read the description below:
* 🚨🚨🚨 An attempt to fix #29554. Include 'LayerNorm.' in gamma/beta rename scope, optimize string search. by @rwightman in #35615
### VLM cleanup
The `ignore_index` property of the llava configuration has been removed as it was not serving a purpose.
* 🔴 VLM: compile compatibility by @zucchini-nlp in #35724
## Quantization
Quantization has received several improvements and fixes, including the contribution of FP8 quantization and the HIGGS quantization interface.
Additionally, we're replacing the AutoGPTQ implementaiton with GPTQModel from ModelCloud (see repository [here)](https://github.com/ModelCloud/GPTQModel?tab=readme-ov-file)).
GPTQModel originated as major refractor of AutoGPTQ but is now a full-stand-in replacement with cleaner api, up-to-date model support, faster inference, higher quality quants.
* Enable gptqmodel by @ jiqing-feng in #35012
* Split and clean up GGUF quantization tests by @Isotr0py in #35502
* Display warning for unknown quants config instead of an error by @SunMarc in #35963
* Adding FP8 Quantization to transformers by @MekkCyber in #36026
* New HIGGS quantization interfaces, JIT kernel compilation support. by @BlackSamorez in #36148
## Generate
* [generate] revert change in Aria: the maximum cache length must match `max_length` by @gante in #36120
* 🧹 remove `generate`-related objects and methods scheduled for removal in v4.48 by @gante in #35677
* [generate] can instantiate `GenerationConfig(cache_implementation="static")` by @gante in #35679
* [generate] return Cache object even if passed in a legacy format by @gante in #35673
* [generate] update docstring of `SequenceBiasLogitsProcessor` by @gante in #35699
* Test: generate with `torch.compile(model.forward)` as a fast test by @gante in #34544
* [generate] move max time tests by @gante in #35962
* [generate] shape checks in tests compatible with fixed-length caches (+ some minor fixes) by @gante in #35993
## Pipelines
Pipelines have received several bug fixes and improvements which are detailed below.
* Stop mutating input dicts in audio classification pipeline by @Rocketknight1 in #35754
* fix document qa bf16 pipeline by @jiqing-feng in #35456
* fix low-precision audio classification pipeline by @jiqing-feng in #35435
* [pipeline] missing import regarding assisted generation by @gante in #35752
* Output dicts support in text generation pipeline by @jonasrohw in #35092
* Fix Audio Classification Pipeline top_k Documentation Mismatch and Bug #35736 by @sambhavnoobcoder in #35771
## Bugfixes and improvements
* Fix flaky `test_custom_4d_attention_mask` by @ydshieh in #35606
* Use inherit tempdir makers for tests + fix failing DS tests by @muellerzr in #35600
* Added error when sequence length is bigger than max_position_embeddings by @Taha1506 in #32156
* Let `EarlyStoppingCallback` not require `load_best_model_at_end` by @muellerzr in #35101
* Fix flaky `test_beam_search_low_memory` by @ydshieh in #35611
* Skip `MobileNetV1ModelTest::test_batching_equivalence` for now by @ydshieh in #35614
* Update codeowners with individual model owners by @Rocketknight1 in #35595
* Fix device in rope module when using dynamic updates by @Cyrilvallez in #35608
* Fix whisper compile by @jiqing-feng in #35413
* Removed some duplicated code by @Sai-Suraj-27 in #35637
* [`Phi`] bias should be True by @ArthurZucker in #35650
* Enable different torch dtype in sub models by @zucchini-nlp in #34873
* [`Compile`] Only test compiling model forward pass by @ArthurZucker in #35658
* [tests] make cuda-only tests device-agnostic by @faaany in #35607
* [i18n-ar] Translated file : docs/source/ar/tasks/token_classification.md into Arabic by @AhmedAlmaghz in #35193
* Fix `zero_shot_image_classification` documentation guide link in SigLIP by @aretrace in #35671
* Fix : adding einops lib in the CI docker for some bitsandbytes tests by @MekkCyber in #35652
* Update torchao.md: use auto-compilation by @martin0258 in #35490
* Fix : HQQ config when hqq not available by @MekkCyber in #35655
* Fix expected output for ggml test by @MekkCyber in #35686
* Fix : add require_read_token for gemma2 gated model by @MekkCyber in #35687
* Enhanced Installation Section in README.md by @egojoseph in #35094
* Enhance DataCollatorForLanguageModeling with Configurable Token Replacement Probabilities by @mahdibaghbanzadeh in #35251
* Clean-up composite configs by @zucchini-nlp in #34603
* Add future import for Py < 3.10 by @Rocketknight1 in #35666
* Enable gptqmodel by @jiqing-feng in #35012
* Fix : Nemotron Processor in GGUF conversion by @MekkCyber in #35708
* Fix typo in /docs/source/ja/model_doc/decision_transformer.md URL by @hiroaki222 in #35705
* Replace deprecated batch_size with max_batch_size when using HybridCache by @mtreinik in #35498
* Fix: Falcon tie_word_embeddings in GGUF by @MekkCyber in #35715
* Fix condition when GA loss bug fix is not performed by @techkang in #35651
* Fix the bug that `Trainer` cannot correctly call `torch_jit_model_eval` by @Wanguy in #35722
* [generation] fix type hint by @gante in #35725
* Add proper jinja2 error by @Rocketknight1 in #35533
* Optimize ForCausalLMLoss by removing unnecessary contiguous() call to reduce memory overhead by @efsotr in #35646
* Modular: support for importing functions from any file by @Cyrilvallez in #35692
* Remove batch size argument warning when unjustified by @quintenroets in #35519
* [cache] add a test to confirm we can use cache at train time by @gante in #35709
* Remove `pt_to_tf` by @gante in #35672
* Added resource class configuration option for `check_circleci_user` job by @Sai-Suraj-27 in #32866
* Fix some tests by @Cyrilvallez in #35682
* Unable to use `MimiModel` with DeepSpeed ZeRO-3 by @anferico in #34735
* check is added for the report_to variable in TrainingArguments by @alpertunga-bile in #35403
* Added liger_kernel compatibility with `PeftModel` by @ambroser53 in #35680
* Restore is_torch_greater_or_equal_than for backward compatibility by @tlrmchlsmth in #35734
* Revert "Unable to use `MimiModel` with DeepSpeed ZeRO-3" by @eustlb in #35755
* ci: fix xpu skip condition for test_model_parallel_beam_search by @dvrogozh in #35742
* Use AMD CI workflow defined in hf-workflows by @ivarflakstad in #35058
* Fix CI for VLMs by @zucchini-nlp in #35690
* Security fix for `self-comment-ci.yml` by @ydshieh in #35548
* [ViTPose] Convert more checkpoints by @NielsRogge in #35638
* fix register_buffer in MimiEuclideanCodebook by @anferico in #35759
* remove code owners as it was generating too much noise BUT by @ArthurZucker in #35784
* Skip Falcon 7B GGML Test by @MekkCyber in #35783
* [fix] cannot import name 'Pop2PianoFeatureExtractor' from 'transformers' by @faaany in #35604
* transformers.image_transforms.normalize wrong types by @CalOmnie in #35773
* Patch moonshine by @eustlb in #35731
* Don't import torch.distributed when it's not available by @booxter in #35777
* Fix vits low-precision dtype by @jiqing-feng in #35418
* Tool calling: support more types by @aymeric-roucher in #35776
* Fixes, improvements to `timm` import behaviour by @rwightman in #35800
* modular_model_converter bugfix on assignments by @nikosanto13 in #35642
* Deterministic sorting in modular converter when adding new functions by @Cyrilvallez in #35795
* Fix "test_chat_template_dict" in video LLMs by @zucchini-nlp in #35660
* Update AMD Docker image by @ivarflakstad in #35804
* Add LlavaImageProcessor by @NielsRogge in #33191
* Byebye `test_batching_equivalence`'s flakiness by @ydshieh in #35729
* [Doc] Adding blog post to model doc for `TimmWrapper` by @ariG23498 in #35744
* add a new flax example for Bert model inference by @louie-tsai in #34794
* Support adamw_torch_8bit by @fzyzcjy in #34993
* Auto-add `timm` tag to timm-wrapper models. by @pcuenca in #35794
* Fix : BLOOM tie_word_embeddings in GGUF by @MekkCyber in #35812
* Fixed typo in autoawq version number in an error message for IPEX backend requirements. by @InfroLab in #35815
* Remove deprecated `get_cached_models` by @Wauplin in #35809
* Optimized set_initialized_submodules. by @LagPixelLOL in #35493
* [i18n-ar] Translated file: `docs/source/ar/tasks/masked_language_modeling.md` into Arabic by @AhmedAlmaghz in #35198
* move fastspeech to audio models by @eustlb in #35788
* Improve modular documentation by @Cyrilvallez in #35737
* [Mimi] update test expected values for t4 runners by @eustlb in #35696
* Remove old `benchmark` code by @gante in #35730
* Remove pyav pin to allow python 3.11 to be used by @CalOmnie in #35823
* Another security patch for `self-comment-ci.yml` by @ydshieh in #35816
* Init cache on meta device by @zucchini-nlp in #35164
* Hotfix: missing `working-directory` in `self-comment-ci.yml` by @ydshieh in #35833
* [gpt2] fix generation tests by @gante in #35822
* Fix : Nemotron tokenizer for GGUF format by @MekkCyber in #35836
* Fix `head_dim` in config extracted from Gemma2 GGUF model by @Isotr0py in #35818
* [chat] docs fix by @gante in #35840
* Fix compatibility issues when using auto_gptq with these older versions by @LRL-ModelCloud in #35830
* Add PyTorch version check for FA backend on AMD GPUs by @mht-sharma in #35813
* Fix NoneType type as it requires py>=3.10 by @SunMarc in #35843
* [ `tests`] remove some flash attention class tests by @ArthurZucker in #35817
* [Backend support] Allow `num_logits_to_keep` as Tensor + add flag by @Cyrilvallez in #35757
* Fix GA loss for Deepspeed by @timjeffrey10 in #35808
* Fix uploading processors/tokenizers to WandB on train end by @jack89roberts in #35701
* Fix more CI tests by @ArthurZucker in #35661
* [DOC] Fix contamination and missing paragraph in translation by @Yosshi999 in #35851
* Fix typo by @SilverSoldier in #35854
* fix apply_chat_template() padding choice by @baoyf4244 in #35828
* Fix `test_pipelines_video_classification` that was always failing by @CalOmnie in #35842
* Fix Llava-NeXT / Llava-NeXT Video / Llava-OneVision's token unpadding mismatch by @sheryc in #35779
* use torch.testing.assertclose instead to get more details about error in cis by @ArthurZucker in #35659
* add xpu device check in device_placement by @faaany in #35865
* Add `Rocketknight1` to `self-comment-ci.yml` by @ydshieh in #35881
* [doctest] Fixes by @stevhliu in #35863
* Fix fast image processor warnings in object detection examples by @sugendran in #35892
* Update deepspeed amd image by @ivarflakstad in #35906
* Fix typing in audio_utils.chroma_filter_bank by @CalOmnie in #35888
* [docs] uv install by @stevhliu in #35821
* Fix the config class comparison for remote code models by @Rocketknight1 in #35592
* Close Zamba2Config code block by @Rocketknight1 in #35914
* [docs] Fix Zamba2 by @stevhliu in #35916
* Remove `_supports_static_cache = True` for some model classes by @ydshieh in #34975
* Use rocm6.2 for AMD images by @ivarflakstad in #35930
* Add default TP plan for all models with backend support by @Cyrilvallez in #35870
* Fix: loading DBRX back from saved path by @zucchini-nlp in #35728
* Fix mask slicing for models with HybridCache by @Cyrilvallez in #35681
* Qwen-2-5-VL: fix CI by @zucchini-nlp in #35935
* Fix TP initialization by @Cyrilvallez in #35860
* fix(FA): QKV not being casted to target_dtype for FA with dpo lora by @NanoCode012 in #35834
* Remove INC notebook reference in documentation by @echarlaix in #35936
* use torch constraints to check if covariance is positive definite during mean resizing. by @abuelnasr0 in #35693
* fix `test_generated_length_assisted_generation` by @keyboardAnt in #34935
* Update `unwrap_and_save_reload_schedule` to use `weights_only=False` by @ydshieh in #35952
* Update `squad_convert_example_to_features` to work with numpy v2 by @ydshieh in #35955
* Fix flaky `test_assisted_decoding_matches_greedy_search` by @ydshieh in #35951
* Trainer Refactor: Part 1 by @muellerzr in #35567
* update docker file `transformers-pytorch-deepspeed-latest-gpu` by @ydshieh in #35940
* [tests] further fix `Tester object has no attribute '_testMethodName'` by @faaany in #35781
* Update README.md by @BlessedTatonka in #35958
* fix iterator overflow when gradient accumulation is 1 by @winglian in #35960
* Fix is_causal being a tensor by @IlyasMoutawwakil in #35791
* [bart] minor test fixes by @gante in #35965
* Pixtral: vectorize patch embeddings and enable tests by @zucchini-nlp in #35122
* Whisper: fix static cache CI by @zucchini-nlp in #35852
* Less flaky for `TimmBackboneModelTest::test_batching_equivalence` by @ydshieh in #35971
* Support batching for UsefulSensors Moonshine by @njeffrie in #35922
* not to use A100 for `benchmark.yml` by @ydshieh in #35974
* Handle empty change indices in SAM's mask to rle conversion by @MSt-10 in #35665
* Add support for nested images to LLava and VipLLava by @yonigozlan in #35558
* [Moonshine] compute head_dim_padding at init by @eustlb in #35984
* [Moshi] disable automatic compilation if the model can't compile by @gante in #35992
* use torch 2.6 for daily CI by @ydshieh in #35985
* Update-tp test by @ArthurZucker in #35844
* Add mean_resizing for every VLMs' resizing_token_embeddings() by @YenFuLin in #35717
* Update Granite Vision Model Path / Tests by @alex-jw-brooks in #35998
* Qwen2-VL: fix rope delta calculation by @zucchini-nlp in #36013
* Fix custom kernel for DeformableDetr, RT-Detr, GroindingDINO, OmDet-Turbo in Pytorch 2.6.0 by @qubvel in #35979
* apply_chat_template: consistent behaviour for return_assistant_tokens_mask=True return_tensors=True by @mrsndmn in #35582
* layernorm_decay_fix by @Ryoo72 in #35927
* Update Mistral converter by @Cyrilvallez in #35967
* Refactor (and fix) gpt_neox by @Cyrilvallez in #35610
* Fix device mismatch error in Whisper model during feature extraction by @thedebugger in #35866
* Fix RMSNormGated in Zamba2 by @pglorio in #35943
* Commont bot CI for other jobs (`generation` / `quantization`) by @ydshieh in #35341
* Hotfix for `self-comment-ci.yml` by @ydshieh in #36030
* feat(ci): ignore trufflehog unverified results by @McPatate in #36031
* CircleCI with python 3.9 by @ydshieh in #36027
* Update tests regarding attention types after #35235 by @ydshieh in #36024
* Fix Gemma2 synced multi-GPU generation by @ManukyanD in #35232
* Fix synced multi-GPU generation with LLMs and VLMs by @ManukyanD in #35893
* Add XPU type for work-around -inf mask causing sdpa NaN issue in modeling files by @Liangliang-Ma in #35647
* add support for empty list as input to create_model_card by @ROZBEH in #36042
* DeepSpeed github repo move sync by @stas00 in #36021
* [docs] no hard coding cuda as bnb has multi-backend support by @faaany in #35867
* [docs] fix bugs in the bitsandbytes documentation by @faaany in #35868
* [docs] no hard-coding cuda by @faaany in #36043
* Fix how we compute the final non-padding token for ForSequenceClassification models by @Rocketknight1 in #35911
* Add `Qwen2VLImageProcessorFast` into `Qwen2VLProcessor` by @yeliudev in #35987
* Iterative generation using Input embeds and `past_key_values` by @yaswanth19 in #35890
* Fix usage of unpad_input function by @pavelgein in #35925
* Fix repo consistency by @ydshieh in #36063
* Update `test_flash_attn_2_can_dispatch_composite_models` by @ydshieh in #36050
* Paligemma: fix generation with Gemma2 by @zucchini-nlp in #36044
* Save checkpoint to temporary directory to handle partial saves during failures by @SilverSoldier in #35580
* Nail in edge case of torch dtype being overriden permantly in the case of an error by @muellerzr in #35845
* Fix words typos in ggml test. by @zhanluxianshen in #36060
* Fix model kwargs by @muellerzr in #35875
* Fix StopStringCriteria to handle tokens above len(tokenizer) by @Rocketknight1 in #35797
* [docs] fix outdated example code in `trainer.md` by @faaany in #36066
* Adding RT-DETRv2 for object detection by @jadechoghari in #34773
* Fix bug in apply_rotary_pos_emb_flashatt: in Qwen2-5-VL by @DeepWaved in #36065
* Move audio top_k tests to the right file and add slow decorator by @Rocketknight1 in #36072
* Fix OS err by @muellerzr in #36094
* [docs] fix model checkpoint name by @faaany in #36075
* [docs] fix typo by @faaany in #36080
* [docs] fix not-working example code in `perf_infer_gpu_one.md` by @faaany in #36087
* fix MllamaVisionAttention typehint by @kylesayrs in #35975
* Processors: allow tuples of images when checking by @zucchini-nlp in #36084
* Chat template: update for processor by @zucchini-nlp in #35953
* Paligemma: revert #36084 by @zucchini-nlp in #36113
* Support constant lr with cooldown by @LoserCheems in #35453
* Enable pytest live log and show warning logs on GitHub Actions CI runs by @ydshieh in #35912
* Refactor OPT model by @jiqing-feng in #36101
* Revert checkpoint tmp dir by @SunMarc in #36112
* [Bugfix] fix file name of docstring in utils/check_table.py by @kkscilife in #36108
* fix bnb warning by @SunMarc in #36116
* AutoformerForPrediction test add atol by @ivarflakstad in #36017
* Fix nighlty CIs: missing atols by @ArthurZucker in #35903
* Add common test for `torch.export` and fix some vision models by @qubvel in #35124
* fix: typos in documentation files by @maximevtush in #36122
* update awesome-transformers.md. by @zhanluxianshen in #36115
* Fix max size deprecated warning by @HichTala in #34998
* Fix CI issues by @molbap in #35662
* update tiktoken integ to use converted by @ArthurZucker in #36135
* Make `output_dir` Optional in `TrainingArguments` #27866 by @sambhavnoobcoder in #35735
* [docs] minor doc fix by @faaany in #36127
* [docs] update awq doc by @faaany in #36079
* Add pipeline parallel plan to `PretrainedConfig` and `PreTrainedModel` by @hmellor in #36091
* add RAdamScheduleFree optimizer by @nhamanasu in #35313
* added warning to Trainer when label_names is not specified for PeftModel by @MilkClouds in #32085
* Whisper: remove redundant assisted generation tests by @gante in #34814
* Add utility for Reload Transformers imports cache for development workflow #35508 by @sambhavnoobcoder in #35858
* VLM: enable skipped tests by @zucchini-nlp in #35746
* [commands] remove deprecated/inoperational commands by @gante in #35718
* Fix Gradient Checkpointing for Deberta & Deberta-V2 using PEFT / Adapters by @lenglaender in #35898
* 🚨 Remove cache migration script by @Wauplin in #35810
* multi-gpu: fix tensor device placements for various models by @dvrogozh in #35763
* Optim: APOLLO optimizer integration by @zhuhanqing in #36062
* Fix multi gpu loss sync condition, add doc and test by @techkang in #35743
* adding option to save/reload scaler by @hsilva664 in #34932
* Update doc re list of models supporting TP by @kwen2501 in #35864
* Add more rigerous non-slow grad accum tests by @muellerzr in #35668
* Fix test fetcher by @ydshieh in #36129
* skip `test_initialization` for `VitPoseBackboneModelTest` for now by @ydshieh in #36154
* Add git LFS to AMD docker image by @ivarflakstad in #36016
* Mllama fsdp by @blbadger in #36000
* Fix PaliGemma Pad Token Masking During Training #35855 by @sambhavnoobcoder in #35859
* Add reminder config to issue template and print DS version in env by @Ben-Schneider-code in #35156
* Fix Gemma2 dtype issue when storing weights in float16 precision by @Nerogar in #35398
* Replace deprecated update_repo_visibility by @Wauplin in #35970
* Fix tests for vision models by @qubvel in #35654
* qwen2.5vl: fix bugs when using flash2+bf16 or num_return_sequences>1 by @gewenbin0992 in #36083
* docs: fix return type annotation of `get_default_model_revision` by @MarcoGorelli in #35982
* Fix PretrainedTokenizerFast check => Fix PretrainedTokenizerFast Save by @CL-ModelCloud in #35835
* Move `DataCollatorForMultipleChoice` from the docs to the package by @bauwenst in #34763
* Helium documentation fixes by @LysandreJik in #36170
* Remove loading custom kernel for RT-DETRv2 by @qubvel in #36098
* [Modular] skip modular checks based on diff by @gante in #36130
* Fix red CI by @ArthurZucker in #36174
* Fix : fix doc fp8 by @MekkCyber in #36173
* Efficient Inference Kernel for SpQR by @elvircrn in #34976
* fix training issues by @ArthurZucker in #36158
* add disable compile option by @ArthurZucker in #36161
* CI: avoid human error, automatically infer generative models by @gante in #33212
* Use tqdm auto by @SmartManoj in #35726
* Optimize Qwen2VL vision model by precomputing cos/sin embeds before ViT blocks by @li-plus in #35837
* Make `check_repository_consistency` run faster by MP by @ydshieh in #36175
* Fix the key name for _load_rng_state under torch.cuda by @wizyoung in #36138
* Follow up to SpQR integration by @MekkCyber in #36176
* Fix a mistake in #36175 by @ydshieh in #36179
* Fix make_batched_videos and add tests by @yonigozlan in #36143
* Uniformize OwlViT and Owlv2 processors by @yonigozlan in #35700
* Add support for partial rotary embeddings in Phi3 model by @garg-amit in #35947
* CI: fix `test-save-trainer` by @zucchini-nlp in #36191
* Chat template docs by @zucchini-nlp in #36163
* Add ImageProcessorFast to Qwen2.5-VL processor by @Isotr0py in #36164
* Prepare processors for VideoLLMs by @zucchini-nlp in #36149
* Add require_read_token to fp8 tests by @MekkCyber in #36189
* Revert qwen2 breaking changes related to attention refactor by @ArthurZucker in #36162
* Guard against unset resolved_archive_file by @dmlap in #35628
* [Bugfix] Fix reloading of pixtral/llava configs by @kylesayrs in #36077
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @jiqing-feng
* Fix whisper compile (#35413)
* Enable gptqmodel (#35012)
* fix document qa bf16 pipeline (#35456)
* Fix vits low-precision dtype (#35418)
* fix low-precision audio classification pipeline (#35435)
* Refactor OPT model (#36101)
* @AhmedAlmaghz
* [i18n-ar] Translated file : docs/source/ar/tasks/token_classification.md into Arabic (#35193)
* [i18n-ar] Translated file: `docs/source/ar/tasks/masked_language_modeling.md` into Arabic (#35198)
* @sbucaille
* Add SuperGlue model (#29886)
* @Isotr0py
* Fix `head_dim` in config extracted from Gemma2 GGUF model (#35818)
* Split and clean up GGUF quantization tests (#35502)
* Add ImageProcessorFast to Qwen2.5-VL processor (#36164)
* @ShuaiBai623
* add qwen2.5vl (#35569)
* @alex-jw-brooks
* Granite Vision Support (#35579)
* Update Granite Vision Model Path / Tests (#35998)
* @pglorio
* Add Zamba2 (#34517)
* Fix RMSNormGated in Zamba2 (#35943)
* @conditionedstimulus
* Add DAB-DETR for object detection (#30803)
* @jadechoghari
* Adding RT-DETRv2 for object detection (#34773)
* @geetu040
* Add Apple's Depth-Pro for depth estimation (#34583)
* @zhuhanqing
* Optim: APOLLO optimizer integration (#36062)
* @bauwenst
* Move `DataCollatorForMultipleChoice` from the docs to the package (#34763)
* @elvircrn
* Efficient Inference Kernel for SpQR (#34976)
Patch release v4.48.3 (2025-02-07)
# Patch release v4.48.3
This ends the python3.9 issues mostly!
- Add future import for Py < 3.10 (#35666) by @Rocketknight1
For some very niche cases, the new rope embedding introduced device failures
- Fix device in rope module when using dynamic updates (#35608) by @Cyrilvallez
## Num items in batch
- Fix model kwargs (#35875) by @muellerzr: this is long due, sorry that it took so long. Some models were not compatible with the `num_items_in_batch`
Finally the fix to Gemma2 is propagated to paligemma2!
- Paligemma: fix generation with Gemma2 (#36044) by @zucchini-nlp
Patch release v4.48.2 (2025-01-30)
# Patch release v4.48.2
Sorry because the fixes for `num_items_in_batches` are not done yet 😓 To follow along see this [PR](https://github.com/huggingface/transformers/pull/35875), a new patch will be available soon!
Now, we mostly had BC issue with python version 3.9:
- Restore is_torch_greater_or_equal_than for backward compatibility (#35734) by @tlrmchlsmth
- Fix NoneType type as it requires py>=3.10 (#35843) by @SunMarc
Then we had a small regression for DBRX saving:
- Fix: loading DBRX back from saved path (#35728) by @zucchini-nlp
Finally we have a fix for gemma and the hybrid attention architectures:
- Fix mask slicing for models with HybridCache #35681 by @Cyrilvallez
Miscellaneous:
- Fix is_causal being a tensor (#35791) by @IlyasMoutawwakil
Patch release v4.48.1 (2025-01-20)
# Patch release v4.48.1
Yet again we are dawned with a gradient accumulation fix! There is also a refactoring of the attention that let a small typo in, we made sure PHI is no longer broken!
`Moonshine` had a small issue when wrapping generate so we removed that!
- [Phi] bias should be True (#35650) @ArthurZucker
- Fix condition when GA loss bug fix is not performed (#35651) @techkang
- Patch moonshine (#35731) @eustlb
🤗
v4.48.0: ModernBERT, Aria, TimmWrapper, ColPali, Falcon3, Bamba, VitPose, DinoV2 w/ Registers, Emu3, Cohere v2, TextNet, DiffLlama, PixtralLarge, Moonshine (2025-01-10)
## New models
### ModernBERT
The ModernBert model was proposed in [Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference](https://arxiv.org/abs/2412.13663) by Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Galalgher, Raja Bisas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Grifin Adams, Jeremy Howard and Iacopo Poli.
It is a refresh of the traditional encoder architecture, as used in previous models such as [BERT](https://huggingface.co/docs/transformers/en/model_doc/bert) and [RoBERTa](https://huggingface.co/docs/transformers/en/model_doc/roberta).
It builds on BERT and implements many modern architectural improvements which have been developed since its original release, such as:
- [Rotary Positional Embeddings](https://huggingface.co/blog/designing-positional-encoding) to support sequences of up to 8192 tokens.
- [Unpadding](https://arxiv.org/abs/2208.08124) to ensure no compute is wasted on padding tokens, speeding up processing time for batches with mixed-length sequences.
- [GeGLU](https://arxiv.org/abs/2002.05202) Replacing the original MLP layers with GeGLU layers, shown to improve performance.
- [Alternating Attention](https://arxiv.org/abs/2004.05150v2) where most attention layers employ a sliding window of 128 tokens, with Global Attention only used every 3 layers.
- [Flash Attention](https://github.com/Dao-AILab/flash-attention) to speed up processing.
- A model designed following recent [The Case for Co-Designing Model Architectures with Hardware](https://arxiv.org/abs/2401.14489), ensuring maximum efficiency across inference GPUs.
- Modern training data scales (2 trillion tokens) and mixtures (including code ande math data)

* Add ModernBERT to Transformers by @warner-benjamin in #35158
### Aria
The Aria model was proposed in [Aria: An Open Multimodal Native Mixture-of-Experts Model](https://huggingface.co/papers/2410.05993) by Li et al. from the Rhymes.AI team.
Aria is an open multimodal-native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. It has a Mixture-of-Experts architecture, with respectively 3.9B and 3.5B activated parameters per visual token and text token.
* Add Aria by @aymeric-roucher in #34157

### TimmWrapper
We add a `TimmWrapper` set of classes such that timm models can be loaded in as transformer models into the library.
Here's a general usage example:
```py
import torch
from urllib.request import urlopen
from PIL import Image
from transformers import AutoConfig, AutoModelForImageClassification, AutoImageProcessor
checkpoint = "timm/resnet50.a1_in1k"
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image_processor = AutoImageProcessor.from_pretrained(checkpoint)
inputs = image_processor(img, return_tensors="pt")
model = AutoModelForImageClassification.from_pretrained(checkpoint)
with torch.no_grad():
logits = model(**inputs).logits
top5_probabilities, top5_class_indices = torch.topk(logits.softmax(dim=1) * 100, k=5)
```
Thanks to this, timm models now have access to pipelines, as well as `Trainer`, accelerate device maps, quantization, etc:
```py
import torch
from urllib.request import urlopen
from PIL import Image
from transformers import pipeline
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
pipe = pipeline("image-classification", model="timm/resnet18.a1_in1k")
print(pipe(img))
```
* Add TimmWrapper by @qubvel and @amyeroberts in #34564
### Pixtral-Large
Pixtral modeling and checkpoint conversion code has been updated to support the new [Pixtral-Large](https://huggingface.co/mistralai/Pixtral-Large-Instruct-2411) model.
* Update Pixtral conversion script to support large format! by @arthurzucker in #34801
### ColPali
The ColPali model was proposed in [ColPali: Efficient Document Retrieval with Vision Language Models](https://doi.org/10.48550/arXiv.2407.01449) by Manuel Faysse*, Hugues Sibille*, Tony Wu*, Bilel Omrani, Gautier Viaud, Céline Hudelot, Pierre Colombo (* denotes equal contribution). Work lead by ILLUIN Technology.
In the proposed ColPali approach, the authors leverage VLMs to construct efficient multi-vector embeddings directly from document images (“screenshots”) for document retrieval. They train the model to maximize the similarity between these document embeddings and the corresponding query embeddings, using the late interaction method introduced in ColBERT.

* Add ColPali to 🤗 transformers by @tonywu71 and @yonigozlan in #33736
### Falcon3
Falcon3 represents a natural evolution from previous releases, emphasizing expanding the models’ science, math, and code capabilities. This iteration includes five base models: Falcon3-1B-Base, Falcon3-3B-Base, Falcon3-Mamba-7B-Base, Falcon3-7B-Base, and Falcon3-10B-Base. In developing these models, the authors incorporated several key innovations aimed at improving the models’ performances while reducing training costs:
One pre-training: They conducted a single large-scale pretraining run on the 7B model, using 2048 H100 GPU chips, leveraging 14 trillion tokens featuring web, code, STEM, and curated high-quality and multilingual data. Depth up-scaling for improved reasoning: Building on recent studies on the effects of model depth, they upscaled the 7B model to a 10B parameters model by duplicating the redundant layers and continuing pre-training with 2TT of high-quality data. This yielded Falcon3-10B-Base which achieves state-of-the-art zero-shot and few-shot performance for models under 13B parameters. Knowledge distillation for better tiny models: To provide compact and efficient alternatives, we developed Falcon3-1B-Base and Falcon3-3B-Base by leveraging pruning and knowledge distillation techniques, using less than 100GT of curated high-quality data, thereby redefining pre-training efficiency.
* Add Falcon3 documentation by @mokeddembillel in #35307
### Bamba
Bamba-9B is a decoder-only language model based on the [Mamba-2](https://github.com/state-spaces/mamba) architecture and is designed to handle a wide range of text generation tasks. It is trained from scratch using a two-stage training approach. In the first stage, the model is trained on 2 trillion tokens from the Dolma v1.7 dataset. In the second stage, it undergoes additional training on 200 billion tokens, leveraging a carefully curated blend of high-quality data to further refine its performance and enhance output quality.
Checkout all Bamba-9B model checkpoints [here](https://github.com/foundation-model-stack/bamba).
* Add the Bamba Model by @fabianlim in #34982
### VitPose
ViTPose is a state-of-the-art vision transformer-based model for human pose estimation, introduced by Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao in ["ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation”](https://arxiv.org/abs/2204.12484).
The model leverages the capabilities of vision transformers to accurately predict 2D human keypoints. Adopting a top-down approach, ViTPose estimates keypoints locations for each detected person, allowing it to be easily used with any object detection model.

* Add VitPose by @SangbumChoi and @NielsRogge in #30530
### DINOv2 with registers
The DINOv2 with Registers model was proposed in [Vision Transformers Need Registers](https://arxiv.org/abs/2309.16588) by Timothée Darcet, Maxime Oquab, Julien Mairal, Piotr Bojanowski.
The [Vision Transformer](https://huggingface.co/docs/transformers/main/en/model_doc/vit) (ViT) is a transformer encoder model (BERT-like) originally introduced to do supervised image classification on ImageNet.
Next, people figured out ways to make ViT work really well on self-supervised image feature extraction (i.e. learning meaningful features, also called embeddings) on images without requiring any labels. Some example papers here include [DINOv2](https://huggingface.co/docs/transformers/main/en/model_doc/dinov2) and [MAE](https://huggingface.co/docs/transformers/main/en/model_doc/vit_mae).
The authors of DINOv2 noticed that ViTs have artifacts in attention maps. It’s due to the model using some image patches as “registers”. The authors propose a fix: just add some new tokens (called “register” tokens), which you only use during pre-training (and throw away afterwards). This results in:
- no artifacts
- interpretable attention maps
- and improved performances.
* Add DINOv2 with registers by @NielsRogge in #35348
### Emu3
The Emu3 model was proposed in [Emu3: Next-Token Prediction is All You Need](https://arxiv.org/abs/2409.18869) by Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, Zhongyuan Wang.
Emu3 sets a new standard in multimodal AI by using next-token prediction to handle images, text, and videos. It simplifies multimodal modeling by tokenizing all data into a unified format and training a single transformer. Visual data is tokenized using vector quantization methods based on [VQ-VAE](https://arxiv.org/abs/1711.00937) model. Discretized visual tokens are later fused with text token ids for image and text generation.
Emu3 outperforms leading models like SDXL and LLaVA-1.6 in both generation and perception tasks, without relying on diffusion or compositional methods..
* Add Emu3 by @zucchini-nlp in #33770
### Cohere2
A new Cohere update was added through a new "Cohere2" set of classes.
* Add Cohere2 model by @alexrs-cohere in #35224
### TextNet
[TextNet](https://arxiv.org/abs/2111.02394) is a lightweight and efficient architecture designed specifically for text detection, offering superior performance compared to traditional models like MobileNetV3. With variants TextNet-T, TextNet-S, and TextNet-B (6.8M, 8.0M, and 8.9M parameters respectively), it achieves an excellent balance between accuracy and inference speed.
* Add TextNet by @jadechoghari in #34979
### DiffLlama
[Differential Transformer](https://arxiv.org/abs/2410.05258) combines the Llama architecture with Differential Transformer's Attention.
* Add DiffLllama by @weak-kajuma in #34083
### PixtralLarge
The conversion script needed a few update, while the modeling code was barely changed!
* [PixtralLarge] Update Pixtral conversion script to support large format! (#34801)
### Moonshine
Moonshine is an autoregressive speech recognition encoder-decoder model that improves upon Whisper's architecture. Namely, it replaces absolute position embeddings with Rotary Position Embeddings (RoPE). This allows Moonshine to handle audio inputs of any length, unlike Whisper, which is restricted to fixed 30-second windows. It was introduced by Nat Jeffries, Evan King, Manjunath Kudlur, Guy Nicholson, James Wang, and Pete Warden in [Moonshine: Speech Recognition for Live Transcription and Voice Commands
](https://arxiv.org/abs/2410.15608).
* Add Moonshine by @eustlb in #34784
## Quantization methods
### VPTQ Quantization
From the VPTQ contributors:
> VPTQ is a novel Post-Training Quantization method that leverages Vector Quantization to high accuracy on LLMs at an extremely low bit-width (<2-bit). VPTQ can compress 70B, even the 405B model, to 1-2 bits without retraining and maintain high accuracy.. More details here: https://github.com/microsoft/vptq
* FEAT : Adding VPTQ quantization method to HFQuantizer by @wejoncy in #34770
### HIGGS Quantization
From the contributors:
> HIGGS is a new 0-shot quantization algorithm that combines Hadamard preprocessing with MSE-Optimal quantization grids to achieve lower quantization error and SOTA performance. You can find more information in the [paper](https://arxiv.org/abs/2411.17525).
>
> Runtime support for HIGGS is implemented through [FLUTE](https://arxiv.org/abs/2407.10960), and its [library](https://github.com/HanGuo97/flute?tab=readme-ov-file).
>
> This PR adds support for HIGGS+FLUTE into transformers allowing for low-error 0-shot quantization and fast LLM inference.
* HIGGS Quantization Support by @BlackSamorez in #34997
## Cleanup
We merged a cleanup for vision language models, to make sure it all models are standardized.
* VLMs: major clean up 🧼 (#34502)
## Breaking changes
### Conversion scripts
Many models in Transformers include scripts to convert the original model checkpoints into a Transformers-compatible format. These scripts can be found in the repo using the glob pattern `models/**/convert_*.py`. They were a recurring source of vulnerability reports and CVEs because many models were originally released using insecure formats like older PyTorch `.bin` weights or `pickle` files. The conversion scripts had to open these formats, and this meant that they were vulnerable to maliciously crafted inputs.
In practice, we do not see this as a serious vulnerability. The conversion scripts are never imported or called by the rest of the library; each script is standalone, and so the only way to exploit the vulnerability is to create a malicious checkpoint, induce a user to download it, and then also induce them to manually call a specific conversion script on it.
However, even if there is little practical risk of an exploit, we are aware that open vulnerability reports create a compliance problem for users, and so beginning with this release we will be excluding these conversion scripts from release branches and wheels. They will remain accessible to developers on the `main` branch.
* 🚨🚨🚨 Delete conversion scripts when making release wheels by @Rocketknight1 in #35296
### Backtracking in Nougat
A regular expression used within the Nougat code has been modified to ensure it does not hang. The method should output the same results but we cannot guarantee it; we recommend upgrading to the latest transformers if you use this model to ensure your code is performance-optimized.
* 🚨🚨🚨 Limit backtracking in Nougat regexp by @qubvel in #35264
### Whisper decoding
This PR finalizes work that aimes to enable short-form (< 30 secs) and long-form generation using temperature fallback. It is a significant improvement to the whisper codebase, but it does result in the following breaking changes:
➡️ **Previously:**
• Short-form: Returned a `ModelOutput` or `torch.LongTensor`, including decoder input IDs and the EOS token ID.
• Long-form: Returned a `Dict` or `torch.LongTensor`, excluding decoder input IDs and the EOS token ID.
➡️ **From now on:**
Short-form and long-form generation are now treated identically, meaning output differentiation based on these modes is no longer applicable.
Decoder input IDs and EOS token IDs are never returned, except in two specific cases: when `return_dict_in_generate=True` and (`return_timestamps=False` or `force_unique_generate_call=True`).
In this case, the output will be a `ModelOutput`, which is the result of the underlying call to GenerationMixin’s generate. Indeed, `return_timestamps=False` ensures no seeking occurs; only a single call to generate is made. Therefore, this output includes both decoder input IDs and the EOS token ID.
* [Whisper] 🚨 Fix whisper decoding 🚨 by @eustlb in #34135
### Attention refactor
In order to have a cleaner, isolated, future-proof code for the attention layers, they have been refactored so as to keep the model attention code within their files; but attention definitions relating to SDPA, Flash Attention, and other types of attention have been moved to a common file.
* 🚨All attention refactor🚨 by @ArthurZucker in #35235
## Bugfixes and improvements
* Pipeline: simple API for assisted generation by @gante and @Rocketknight1 #34504
* [tokenizers] Ensure that add_prefix_space is propagated to backend_tokenizer.pre_tokenizer (#35593)
* Setup loss_type in config at model init time (#34616)
* [docs] Update Python version in translations by @jla524 in #35096
* [docs] top_p, top_k, temperature docstrings by @stevhliu in #35065
* Fix private forked repo. CI by @ydshieh in #35114
* Add feature dim attributes to BitLinear for easier PEFT integration by @agostinv in #34946
* Update I-JEPA checkpoints path by @qubvel in #35120
* Fix GA loss bugs and add unit test by @techkang in #35121
* [I-JEPA] Update docs by @NielsRogge in #35148
* Corrected typo in agent system prompts by @Uvi-12 in #35143
* Option to set 'non_blocking' for to(device) in BatchEncoding and BatchFeature by @daniel-bogdoll in #34883
* Fix typo in EETQ Tests by @MekkCyber in #35160
* Cleanup: continue the init refactor by @LysandreJik in #35167
* Super tiny fix logging message by @fzyzcjy in #35132
* Fixed typo of 'avilable' in prompts.py by @Uvi-12 in #35145
* [CI] Fix bnb quantization tests with accelerate>=1.2.0 by @matthewdouglas in #35172
* Fix `num_items_in_batch` not being an integer by @xspirus in #35115
* Assisted decoding multi-gpu by @zucchini-nlp in #35116
* Fix file path for shard_num 1 with mllama converter by @strangiato in #35053
* Support BatchNorm in Hubert pos_conv_emb as in fairseq by @gallilmaimon in #34389
* Remove unnecessary masked_fill in deberta models by @xadupre in #35182
* Fix DBRX LayerNorm init method by @hgt312 in #35177
* Fixing GGUF support for StableLm by @MekkCyber in #35060
* [i18n-ar] Translated file : `docs/source/ar/community.md` into Arabic by @AhmedAlmaghz in #33027
* Multiple typo fixes in NLP, Audio docs by @henryhmko in #35181
* Only import torch.distributed if it is available by @GaetanLepage in #35133
* [i18n-] Translating Benchmarks.md to Chinese by @asdkfjsd in #35137
* [docs] Fix FlashAttention link by @stevhliu in #35171
* Update data collator docstrings to accurately reference Nvidia tensor core compute capability version by @johngrahamreynolds in #35188
* [i18n-] Translating agents.md to Chinese by @HMJ0628 in #35139
* BLIP: enable device map by @zucchini-nlp in #34850
* 🧹 Remove deprecated RotaryEmbedding parts in the Attention layers by @Cyrilvallez in #34858
* [PEFT] Better Trainer error when prompt learning with loading best model at the end by @BenjaminBossan in #35087
* Cleanup: continue the init refactor by @LysandreJik in #35170
* Fix CI by @Cyrilvallez in #35208
* Fix seamless TTS generate by @ylacombe in #34968
* docs: clarify initializer_range parameter description in Idefics3VisionConfig by @h3110Fr13nd in #35215
* Fixed typo of 'indentifier' in audio_utils.py by @Uvi-12 in #35226
* Fix type hints for apply_chat_template by @Rocketknight1 in #35216
* Support Python 3.10+ Union style in chat template type hints parsing by @RezaRahemtola in #35103
* Refactoring `AssistedCandidateGenerator` for Improved Modularity and Reusability by @keyboardAnt and @jmamou in #35009
* Change back to `Thread` for SF conversion by @ydshieh in #35236
* [Init refactor] Modular changes by @LysandreJik in #35240
* Fix typo in chat template example by @EricWinsorDSIT in #35250
* Run model as compressed/uncompressed mode by @horheynm in #34719
* skip Fuyu from test_generate by @nhamanasu in #35246
* [tests] fix "Tester object has no attribute '_testMethodName'" by @faaany in #34910
* Use `rsfE` with `pytest` by @ydshieh in #35119
* Update AMD docker image (rocm 6.1) by @ivarflakstad in #35259
* Fixed typos in Audio Classification Documentation by @Uvi-12 in #35263
* Translating agents_advanced.md to Chinese by @HMJ0628 in #35231
* Fix FSDP no longer working by @muellerzr in #35212
* don't use no_sync when deepspeed doesn't support it for certain zero stages by @winglian in #35157
* [i18n-Chinese] Translating perf_train_cpu.md to Chinese by @asdkfjsd in #35242
* Fall back to slow image processor in ImageProcessingAuto when no fast processor available by @yonigozlan in #34785
* Aggeregate test summary files in CircleCI workflow runs by @ydshieh in #34989
* Blip: fix offloading and MP tests by @zucchini-nlp in #35239
* Fix : model used to test ggml conversion of Falcon-7b is incorrect by @MekkCyber in #35083
* Temporarily disable amd push ci by @ivarflakstad in #35293
* Delete redundancy for loop checks. by @zhanluxianshen in #35288
* [Whisper] patch float type on mps by @eustlb in #35295
* Fix typos in Translated Audio Classification Docs by @jla524 in #35287
* Translating "translate perf_infer_gpu_multi.md" to Chinese by @HMJ0628 in #35271
* Fix wrongs in quicktour[zh] by @zhanluxianshen in #35272
* Improved documentation of Automatic speech recognition by @Uvi-12 in #35268
* fix modular order by @ArthurZucker in #35297
* Add sdpa for Beit by @OmarManzoor in #34941
* Support for SDPA for SAM models by @MagnusS0 in #34110
* remove `benchmark` job in `push-important-models.yml` by @ydshieh in #35292
* Fix typos in translated quicktour docs by @jla524 in #35302
* Fix image preview in multi-GPU inference docs by @jla524 in #35303
* Fix remove unused parameter in docs by @zzzzzsa in #35306
* Add Cohere2 docs details by @alexrs-cohere in #35294
* Fixed typo in audio_classification.md by @Uvi-12 in #35305
* [docs] Improve register_pipeline by @stevhliu in #35300
* Fix loading with only state dict and low_cpu_mem_usage = True by @SunMarc in #35217
* [tests] make cuda-only tests device-agnostic by @faaany in #35222
* Trigger GitHub CI with a comment on PR by @ydshieh in #35211
* change bnb tests by @jiqing-feng in #34713
* [Whisper] fix docstrings typo by @eustlb in #35319
* feat: add `benchmarks_entrypoint.py` by @McPatate in #34495
* Fix documentation for ColPali by @tonywu71 in #35321
* Update comment CI bot by @ydshieh in #35323
* PaliGemma: Make sure to add to suffix if is present in `text` by @probicheaux in #35201
* Fix some fa2 tests by @ArthurZucker in #35340
* Modernbert Release Fixes by @warner-benjamin in #35344
* [`docs`] Add link to ModernBERT Text Classification GLUE finetuning script by @tomaarsen in #35347
* fix onnx export of speech foundation models by @nikosanto13 in #34224
* [`Mamba2`] Fix caching, slow path, and multi-gpu by @vasqu in #35154
* Reduce CircleCI usage by @ydshieh in #35355
* Implement AsyncTextIteratorStreamer for asynchronous streaming by @CISC in #34931
* Cleaner attention interfaces by @Cyrilvallez in #35342
* Add Tensor Parallel support for Qwen2VL by @jla524 in #35050
* fix zoedepth initialization error under deepspeed zero3 by @Tavish9 in #35011
* Aurevoir PyTorch 1 by @ydshieh in #35358
* bugfix: torch.export failure caused by `_make_causal_mask` by @jiwoong-choi in #35291
* update codecarbon by @nhamanasu in #35243
* Update test fetcher when we want to test all by @ArthurZucker in #35364
* Use `weights_only=True` with `torch.load` for `transfo_xl` by @ydshieh in #35241
* Make `test_generate_with_static_cache` even less flaky by @ydshieh in #34995
* Improve modular transformers documentation by @joelpaulkoch in #35322
* Improved Documentation Of Audio Classification by @Uvi-12 in #35368
* [docs] Follow up register_pipeline by @stevhliu in #35310
* owlvit/2 dynamic input resolution by @bastrob in #34764
* Fix new FA2 if `is_causal` is passed explicitly by @Cyrilvallez in #35390
* bitsandbytes: simplify 8bit dequantization by @matthewdouglas in #35068
* make LlamaModel._update_causal_mask torch compilable by @winglian in #35187
* Patch GPTNeoX to use adequate FA2 if position_ids is provided by @taha-yassine in #35318
* uniformize kwargs for SAM by @tibor-reiss in #34578
* Deprecate _is_quantized_training_enabled by @MekkCyber in #34991
* Scale loss before backward by @qgallouedec in #35207
* Fix typing in docstring for `PaliGemmaProcessor` by @alvarobartt in #35278
* Fix : VPTQ test by @MekkCyber in #35394
* add bnb support for Ascend NPU by @statelesshz in #31512
* bugfix Idefics3 processor - handle gracefully cases with text and no images by @mfarre in #35363
* Adding logger.info about update_torch_dtype in some quantizers by @MekkCyber in #35046
* Add compile test for fast image processor by @yonigozlan in #35184
* Disable `.github/workflows/self-comment-ci.yml` for now by @ydshieh in #35366
* enable non-cuda awq model support without modify version by @jiqing-feng in #35334
* [`GPTQ`, `CompressedTensors`] Fix unsafe imports and metada check by @vasqu in #34815
* Drop inplace operation for loss computation with gradient accumulation by @qgallouedec in #35416
* Fix: Rename keyword argument in_channels to num_channels by @ningyuv in #35289
* CLIP conversion script - Change fairseq to OpenAI by @gau-nernst in #35384
* Fix f-string to show `ACCELERATE_MIN_VERSION` on error by @KSafran in #35189
* Fix `model_accepts_loss_kwargs` for timm model by @qubvel in #35257
* Update perf_infer_gpu_one.md: fix a typo by @martin0258 in #35441
* Add compute_loss_func to Seq2SeqTrainer by @d223302 in #35136
* Update docs for `sdpa_kernel` by @jla524 in #35410
* [i18n-ar] Translated file: `docs/source/ar/tasks/question_answering.md` into Arabic by @AhmedAlmaghz in #35196
* [i18n-ar] Translated file: `docs/source/ar/tasks/summarization.md` into Arabic by @AhmedAlmaghz in #35195
* Update translated docs for `sdpa_kernel` by @jla524 in #35461
* Reintroduce Python 3.9 support for ModernBERT by @tomaarsen in #35458
* Fix new BNB test failures by @matthewdouglas in #35345
* Fix docs typos. by @zhanluxianshen in #35465
* Fix paligemma warning message by @hiyouga in #35486
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @ydshieh
* Fix private forked repo. CI (#35114)
* Change back to `Thread` for SF conversion (#35236)
* Use `rsfE` with `pytest` (#35119)
* Aggeregate test summary files in CircleCI workflow runs (#34989)
* remove `benchmark` job in `push-important-models.yml` (#35292)
* Trigger GitHub CI with a comment on PR (#35211)
* Update comment CI bot (#35323)
* Reduce CircleCI usage (#35355)
* Aurevoir PyTorch 1 (#35358)
* Use `weights_only=True` with `torch.load` for `transfo_xl` (#35241)
* Make `test_generate_with_static_cache` even less flaky (#34995)
* Disable `.github/workflows/self-comment-ci.yml` for now (#35366)
* @aymeric-roucher
* Add Aria (#34157)
* @NielsRogge
* [I-JEPA] Update docs (#35148)
* Add DINOv2 with registers (#35348)
* @HMJ0628
* [i18n-] Translating agents.md to Chinese (#35139)
* Translating agents_advanced.md to Chinese (#35231)
* Translating "translate perf_infer_gpu_multi.md" to Chinese (#35271)
* @alexrs-cohere
* Add Cohere2 model (#35224)
* Add Cohere2 docs details (#35294)
* @ArthurZucker
* fix modular order (#35297)
* 🚨All attention refactor🚨 (#35235)
* Fix some fa2 tests (#35340)
* Update test fetcher when we want to test all (#35364)
* @tonywu71
* Add ColPali to 🤗 transformers (#33736)
* Fix documentation for ColPali (#35321)
* @OmarManzoor
* Add sdpa for Beit (#34941)
* @fabianlim
* Add the Bamba Model (#34982)
* @warner-benjamin
* Add ModernBERT to Transformers (#35158)
* Modernbert Release Fixes (#35344)
* @wejoncy
* FEAT : Adding VPTQ quantization method to HFQuantizer (#34770)
* @bastrob
* owlvit/2 dynamic input resolution (#34764)
* @BlackSamorez
* HIGGS Quantization Support (#34997)
v4.47.1 (2024-12-17)
# Patch release v4.47.1
We waited a little bit to make sure it was stable, thanks @winglian for double checking and everyone for the fixes!
* Fix GA loss bugs and add unit test (#35121)
Contributed by @techkang and @ArthurZucker.
* Fix num_items_in_batch not being an integer (#35115))
Contributed by @xspirus.
* Fix FSDP no longer working (#35212)
Contributed by @muellerzr.
* Don't use no_sync when DeepSpeed doesn't support it for certain ZeRO configurations (#35212)
Contributed by @winglian.
* Only import torch.distributed if it is available (#35133)
Contributed by @GaetanLepage.
* [Whisper] Patch float type on MPS (#35295)
Contributed by @eustlb. 🔜 we should probably have MPS CIs to avoid repeating this!
v4.47.0: PaliGemma-2, I-JEPA, OLMo-2, LayerSkip, Tensor Parallel (2024-12-05)
## New models
### PaliGemma-2
PaliGemma 2 and PaliGemma are lightweight open vision-language models (VLM) inspired by [PaLI-3](https://arxiv.org/abs/2310.09199), and based on open components like the [SigLIP vision model](https://arxiv.org/abs/2303.15343) and the [Gemma language model](https://arxiv.org/abs/2403.08295). PaliGemma takes both images and text as inputs and can answer questions about images with detail and context, meaning that PaliGemma can perform deeper analysis of images and provide useful insights, such as captioning for images and short videos, object detection, and reading text embedded within images.
PaliGemma 2 is available in 3B, 10B, and 28B parameter sizes, which are based on Gemma 2 2B, 9B, and 27B models, respectively. The original PaliGemma models are available in the 3B size. For more information on Gemma model variants, see the [Gemma models list](https://ai.google.dev/gemma/docs/get_started#models-list). PaliGemma model variants support different pixel resolutions for image inputs, including 224 x 224, 448 x 448, and 896 x 896 pixels.
 ### I-JEPA
The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://arxiv.org/pdf/2301.08243.pdf) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas. I-JEPA is a self-supervised learning method that predicts the representations of one part of an image based on other parts of the same image. This approach focuses on learning semantic features without relying on pre-defined invariances from hand-crafted data transformations, which can bias specific tasks, or on filling in pixel-level details, which often leads to less meaningful representations.
### I-JEPA
The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://arxiv.org/pdf/2301.08243.pdf) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas. I-JEPA is a self-supervised learning method that predicts the representations of one part of an image based on other parts of the same image. This approach focuses on learning semantic features without relying on pre-defined invariances from hand-crafted data transformations, which can bias specific tasks, or on filling in pixel-level details, which often leads to less meaningful representations.
 * Add I-JEPA by @jmtzt in #33125
### OLMo 2
* Add I-JEPA by @jmtzt in #33125
### OLMo 2
 The OLMo2 model is the successor of the OLMo model, which was proposed in [OLMo: Accelerating the Science of Language Models](https://arxiv.org/abs/2402.00838).
The architectural changes from the original OLMo model to this model are:
- RMSNorm is used instead of standard layer norm.
- Norm is applied to attention queries and keys.
- Norm is applied after attention/feedforward layers rather than before.
Commits:
* Add OLMo November 2024 by @2015aroras in #34551
* Rename OLMo November to OLMo2 by @2015aroras in #34864
### Layer-Skip Llama
We add support for Meta's Layer-Skip Llama 3.2 1B model.
The Llama3.2 1B model was continually pretrained with LayerSkip recipe, early exit loss and layer dropout, as presented in [Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding](https://arxiv.org/abs/2404.16710) and is capable of performing self-speculative decoding: decode with earlier layers and verify with remaining layers.
The OLMo2 model is the successor of the OLMo model, which was proposed in [OLMo: Accelerating the Science of Language Models](https://arxiv.org/abs/2402.00838).
The architectural changes from the original OLMo model to this model are:
- RMSNorm is used instead of standard layer norm.
- Norm is applied to attention queries and keys.
- Norm is applied after attention/feedforward layers rather than before.
Commits:
* Add OLMo November 2024 by @2015aroras in #34551
* Rename OLMo November to OLMo2 by @2015aroras in #34864
### Layer-Skip Llama
We add support for Meta's Layer-Skip Llama 3.2 1B model.
The Llama3.2 1B model was continually pretrained with LayerSkip recipe, early exit loss and layer dropout, as presented in [Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding](https://arxiv.org/abs/2404.16710) and is capable of performing self-speculative decoding: decode with earlier layers and verify with remaining layers.
 * Self-speculation (Layer-Skip Llama) by @ArthurZucker in #34240
## Tensor Parallel implementation
This PR uses the `torch.distributed.tensor.parallel` subpackage to implement Tensor Parallel for Llama (as an example).
The motivation is multi-fold:
1. to make modeling code simple as single-worker case:
all manual TP implementations under `if self.config.pretraining_tp > 1` can be removed.
2. to make tensor parallelism easily accessible by users:
added a `model.tensor_parallel(device_mesh)` method that allows users to turn a single-proc model into a parallel model. !- Please guide me to a right place to put this function/method if `PreTrainedModel` is not a preferred place. -!
This is the first PR of many to simplify and enable Tensor Parallel across models.
* Simplify Tensor Parallel implementation with PyTorch TP by @kwen2501 in #34184
## Farewell, Python 3.8
Python 3.8 reaches end of life, and, as such, we drop it from our CI.
* Drop support for Python 3.8 by @ydshieh in #34314
## GGUF improvements
Several improvements have been done to the GGUF support in transformers; notably by adding new architectures to the list of supported architectures.
* Add T5 GGUF loading support by @junejae in #33389
* Add GGUF for Mamba by @VladOS95-cyber in #34200
* Add Nemotron GGUF Loading Support by @farrosalferro in #34725
* Improve gguf tensor processing by @VladOS95-cyber in #34515
* Fix `use_parallel_residual` and `qkv_bias` for StableLM GGUF config extraction by @Isotr0py in #34450
### Fast processors
We continue the work to improve the speed of fast processors as detailed in this [roadmap](https://www.notion.so/huggingface2/OptimVision-Optimize-preprocessing-time-10f1384ebcac8091a12debb87fe5f591).
We contribute a fast processor to RT-DETR.
* Add Image Processor Fast RT-DETR by @yonigozlan in #34354
### New pipelines
A new pipeline has been added to transformers: image-text-to-text!
the pipeline support the following inputs:
- unbatched images and text - images=image, text=text
- batched images and text - images = [image, image], text= [text, text]
- several images per prompt (only for models supporting the use of an image token) - images = [[image, image], [image]] or images=[image, image, image], text = ["... ......", "......"]
- Chat templates (for models supporting them).
* Add image text to text pipeline by @yonigozlan in #34170
### Notable refactors
### Separate chat templates into a single file
We have had several issues with chat templates because they're stored as single lines in the JSON config files:
- Impossible to review diffs
- Very hard to edit in the web UI (or in general)
- Differences between `processor` templates in `chat_template.json` and `tokenizer` templates in `tokenizer_config.json` causing confusion
- Some models use multiple templates, requiring a template dict, but we're trying to discourage that in future and move those models to single templates with conditional behaviour instead
The solution:
- Just move chat templates to a single `chat_template.jinja` file in the repo
- If multiple templates are required, then they should still be stored in the JSON file. This is not supported for `Processor` classes, so processors should always be able to save their template as a raw Jinja file. In general, we'll be gently deprecating multiple templates in future.
- If a `chat_template.jinja` file is present, it overrides the JSON files. If a tokenizer is loaded with both Jinja and JSON chat templates and resaved, it should save only the Jinja file, and not have any `chat_template` entry in `tokenizer_config.json`.
For now, we continue saving in the old format by default. I'll probably keep it this way for several versions before making the new format the default, to ensure that most users are able to load the new format before it becomes common. Until then, the new format should mostly be used for testing, to make sure it's ready for deployment when we do the switch.
* Separate chat templates into a single file by @Rocketknight1 in #33957
### Large modular logic refactor
This PR largely rework the logic we use in the modular converter. It is (hopefully) clearer and maintainable. Instead of going in all directions, adding stuff, then deleting it if not needed, we now do the following:
- visit all the modular file (record imports/functions/classes/assignments nodes)
- create function dependency mapping
- for each import coming from another model:
- visit the corresponding file
- create function dependency mapping
- update mapping with function/assignment from the modular (updated/new functions)
- create the class dependency graph based on merged dependencies
- update dependency graph of the modular with the functions and assignments imported from the other files
- for each class recorded in the modular:
- if inherithing from class in another file:
- replace call to super
- find the dependencies after the node was replaced
- follow (updated with modular defs) dependency mapping to add all nodes
- else:
- only add needed imported functions (and their dependencies)
- determine the needed imports and add them
* Large modular logic refactoring by @Cyrilvallez in #34487
## Community bugfixes and improvements
* Remove graph breaks for torch.compile() in flash_attention_forward when Lllama Model is padding free tuned by @Abhishek-TAMU in #33932
* Better defaults by @ArthurZucker in #34026
* translated gguf.md into chinese by @blueingman in #34163
* CI: fix failures by @zucchini-nlp in #34371
* Zamba is an LM by @LysandreJik in #34342
* add code generation to natural language processing section by @furtnerthomas in #34333
* Fix pil_torch_interpolation_mapping import in image_processing_detr_fast by @yonigozlan in #34375
* Add code sample docstrings and checkpoint reference for GLM models by @h3110Fr13nd in #34360
* refactor: remove redundant if-condition and improve type correctness for `convert_tokens_to_ids` by @winstxnhdw in #34030
* Ignore unsupported kwarg in ProcessorMixin call by @yonigozlan in #34285
* [PEFT] Add warning for missing key in LoRA adapter by @BenjaminBossan in #34068
* Fix `torch.fx` issue related to the new `loss_kwargs` keyword argument by @michaelbenayoun in #34380
* Correct the new defaults by @Cyrilvallez in #34377
* [auto. ping] Avoid sending empty info + add more team members by @ydshieh in #34383
* Fix glm by @Cyrilvallez in #34388
* Use non nested images and batched text Idefics2/3 by @yonigozlan in #34222
* Fix onnx non-expotable inplace aten op by @IlyasMoutawwakil in #34376
* Fix right padding in LLaVA models by @zucchini-nlp in #34305
* no filter by @ydshieh in #34391
* SynthID: better example by @gante in #34372
* Tests: upgrade `test_eager_matches_sdpa_generate` by @gante in #34386
* Fix bnb training test failure by @matthewdouglas in #34414
* Avoid check expected exception when it is on CUDA by @ydshieh in #34408
* Fix typos in agents_advanced.md by @rudydel in #34405
* [docs] Cache implementations by @stevhliu in #34325
* Fix pix2struct by @IlyasMoutawwakil in #34374
* pin `tensorflow_probability<0.22` in docker files by @ydshieh in #34381
* Tiny update after #34383 by @ydshieh in #34404
* Fix batch size handling in prediction_loop for DataLoaderShard by @zeus2611 in #34343
* exclude fsdp from delay_optimizer_creation by @eljandoubi in #34140
* New option called `"best"` for `args.save_strategy`. by @seanswyi in #31817
* [docs] update input documentation for MAMBA2 and MISTRAL models to include cache_position and attention_mask details by @h3110Fr13nd in #34322
* 🌐 [i18n-KO] Translated `model_doc/barthez.md` to Korean by @Jwaminju in #33980
* Apply linting to the important code blocks to make it readable by @ShubhamJagtap2000 in #34449
* Torchao weights only + prequantized compability by @SunMarc in #34355
* [i18n-ar] Translated file : `docs/source/ar/fast_tokenizers.md` into Arabic by @AhmedAlmaghz in #33034
* enable average tokens across devices by @techkang in #34373
* feat: run benchmarks on A100 by @McPatate in #34287
* Add `post_process_depth_estimation` for GLPN by @alex-bene in #34413
* LLaVA: latency issues by @zucchini-nlp in #34460
* Generation: fix test by @zucchini-nlp in #34369
* Fix CI by @zucchini-nlp in #34458
* use a tinymodel to test generation config which aviod timeout by @techkang in #34482
* 🚨🚨🚨 [SuperPoint] Fix keypoint coordinate output and add post processing by @sbucaille in #33200
* Simplify running tests in a subprocess by @ydshieh in #34213
* Fix perplexity computation in perplexity.md by @Framartin in #34387
* Fixes for Modular Converter on Windows by @hlky in #34266
* Fix regression loading dtype by @SunMarc in #34409
* Bert is ExecuTorch compatible by @guangy10 in #34424
* manual `head_dim` for `mixtral` model by @wavy-jung in #34281
* fix-qwen2vl-no-position_ids by @simonJJJ in #33487
* Bug fix for drop path decay rate in swin transformer by @abhi-glitchhg in #34291
* MobileBERT is ExecuTorch compatible by @guangy10 in #34473
* Albert is ExecuTorch compatible by @guangy10 in #34476
* Adding `optimizer_cls_and_kwargs` to `Trainer.__init__` by @apoorvkh in #34358
* Fix performance in get_imports regexp by @AlekseyLobanov in #34298
* fix incorrect warning by @yonigozlan in #34416
* Un-deprecate timeout arg in pipelines by @Rocketknight1 in #34382
* Roberta is ExecuTorch compatible by @guangy10 in #34425
* Fix format mistake in string repr of tokenizer objects by @gpetho in #34493
* Mllama: update docs by @zucchini-nlp in #34334
* VLMs: fix number of image tokens by @zucchini-nlp in #34332
* Tests: move `generate` tests to the right mixin and delete redundant tests by @gante in #34464
* fix pixtral processor by @molbap in #34486
* Use torch 2.5 in scheduled CI by @ydshieh in #34465
* Fix super tiny extra space typo by @fzyzcjy in #34440
* UPDATE Documentation for #TRANSLATING.md Documentation into Multiple Languages.(Changes made) by @anshumangahlot in #34226
* enable QA bf16 pipeline by @jiqing-feng in #34483
* Fix: img size mismatch caused by incorrect unpadding in LLaVA-Next by @jp1924 in #34522
* Fix step shifting when accumulate gradient by @kibitzing in #33673
* avoid calling `gc.collect` and `cuda.empty_cache` by @ydshieh in #34514
* Qwen2VL: skip base `input_ids`-`inputs_embeds` equivalence check by @gante in #34535
* fix(DPT,Depth-Anything) Address expected_slice errors inside inference tests by @philkuz in #34518
* feat: add benchmarks pg indexes by @McPatate in #34536
* make `test_eager_matches_sdpa_inference `less flaky by @ydshieh in #34512
* Bug Fix for issue #34294 by @fpgaminer in #34295
* [CLIPSeg] Make interpolate_pos_encoding default to True by @NielsRogge in #34419
* update doc by @jiqing-feng in #34478
* [i18n-ar] Translated file : `docs/source/ar/multilingual.md` into Arabic by @AhmedAlmaghz in #33048
* Blip: get/set input embeddings correctly by @zucchini-nlp in #34152
* BLIP: enable generation tests by @zucchini-nlp in #34174
* :red_circle: :red_circle: fix `query_pre_attn_scalar` different of `num_heads` in default gemma2 config by @molbap in #34540
* [i18n-HI] Translated accelerate page to Hindi by @karthik-script in #34443
* Update trainer for easier handling of accumulate, compile fixes, and proper reporting by @muellerzr in #34511
* VLM: special multimodal Tokenizer by @zucchini-nlp in #34461
* MPS: `isin_mps_friendly` can support 0D tensors by @gante in #34538
* Add text support to the Trainer's TensorBoard integration by @JacobLinCool in #34418
* [i18n-HI] Translated TFLite page to Hindi by @karthik-script in #34572
* 🌐 [i18n-KO] Translated perf_train_special.md to Korean by @maximizemaxwell in #34590
* 🌐 [i18n-KO] Update README_ko.md by @J4BEZ in #33098
* fix TrainerState doc because num_input_tokens_seen is unused by defau… by @techkang in #34593
* Fix Whisper CI by @ydshieh in #34541
* Skip DeepSpeed ZeRO Stage 3 model initialization when bnb by @eljandoubi in #34395
* FIX: Broken repr of TorchAoConfig by @BenjaminBossan in #34560
* Load sub-configs from composite configs by @zucchini-nlp in #34410
* DistilBERT is ExecuTorch compatible by @guangy10 in #34475
* Remove unused test_dataset by @thisisiron in #34516
* Revert "Fix Whisper CI" by @ydshieh in #34605
* Fix #34494 assistant tokens when truncated by @yonigottesman in #34531
* Remove `@slow` for `test_eager_matches_sdpa_inference` by @ydshieh in #34558
* Changing __repr__ in torchao to show quantized Linear by @MekkCyber in #34202
* Fix torchvision interpolation CI by @yonigozlan in #34539
* 🌐 [i18n-KO] Translated `convbert.md` to Korean by @ahnjj in #34599
* fix(dvclive): pass fake dataset to avoid exception in trainer init by @shcheklein in #34455
* 🌐 [i18n-KO] Translated `timesformer.md` to Korean by @mreraser in #33972
* 🌐 [i18n-KO] Translated bert.md to Korean by @maximizemaxwell in #34627
* [i18n-ar] Translated file : `docs/source/ar/trainer.md` into Arabic by @AhmedAlmaghz in #33080
* Update llm_engine.py by @louisbrulenaudet in #33332
* Agents: turn any Space into a Tool with `Tool.from_space()` by @aymeric-roucher in #34561
* [docs] update not-working model revision by @faaany in #34682
* [i18n-ar] Translated file : `docs/source/ar/torchscript.md` into Arabic by @AhmedAlmaghz in #33079
* Agents: Small fixes in streaming to gradio + add tests by @aymeric-roucher in #34549
* 🌐 [i18n-KO] Translated marian.md to Korean by @maximizemaxwell in #34698
* [docs] Broken link in generation_strategies by @pcuenca in #34717
* Fix example in EsmConfig docstring by @yuanx749 in #34653
* [docs] add xpu device check by @faaany in #34684
* Retain newlines in chat template when `continue_final_message=True` by @lewtun in #34253
* Update llava.md by @LysandreJik in #34749
* fix(wandb): pass fake dataset to avoid exception in trainer (see #34455) by @CezaPasc in #34720
* add xpu path for awq by @jiqing-feng in #34712
* FSDP grad accum fix by @winglian in #34645
* Remove FSDP wrapping from sub-models. by @eljandoubi in #34452
* 🧼 remove v4.44 deprecations by @gante in #34245
* VLMs: `patch_size` -> `num_image_tokens` in processing by @zucchini-nlp in #33424
* Fix broken link by @ofek in #34618
* fix a typo bug where 'id2label' was incorrectly written as 'i2label' when reading config by @ZuoChenFttS in #34637
* Fix skip of test_training_gradient_checkpointing by @dvrogozh in #34723
* make sure to disable gradients for integer tensor by @winglian in #32943
* [docs] make `empty_cache` device-agnostic by @faaany in #34774
* [docs] add XPU besides CUDA, MPS etc. by @faaany in #34777
* [tests] add XPU part to testing by @faaany in #34778
* fix: Update pixel_values parameter in hf_model input by @thisisiron in #34782
* Fix callback key name by @jung-hunsoo in #34762
* fix: Wrong task mentioned in docs by @ecyht2 in #34757
* Allow handling files as args for a tool created with Tool.from_space by @aymeric-roucher in #34687
* Fix Whisper CI by @ydshieh in #34617
* protect tensor parallel usage by @ArthurZucker in #34800
* Trainer hyperparameter search kwargs docs update by @GuillemGSubies in #34459
* feat: allow to use hf-hub models for timm backbone by @cgebbe in #34729
* Support gradient checkpointing in Qwen2VL ViT by @li-plus in #34724
* Fix: siglip image processor rgb_convert is not being applied correctly. by @jp1924 in #34301
* fix cpu bnb path by @jiqing-feng in #34647
* Gemma capping by @ArthurZucker in #34282
* Fix cache_utils for optimum.quanto kvcache quantization by @SunMarc in #34750
* Modular fix by @Cyrilvallez in #34802
* MLU devices : Checks if mlu is available via an cndev-based check which won't trigger the drivers and leave mlu by @huismiling in #34326
* 🚨🚨🚨 fix(Mask2Former): torch export 🚨🚨🚨 by @philkuz in #34393
* Feature: print tokens per second during training by @tibor-reiss in #34507
* Add do_convert_rgb to vit by @jp1924 in #34523
* Fix post process function called in the instance segmentation example of mask2former by @OnTheThirdDay in #34588
* fix crash in tiiuae/falcon-11B-vlm image-to-text generation by @sywangyi in #34728
* Add support for OpenAI api "image_url" input in chat for image-text-to-text pipeline by @yonigozlan in #34562
* Add Image Processor Fast Deformable DETR by @yonigozlan in #34353
* Run `test_medium_seamless_m4t_pt` in `subprocess` to avoid many failures by @ydshieh in #34812
* Fix `check_training_gradient_checkpointing` by @ydshieh in #34806
* Added image-text-to-text pipeline to task guide by @merveenoyan in #34783
* Translate attention.md into Chinese by @wwwbai in #34716
* LLaVA OV: fix unpadding precision by @zucchini-nlp in #34779
* Fix low memory beam search by @zucchini-nlp in #34746
* Fix the memory usage issue of logits in generate() by @kjohew in #34813
* fix(DPT,Depth-Anything) `torch.export` by @philkuz in #34103
* Fix: take into account meta device by @tibor-reiss in #34134
* Fix hyperparameter search when optuna+deepseed by @corentin-ryr in #34642
* Fix CI by tweaking torchao tests by @SunMarc in #34832
* Fix CI slack reporting issue by @ydshieh in #34833
* VLMs: enable generation tests - last batch by @zucchini-nlp in #34484
* Change logging level from warning to info for `max_steps` overriding `num_train_epochs` by @qgallouedec in #34810
* Fix ds nvme by @eljandoubi in #34444
* Fix heuristic scheduling for UAG by @jmamou in #34805
* Refactor StarCoder2 using modular by @Cyrilvallez in #34015
* Watermarking: fix order by @zucchini-nlp in #34849
* Update checks for torch.distributed.tensor to require torch >= 2.5 by @loadams in #34816
* Remove quantization related config from dequantized model by @konradkalita in #34856
* Auto compile when static cache by @ArthurZucker in #34247
* Speculative decoding: Test the target distribution (to prevent issues like #32867) by @keyboardAnt in #34553
* smol improvements to support more flexible usage by @andimarafioti in #34857
* [CI] Skip EETQ tests while package is broken with latest transformers by @BenjaminBossan in #34854
* Bitnet test fix to avoid using gated model by @MekkCyber in #34863
* Fix support for image processors modifications in modular by @yonigozlan in #34866
* Fix: Enable prefill phase key value caching of nemotron/minitron models by @jeongin601 in #34742
* Add safe_globals to resume training on PyTorch 2.6 by @dvrogozh in #34632
* Cache: init empty cache when `use_cache` by @zucchini-nlp in #34274
* BLIP: fix generation after hub update by @zucchini-nlp in #34876
* [`Deberta/Deberta-v2`] Refactor code base to support compile, export, and fix LLM by @ArthurZucker in #22105
* 🔴 Mllama: fix base prefix by @zucchini-nlp in #34874
* Sum gathered input tokens by @techkang in #34554
* allow unused input parameters passthrough when chunking in asr pipelines by @VictorAtIfInsurance in #33889
* prepare_fa2_from_position_ids function bugfix by @meliksahturker in #33269
* chore: fix some typos by @wanxiangchwng in #34891
* Fix convert_tokens_to_string when decoder is None by @dszeto in #34569
* [`peft`] Given that `self.active_adapter` is deprecated, avoid using it by @tomaarsen in #34804
* Fix Qwen2 failing tests by @jla524 in #34819
* Fix : BitNet tests by @MekkCyber in #34895
* [AWQ, CI] Bump AWQ version used in docker image by @BenjaminBossan in #34922
* fix static cache data type miss-match by @jiqing-feng in #34799
* Fix `test_auto_backbone_timm_model_from_pretrained` by @ydshieh in #34877
* Upgrade torch version to 2.5 in dockerfile for quantization CI by @MekkCyber in #34924
* Fix failling GGML test by @MekkCyber in #34871
* Updated documentation and added conversion utility by @ViktorooReps in #34319
* making gpt2 fx traceable by @xuzifei-dmatrix in #34633
* Fix import structure for Fast Image processors by @yonigozlan in #34859
* VideoLLaVA: add default values by @zucchini-nlp in #34916
* Skipping aqlm non working inference tests till fix merged by @MekkCyber in #34865
* [Whisper] Fix whisper integration tests by @eustlb in #34111
* Add Pytorch Tensor Parallel support for Mistral by @VladOS95-cyber in #34927
* change apply_rotary_pos_emb of Glmmodel for GLM-Edge Series model by @zRzRzRzRzRzRzR in #34629
* Fix torch.onnx.export of Qwen2-VL vision encoder by @xenova in #34852
* Update the Python version in the Chinese README to match the English README. by @vansin in #34870
* [i18n-ar] Translated file : `docs/source/ar/benchmarks.md` into Arabic by @AhmedAlmaghz in #33023
* [docs] use device-agnostic API instead of cuda by @faaany in #34913
* [doc] use full path for run_qa.py by @faaany in #34914
* docs: HUGGINGFACE_HUB_CACHE -> HF_HUB_CACHE by @imba-tjd in #34904
* [i18n-zh]Translated tiktoken.md into chinese by @blueingman in #34936
* [`FlexAttention`] Update gemma2 by @ArthurZucker in #34942
* Fix : Add PEFT from source to CI docker by @MekkCyber in #34969
* Avoid calling `get_max_length` by @ydshieh in #34971
* Fix flaky test execution caused by `Thread` by @ydshieh in #34966
* 🌐 [i18n-KO] Translated encoder-decoder.md to Korean by @maximizemaxwell in #34880
* [docs] add explanation to `release_memory()` by @faaany in #34911
* [i18n-zh]Translated perf_train_special.md into Chinese by @blueingman in #34948
* Fix typo in code block in vipllava.md by @yuanx749 in #34957
* Fixed typo in `VisitWebpageTool` by @sergiopaniego in #34978
* [PEFT] Set eval mode when loading PEFT adapter by @BenjaminBossan in #34509
* Fix `save_pretrained` for partially offloaded models by @kylesayrs in #34890
* 🚨🚨🚨 Changed DINOv2Config default patch size to 14 by @OFSkean in #34568
* Refine the code of Universal Assisted Generation by @xinpengzz in #34823
* Allow compressed-tensors quantized model to be trained by @horheynm in #34520
* Offloaded cache: fix generate by @zucchini-nlp in #34921
* Fix `utils/check_bad_commit.py` (for auto ping in CI) by @ydshieh in #34943
* Add optimized `PixtralImageProcessorFast` by @mgoin in #34836
* Improve `.from_pretrained` type annotations by @qubvel in #34973
* Fix docker CI : install autogptq from source by @MekkCyber in #35000
* Let server decide default repo visibility by @Wauplin in #34999
* 🚨🚨🚨 Uniformize kwargs for TrOCR Processor by @tibor-reiss in #34587
* Update timm version by @qubvel in #35005
* fix: double verbs by @SamuelLarkin in #35008
* Update `FillMaskPipeline.__call__` signature and docstring by @alvarobartt in #35006
* Only cast `cu_seqlens` when tracing by @xenova in #35016
* fix variable undefined bug when return_tensors is not specified in llava processing by @chenweize1998 in #34953
* Optimize memory usage of mllama encoder by @milesial in #34930
* Typo in warning switching to optimum-quanto by @Bojun-Feng in #35028
* Add type hints for forward functions in Gemma2 by @jla524 in #35034
* Fix `test_eager_matches_sdpa_inference` for `XPU` backend by @dvrogozh in #34889
* Multiple typo fixes in Tutorials docs by @henryhmko in #35035
* add docstring example for compute_loss_func by @secrettoad in #35020
* [i18n-ar] Translated file : `docs/source/ar/notebooks.md` into Arabic by @AhmedAlmaghz in #33049
* [docs] add the missing import for Image and bug fix by @faaany in #34776
* Translate bertlogy.md into Chinese by @wwwbai in #34908
* Automatic compilation in generate: do not rely on inner function by @Cyrilvallez in #34923
* Add token cost + runtime monitoring to Agent and HfEngine children by @aymeric-roucher in #34548
* Fix `BertGeneration` by @ydshieh in #35043
* fix speecht5 failure issue in test_peft_gradient_checkpointing_enable… by @sywangyi in #34454
* [docs] fix example code bug by @faaany in #35054
* Translate community.md into Chinese by @wwwbai in #35013
* [docs] use device-agnostic instead of `cuda` by @faaany in #35047
* [docs] use device-agnostic API instead of hard-coded cuda by @faaany in #35048
* Fix `pad_token_tensor` is None in warning by @tshu-w in #34005
* Add Pytorch Tensor Parallel support for Qwen2, Qwen2Moe, Starcoder2 by @VladOS95-cyber in #35007
* [`GPTNeoX`] Flex Attention + Refactor by @vasqu in #34896
* Support for easier multimodal use of modular by @Cyrilvallez in #35056
* [docs] add a comment that offloading requires CUDA GPU by @faaany in #35055
* [docs] Increase visibility of torch_dtype="auto" by @stevhliu in #35067
* Informative by @ydshieh in #35059
* [Whisper] Fix whisper tokenizer by @eustlb in #34537
* [`tokenizers`] bump to 0.21 by @ArthurZucker in #34972
* Update Mistral conversion script by @Cyrilvallez in #34829
* Fix `tie_word_embeddings` handling for GGUF models by @Isotr0py in #35085
* Deprecate quanto and switch to optimum-quanto by @MekkCyber in #35001
* BLIP: this is correct now by @zucchini-nlp in #35081
* [`trainer`] fix the GA `model_accepts_loss_kwargs` by @ArthurZucker in #34915
* Fix flaky Hub CI (`test_trainer.py`) by @ydshieh in #35062
* Adaptive dynamic number of speculative tokens by @jmamou in #34156
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @AhmedAlmaghz
* [i18n-ar] Translated file : `docs/source/ar/fast_tokenizers.md` into Arabic (#33034)
* [i18n-ar] Translated file : `docs/source/ar/multilingual.md` into Arabic (#33048)
* [i18n-ar] Translated file : `docs/source/ar/trainer.md` into Arabic (#33080)
* [i18n-ar] Translated file : `docs/source/ar/torchscript.md` into Arabic (#33079)
* [i18n-ar] Translated file : `docs/source/ar/benchmarks.md` into Arabic (#33023)
* @maximizemaxwell
* 🌐 [i18n-KO] Translated perf_train_special.md to Korean (#34590)
* 🌐 [i18n-KO] Translated bert.md to Korean (#34627)
* 🌐 [i18n-KO] Translated marian.md to Korean (#34698)
* 🌐 [i18n-KO] Translated encoder-decoder.md to Korean (#34880)
* @2015aroras
* Add OLMo November 2024 (#34551)
* Rename OLMo November to OLMo2 (#34864)
* @mgoin
* Add optimized `PixtralImageProcessorFast` (#34836)
* Self-speculation (Layer-Skip Llama) by @ArthurZucker in #34240
## Tensor Parallel implementation
This PR uses the `torch.distributed.tensor.parallel` subpackage to implement Tensor Parallel for Llama (as an example).
The motivation is multi-fold:
1. to make modeling code simple as single-worker case:
all manual TP implementations under `if self.config.pretraining_tp > 1` can be removed.
2. to make tensor parallelism easily accessible by users:
added a `model.tensor_parallel(device_mesh)` method that allows users to turn a single-proc model into a parallel model. !- Please guide me to a right place to put this function/method if `PreTrainedModel` is not a preferred place. -!
This is the first PR of many to simplify and enable Tensor Parallel across models.
* Simplify Tensor Parallel implementation with PyTorch TP by @kwen2501 in #34184
## Farewell, Python 3.8
Python 3.8 reaches end of life, and, as such, we drop it from our CI.
* Drop support for Python 3.8 by @ydshieh in #34314
## GGUF improvements
Several improvements have been done to the GGUF support in transformers; notably by adding new architectures to the list of supported architectures.
* Add T5 GGUF loading support by @junejae in #33389
* Add GGUF for Mamba by @VladOS95-cyber in #34200
* Add Nemotron GGUF Loading Support by @farrosalferro in #34725
* Improve gguf tensor processing by @VladOS95-cyber in #34515
* Fix `use_parallel_residual` and `qkv_bias` for StableLM GGUF config extraction by @Isotr0py in #34450
### Fast processors
We continue the work to improve the speed of fast processors as detailed in this [roadmap](https://www.notion.so/huggingface2/OptimVision-Optimize-preprocessing-time-10f1384ebcac8091a12debb87fe5f591).
We contribute a fast processor to RT-DETR.
* Add Image Processor Fast RT-DETR by @yonigozlan in #34354
### New pipelines
A new pipeline has been added to transformers: image-text-to-text!
the pipeline support the following inputs:
- unbatched images and text - images=image, text=text
- batched images and text - images = [image, image], text= [text, text]
- several images per prompt (only for models supporting the use of an image token) - images = [[image, image], [image]] or images=[image, image, image], text = ["... ......", "......"]
- Chat templates (for models supporting them).
* Add image text to text pipeline by @yonigozlan in #34170
### Notable refactors
### Separate chat templates into a single file
We have had several issues with chat templates because they're stored as single lines in the JSON config files:
- Impossible to review diffs
- Very hard to edit in the web UI (or in general)
- Differences between `processor` templates in `chat_template.json` and `tokenizer` templates in `tokenizer_config.json` causing confusion
- Some models use multiple templates, requiring a template dict, but we're trying to discourage that in future and move those models to single templates with conditional behaviour instead
The solution:
- Just move chat templates to a single `chat_template.jinja` file in the repo
- If multiple templates are required, then they should still be stored in the JSON file. This is not supported for `Processor` classes, so processors should always be able to save their template as a raw Jinja file. In general, we'll be gently deprecating multiple templates in future.
- If a `chat_template.jinja` file is present, it overrides the JSON files. If a tokenizer is loaded with both Jinja and JSON chat templates and resaved, it should save only the Jinja file, and not have any `chat_template` entry in `tokenizer_config.json`.
For now, we continue saving in the old format by default. I'll probably keep it this way for several versions before making the new format the default, to ensure that most users are able to load the new format before it becomes common. Until then, the new format should mostly be used for testing, to make sure it's ready for deployment when we do the switch.
* Separate chat templates into a single file by @Rocketknight1 in #33957
### Large modular logic refactor
This PR largely rework the logic we use in the modular converter. It is (hopefully) clearer and maintainable. Instead of going in all directions, adding stuff, then deleting it if not needed, we now do the following:
- visit all the modular file (record imports/functions/classes/assignments nodes)
- create function dependency mapping
- for each import coming from another model:
- visit the corresponding file
- create function dependency mapping
- update mapping with function/assignment from the modular (updated/new functions)
- create the class dependency graph based on merged dependencies
- update dependency graph of the modular with the functions and assignments imported from the other files
- for each class recorded in the modular:
- if inherithing from class in another file:
- replace call to super
- find the dependencies after the node was replaced
- follow (updated with modular defs) dependency mapping to add all nodes
- else:
- only add needed imported functions (and their dependencies)
- determine the needed imports and add them
* Large modular logic refactoring by @Cyrilvallez in #34487
## Community bugfixes and improvements
* Remove graph breaks for torch.compile() in flash_attention_forward when Lllama Model is padding free tuned by @Abhishek-TAMU in #33932
* Better defaults by @ArthurZucker in #34026
* translated gguf.md into chinese by @blueingman in #34163
* CI: fix failures by @zucchini-nlp in #34371
* Zamba is an LM by @LysandreJik in #34342
* add code generation to natural language processing section by @furtnerthomas in #34333
* Fix pil_torch_interpolation_mapping import in image_processing_detr_fast by @yonigozlan in #34375
* Add code sample docstrings and checkpoint reference for GLM models by @h3110Fr13nd in #34360
* refactor: remove redundant if-condition and improve type correctness for `convert_tokens_to_ids` by @winstxnhdw in #34030
* Ignore unsupported kwarg in ProcessorMixin call by @yonigozlan in #34285
* [PEFT] Add warning for missing key in LoRA adapter by @BenjaminBossan in #34068
* Fix `torch.fx` issue related to the new `loss_kwargs` keyword argument by @michaelbenayoun in #34380
* Correct the new defaults by @Cyrilvallez in #34377
* [auto. ping] Avoid sending empty info + add more team members by @ydshieh in #34383
* Fix glm by @Cyrilvallez in #34388
* Use non nested images and batched text Idefics2/3 by @yonigozlan in #34222
* Fix onnx non-expotable inplace aten op by @IlyasMoutawwakil in #34376
* Fix right padding in LLaVA models by @zucchini-nlp in #34305
* no filter by @ydshieh in #34391
* SynthID: better example by @gante in #34372
* Tests: upgrade `test_eager_matches_sdpa_generate` by @gante in #34386
* Fix bnb training test failure by @matthewdouglas in #34414
* Avoid check expected exception when it is on CUDA by @ydshieh in #34408
* Fix typos in agents_advanced.md by @rudydel in #34405
* [docs] Cache implementations by @stevhliu in #34325
* Fix pix2struct by @IlyasMoutawwakil in #34374
* pin `tensorflow_probability<0.22` in docker files by @ydshieh in #34381
* Tiny update after #34383 by @ydshieh in #34404
* Fix batch size handling in prediction_loop for DataLoaderShard by @zeus2611 in #34343
* exclude fsdp from delay_optimizer_creation by @eljandoubi in #34140
* New option called `"best"` for `args.save_strategy`. by @seanswyi in #31817
* [docs] update input documentation for MAMBA2 and MISTRAL models to include cache_position and attention_mask details by @h3110Fr13nd in #34322
* 🌐 [i18n-KO] Translated `model_doc/barthez.md` to Korean by @Jwaminju in #33980
* Apply linting to the important code blocks to make it readable by @ShubhamJagtap2000 in #34449
* Torchao weights only + prequantized compability by @SunMarc in #34355
* [i18n-ar] Translated file : `docs/source/ar/fast_tokenizers.md` into Arabic by @AhmedAlmaghz in #33034
* enable average tokens across devices by @techkang in #34373
* feat: run benchmarks on A100 by @McPatate in #34287
* Add `post_process_depth_estimation` for GLPN by @alex-bene in #34413
* LLaVA: latency issues by @zucchini-nlp in #34460
* Generation: fix test by @zucchini-nlp in #34369
* Fix CI by @zucchini-nlp in #34458
* use a tinymodel to test generation config which aviod timeout by @techkang in #34482
* 🚨🚨🚨 [SuperPoint] Fix keypoint coordinate output and add post processing by @sbucaille in #33200
* Simplify running tests in a subprocess by @ydshieh in #34213
* Fix perplexity computation in perplexity.md by @Framartin in #34387
* Fixes for Modular Converter on Windows by @hlky in #34266
* Fix regression loading dtype by @SunMarc in #34409
* Bert is ExecuTorch compatible by @guangy10 in #34424
* manual `head_dim` for `mixtral` model by @wavy-jung in #34281
* fix-qwen2vl-no-position_ids by @simonJJJ in #33487
* Bug fix for drop path decay rate in swin transformer by @abhi-glitchhg in #34291
* MobileBERT is ExecuTorch compatible by @guangy10 in #34473
* Albert is ExecuTorch compatible by @guangy10 in #34476
* Adding `optimizer_cls_and_kwargs` to `Trainer.__init__` by @apoorvkh in #34358
* Fix performance in get_imports regexp by @AlekseyLobanov in #34298
* fix incorrect warning by @yonigozlan in #34416
* Un-deprecate timeout arg in pipelines by @Rocketknight1 in #34382
* Roberta is ExecuTorch compatible by @guangy10 in #34425
* Fix format mistake in string repr of tokenizer objects by @gpetho in #34493
* Mllama: update docs by @zucchini-nlp in #34334
* VLMs: fix number of image tokens by @zucchini-nlp in #34332
* Tests: move `generate` tests to the right mixin and delete redundant tests by @gante in #34464
* fix pixtral processor by @molbap in #34486
* Use torch 2.5 in scheduled CI by @ydshieh in #34465
* Fix super tiny extra space typo by @fzyzcjy in #34440
* UPDATE Documentation for #TRANSLATING.md Documentation into Multiple Languages.(Changes made) by @anshumangahlot in #34226
* enable QA bf16 pipeline by @jiqing-feng in #34483
* Fix: img size mismatch caused by incorrect unpadding in LLaVA-Next by @jp1924 in #34522
* Fix step shifting when accumulate gradient by @kibitzing in #33673
* avoid calling `gc.collect` and `cuda.empty_cache` by @ydshieh in #34514
* Qwen2VL: skip base `input_ids`-`inputs_embeds` equivalence check by @gante in #34535
* fix(DPT,Depth-Anything) Address expected_slice errors inside inference tests by @philkuz in #34518
* feat: add benchmarks pg indexes by @McPatate in #34536
* make `test_eager_matches_sdpa_inference `less flaky by @ydshieh in #34512
* Bug Fix for issue #34294 by @fpgaminer in #34295
* [CLIPSeg] Make interpolate_pos_encoding default to True by @NielsRogge in #34419
* update doc by @jiqing-feng in #34478
* [i18n-ar] Translated file : `docs/source/ar/multilingual.md` into Arabic by @AhmedAlmaghz in #33048
* Blip: get/set input embeddings correctly by @zucchini-nlp in #34152
* BLIP: enable generation tests by @zucchini-nlp in #34174
* :red_circle: :red_circle: fix `query_pre_attn_scalar` different of `num_heads` in default gemma2 config by @molbap in #34540
* [i18n-HI] Translated accelerate page to Hindi by @karthik-script in #34443
* Update trainer for easier handling of accumulate, compile fixes, and proper reporting by @muellerzr in #34511
* VLM: special multimodal Tokenizer by @zucchini-nlp in #34461
* MPS: `isin_mps_friendly` can support 0D tensors by @gante in #34538
* Add text support to the Trainer's TensorBoard integration by @JacobLinCool in #34418
* [i18n-HI] Translated TFLite page to Hindi by @karthik-script in #34572
* 🌐 [i18n-KO] Translated perf_train_special.md to Korean by @maximizemaxwell in #34590
* 🌐 [i18n-KO] Update README_ko.md by @J4BEZ in #33098
* fix TrainerState doc because num_input_tokens_seen is unused by defau… by @techkang in #34593
* Fix Whisper CI by @ydshieh in #34541
* Skip DeepSpeed ZeRO Stage 3 model initialization when bnb by @eljandoubi in #34395
* FIX: Broken repr of TorchAoConfig by @BenjaminBossan in #34560
* Load sub-configs from composite configs by @zucchini-nlp in #34410
* DistilBERT is ExecuTorch compatible by @guangy10 in #34475
* Remove unused test_dataset by @thisisiron in #34516
* Revert "Fix Whisper CI" by @ydshieh in #34605
* Fix #34494 assistant tokens when truncated by @yonigottesman in #34531
* Remove `@slow` for `test_eager_matches_sdpa_inference` by @ydshieh in #34558
* Changing __repr__ in torchao to show quantized Linear by @MekkCyber in #34202
* Fix torchvision interpolation CI by @yonigozlan in #34539
* 🌐 [i18n-KO] Translated `convbert.md` to Korean by @ahnjj in #34599
* fix(dvclive): pass fake dataset to avoid exception in trainer init by @shcheklein in #34455
* 🌐 [i18n-KO] Translated `timesformer.md` to Korean by @mreraser in #33972
* 🌐 [i18n-KO] Translated bert.md to Korean by @maximizemaxwell in #34627
* [i18n-ar] Translated file : `docs/source/ar/trainer.md` into Arabic by @AhmedAlmaghz in #33080
* Update llm_engine.py by @louisbrulenaudet in #33332
* Agents: turn any Space into a Tool with `Tool.from_space()` by @aymeric-roucher in #34561
* [docs] update not-working model revision by @faaany in #34682
* [i18n-ar] Translated file : `docs/source/ar/torchscript.md` into Arabic by @AhmedAlmaghz in #33079
* Agents: Small fixes in streaming to gradio + add tests by @aymeric-roucher in #34549
* 🌐 [i18n-KO] Translated marian.md to Korean by @maximizemaxwell in #34698
* [docs] Broken link in generation_strategies by @pcuenca in #34717
* Fix example in EsmConfig docstring by @yuanx749 in #34653
* [docs] add xpu device check by @faaany in #34684
* Retain newlines in chat template when `continue_final_message=True` by @lewtun in #34253
* Update llava.md by @LysandreJik in #34749
* fix(wandb): pass fake dataset to avoid exception in trainer (see #34455) by @CezaPasc in #34720
* add xpu path for awq by @jiqing-feng in #34712
* FSDP grad accum fix by @winglian in #34645
* Remove FSDP wrapping from sub-models. by @eljandoubi in #34452
* 🧼 remove v4.44 deprecations by @gante in #34245
* VLMs: `patch_size` -> `num_image_tokens` in processing by @zucchini-nlp in #33424
* Fix broken link by @ofek in #34618
* fix a typo bug where 'id2label' was incorrectly written as 'i2label' when reading config by @ZuoChenFttS in #34637
* Fix skip of test_training_gradient_checkpointing by @dvrogozh in #34723
* make sure to disable gradients for integer tensor by @winglian in #32943
* [docs] make `empty_cache` device-agnostic by @faaany in #34774
* [docs] add XPU besides CUDA, MPS etc. by @faaany in #34777
* [tests] add XPU part to testing by @faaany in #34778
* fix: Update pixel_values parameter in hf_model input by @thisisiron in #34782
* Fix callback key name by @jung-hunsoo in #34762
* fix: Wrong task mentioned in docs by @ecyht2 in #34757
* Allow handling files as args for a tool created with Tool.from_space by @aymeric-roucher in #34687
* Fix Whisper CI by @ydshieh in #34617
* protect tensor parallel usage by @ArthurZucker in #34800
* Trainer hyperparameter search kwargs docs update by @GuillemGSubies in #34459
* feat: allow to use hf-hub models for timm backbone by @cgebbe in #34729
* Support gradient checkpointing in Qwen2VL ViT by @li-plus in #34724
* Fix: siglip image processor rgb_convert is not being applied correctly. by @jp1924 in #34301
* fix cpu bnb path by @jiqing-feng in #34647
* Gemma capping by @ArthurZucker in #34282
* Fix cache_utils for optimum.quanto kvcache quantization by @SunMarc in #34750
* Modular fix by @Cyrilvallez in #34802
* MLU devices : Checks if mlu is available via an cndev-based check which won't trigger the drivers and leave mlu by @huismiling in #34326
* 🚨🚨🚨 fix(Mask2Former): torch export 🚨🚨🚨 by @philkuz in #34393
* Feature: print tokens per second during training by @tibor-reiss in #34507
* Add do_convert_rgb to vit by @jp1924 in #34523
* Fix post process function called in the instance segmentation example of mask2former by @OnTheThirdDay in #34588
* fix crash in tiiuae/falcon-11B-vlm image-to-text generation by @sywangyi in #34728
* Add support for OpenAI api "image_url" input in chat for image-text-to-text pipeline by @yonigozlan in #34562
* Add Image Processor Fast Deformable DETR by @yonigozlan in #34353
* Run `test_medium_seamless_m4t_pt` in `subprocess` to avoid many failures by @ydshieh in #34812
* Fix `check_training_gradient_checkpointing` by @ydshieh in #34806
* Added image-text-to-text pipeline to task guide by @merveenoyan in #34783
* Translate attention.md into Chinese by @wwwbai in #34716
* LLaVA OV: fix unpadding precision by @zucchini-nlp in #34779
* Fix low memory beam search by @zucchini-nlp in #34746
* Fix the memory usage issue of logits in generate() by @kjohew in #34813
* fix(DPT,Depth-Anything) `torch.export` by @philkuz in #34103
* Fix: take into account meta device by @tibor-reiss in #34134
* Fix hyperparameter search when optuna+deepseed by @corentin-ryr in #34642
* Fix CI by tweaking torchao tests by @SunMarc in #34832
* Fix CI slack reporting issue by @ydshieh in #34833
* VLMs: enable generation tests - last batch by @zucchini-nlp in #34484
* Change logging level from warning to info for `max_steps` overriding `num_train_epochs` by @qgallouedec in #34810
* Fix ds nvme by @eljandoubi in #34444
* Fix heuristic scheduling for UAG by @jmamou in #34805
* Refactor StarCoder2 using modular by @Cyrilvallez in #34015
* Watermarking: fix order by @zucchini-nlp in #34849
* Update checks for torch.distributed.tensor to require torch >= 2.5 by @loadams in #34816
* Remove quantization related config from dequantized model by @konradkalita in #34856
* Auto compile when static cache by @ArthurZucker in #34247
* Speculative decoding: Test the target distribution (to prevent issues like #32867) by @keyboardAnt in #34553
* smol improvements to support more flexible usage by @andimarafioti in #34857
* [CI] Skip EETQ tests while package is broken with latest transformers by @BenjaminBossan in #34854
* Bitnet test fix to avoid using gated model by @MekkCyber in #34863
* Fix support for image processors modifications in modular by @yonigozlan in #34866
* Fix: Enable prefill phase key value caching of nemotron/minitron models by @jeongin601 in #34742
* Add safe_globals to resume training on PyTorch 2.6 by @dvrogozh in #34632
* Cache: init empty cache when `use_cache` by @zucchini-nlp in #34274
* BLIP: fix generation after hub update by @zucchini-nlp in #34876
* [`Deberta/Deberta-v2`] Refactor code base to support compile, export, and fix LLM by @ArthurZucker in #22105
* 🔴 Mllama: fix base prefix by @zucchini-nlp in #34874
* Sum gathered input tokens by @techkang in #34554
* allow unused input parameters passthrough when chunking in asr pipelines by @VictorAtIfInsurance in #33889
* prepare_fa2_from_position_ids function bugfix by @meliksahturker in #33269
* chore: fix some typos by @wanxiangchwng in #34891
* Fix convert_tokens_to_string when decoder is None by @dszeto in #34569
* [`peft`] Given that `self.active_adapter` is deprecated, avoid using it by @tomaarsen in #34804
* Fix Qwen2 failing tests by @jla524 in #34819
* Fix : BitNet tests by @MekkCyber in #34895
* [AWQ, CI] Bump AWQ version used in docker image by @BenjaminBossan in #34922
* fix static cache data type miss-match by @jiqing-feng in #34799
* Fix `test_auto_backbone_timm_model_from_pretrained` by @ydshieh in #34877
* Upgrade torch version to 2.5 in dockerfile for quantization CI by @MekkCyber in #34924
* Fix failling GGML test by @MekkCyber in #34871
* Updated documentation and added conversion utility by @ViktorooReps in #34319
* making gpt2 fx traceable by @xuzifei-dmatrix in #34633
* Fix import structure for Fast Image processors by @yonigozlan in #34859
* VideoLLaVA: add default values by @zucchini-nlp in #34916
* Skipping aqlm non working inference tests till fix merged by @MekkCyber in #34865
* [Whisper] Fix whisper integration tests by @eustlb in #34111
* Add Pytorch Tensor Parallel support for Mistral by @VladOS95-cyber in #34927
* change apply_rotary_pos_emb of Glmmodel for GLM-Edge Series model by @zRzRzRzRzRzRzR in #34629
* Fix torch.onnx.export of Qwen2-VL vision encoder by @xenova in #34852
* Update the Python version in the Chinese README to match the English README. by @vansin in #34870
* [i18n-ar] Translated file : `docs/source/ar/benchmarks.md` into Arabic by @AhmedAlmaghz in #33023
* [docs] use device-agnostic API instead of cuda by @faaany in #34913
* [doc] use full path for run_qa.py by @faaany in #34914
* docs: HUGGINGFACE_HUB_CACHE -> HF_HUB_CACHE by @imba-tjd in #34904
* [i18n-zh]Translated tiktoken.md into chinese by @blueingman in #34936
* [`FlexAttention`] Update gemma2 by @ArthurZucker in #34942
* Fix : Add PEFT from source to CI docker by @MekkCyber in #34969
* Avoid calling `get_max_length` by @ydshieh in #34971
* Fix flaky test execution caused by `Thread` by @ydshieh in #34966
* 🌐 [i18n-KO] Translated encoder-decoder.md to Korean by @maximizemaxwell in #34880
* [docs] add explanation to `release_memory()` by @faaany in #34911
* [i18n-zh]Translated perf_train_special.md into Chinese by @blueingman in #34948
* Fix typo in code block in vipllava.md by @yuanx749 in #34957
* Fixed typo in `VisitWebpageTool` by @sergiopaniego in #34978
* [PEFT] Set eval mode when loading PEFT adapter by @BenjaminBossan in #34509
* Fix `save_pretrained` for partially offloaded models by @kylesayrs in #34890
* 🚨🚨🚨 Changed DINOv2Config default patch size to 14 by @OFSkean in #34568
* Refine the code of Universal Assisted Generation by @xinpengzz in #34823
* Allow compressed-tensors quantized model to be trained by @horheynm in #34520
* Offloaded cache: fix generate by @zucchini-nlp in #34921
* Fix `utils/check_bad_commit.py` (for auto ping in CI) by @ydshieh in #34943
* Add optimized `PixtralImageProcessorFast` by @mgoin in #34836
* Improve `.from_pretrained` type annotations by @qubvel in #34973
* Fix docker CI : install autogptq from source by @MekkCyber in #35000
* Let server decide default repo visibility by @Wauplin in #34999
* 🚨🚨🚨 Uniformize kwargs for TrOCR Processor by @tibor-reiss in #34587
* Update timm version by @qubvel in #35005
* fix: double verbs by @SamuelLarkin in #35008
* Update `FillMaskPipeline.__call__` signature and docstring by @alvarobartt in #35006
* Only cast `cu_seqlens` when tracing by @xenova in #35016
* fix variable undefined bug when return_tensors is not specified in llava processing by @chenweize1998 in #34953
* Optimize memory usage of mllama encoder by @milesial in #34930
* Typo in warning switching to optimum-quanto by @Bojun-Feng in #35028
* Add type hints for forward functions in Gemma2 by @jla524 in #35034
* Fix `test_eager_matches_sdpa_inference` for `XPU` backend by @dvrogozh in #34889
* Multiple typo fixes in Tutorials docs by @henryhmko in #35035
* add docstring example for compute_loss_func by @secrettoad in #35020
* [i18n-ar] Translated file : `docs/source/ar/notebooks.md` into Arabic by @AhmedAlmaghz in #33049
* [docs] add the missing import for Image and bug fix by @faaany in #34776
* Translate bertlogy.md into Chinese by @wwwbai in #34908
* Automatic compilation in generate: do not rely on inner function by @Cyrilvallez in #34923
* Add token cost + runtime monitoring to Agent and HfEngine children by @aymeric-roucher in #34548
* Fix `BertGeneration` by @ydshieh in #35043
* fix speecht5 failure issue in test_peft_gradient_checkpointing_enable… by @sywangyi in #34454
* [docs] fix example code bug by @faaany in #35054
* Translate community.md into Chinese by @wwwbai in #35013
* [docs] use device-agnostic instead of `cuda` by @faaany in #35047
* [docs] use device-agnostic API instead of hard-coded cuda by @faaany in #35048
* Fix `pad_token_tensor` is None in warning by @tshu-w in #34005
* Add Pytorch Tensor Parallel support for Qwen2, Qwen2Moe, Starcoder2 by @VladOS95-cyber in #35007
* [`GPTNeoX`] Flex Attention + Refactor by @vasqu in #34896
* Support for easier multimodal use of modular by @Cyrilvallez in #35056
* [docs] add a comment that offloading requires CUDA GPU by @faaany in #35055
* [docs] Increase visibility of torch_dtype="auto" by @stevhliu in #35067
* Informative by @ydshieh in #35059
* [Whisper] Fix whisper tokenizer by @eustlb in #34537
* [`tokenizers`] bump to 0.21 by @ArthurZucker in #34972
* Update Mistral conversion script by @Cyrilvallez in #34829
* Fix `tie_word_embeddings` handling for GGUF models by @Isotr0py in #35085
* Deprecate quanto and switch to optimum-quanto by @MekkCyber in #35001
* BLIP: this is correct now by @zucchini-nlp in #35081
* [`trainer`] fix the GA `model_accepts_loss_kwargs` by @ArthurZucker in #34915
* Fix flaky Hub CI (`test_trainer.py`) by @ydshieh in #35062
* Adaptive dynamic number of speculative tokens by @jmamou in #34156
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @AhmedAlmaghz
* [i18n-ar] Translated file : `docs/source/ar/fast_tokenizers.md` into Arabic (#33034)
* [i18n-ar] Translated file : `docs/source/ar/multilingual.md` into Arabic (#33048)
* [i18n-ar] Translated file : `docs/source/ar/trainer.md` into Arabic (#33080)
* [i18n-ar] Translated file : `docs/source/ar/torchscript.md` into Arabic (#33079)
* [i18n-ar] Translated file : `docs/source/ar/benchmarks.md` into Arabic (#33023)
* @maximizemaxwell
* 🌐 [i18n-KO] Translated perf_train_special.md to Korean (#34590)
* 🌐 [i18n-KO] Translated bert.md to Korean (#34627)
* 🌐 [i18n-KO] Translated marian.md to Korean (#34698)
* 🌐 [i18n-KO] Translated encoder-decoder.md to Korean (#34880)
* @2015aroras
* Add OLMo November 2024 (#34551)
* Rename OLMo November to OLMo2 (#34864)
* @mgoin
* Add optimized `PixtralImageProcessorFast` (#34836)
Patch release v4.46.3 (2024-11-18)
One small fix for FSDP + gradient accumulation loss issue!
- FSDP grad accum fix, #34645 by @winglian
Patch release v4.46.2 (2024-11-05)
# Patch release v4.46.2
Mostly had to finish the gradient accumulation !
Thanks to @techkang and @Ryukijano 🤗
- VLMs: fix number of image tokens (#34332) by @zucchini-nlp
- fix pixtral processor (#34486) by @@molbap
- enable average tokens across devices (#34373) by @techkang and @muellerzr
- Update trainer for easier handling of accumulate, compile fixes, and … by @muellerzr and @Ryukijano
- MPS: isin_mps_friendly can support 0D tensors (#34538) by @gante
Patch release v4.46.1 (2024-10-29)
# Patch release v4.4.61
This is mostly for `fx` and `onnx` issues!
** Fix regression loading dtype #34409 by @SunMarc
** LLaVa: latency issues #34460 by @zucchini-nlp
** Fix pix2struct #34374 by @IlyasMoutawwakil
** Fix onnx non-exposable inplace aten op #34376 by @IlyasMoutawwakil
** Fix torch.fx issue related to the new `loss_kwargs` keyword argument #34380 by @michaelbenayoun
Release v4.46.0 (2024-10-24)
## New model additions
### Moshi
The Moshi model was proposed in Moshi: a speech-text foundation model for real-time dialogue by Alexandre Défossez,
Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave and Neil Zeghidour.
Moshi is a speech-text foundation model that casts spoken dialogue as speech-to-speech generation. Starting from a
text language model backbone, Moshi generates speech as tokens from the residual quantizer of a neural audio codec,
while modeling separately its own speech and that of the user into parallel streams. This allows for the removal of
explicit speaker turns, and the modeling of arbitrary conversational dynamics. Moshi also predicts time-aligned text
tokens as a prefix to audio tokens. This “Inner Monologue” method significantly improves the linguistic quality of
generated speech and provides streaming speech recognition and text-to-speech. As a result, Moshi is the first
real-time full-duplex spoken large language model, with a theoretical latency of 160ms, 200ms in practice.

* Moshi integration by @ylacombe in #33624
### Zamba
Zamba-7B-v1 is a hybrid between state-space models (Specifically Mamba) and transformer, and was trained using
next-token prediction. Zamba uses a shared transformer layer after every 6 mamba blocks. It uses the Mistral
v0.1 tokenizer. We came to this architecture after a series of ablations at small scales. Zamba-7B-v1 was
pre-trained on 1T tokens of text and code data.
 * Add Zamba by @pglorio in #30950
### GLM
The GLM Model was proposed in ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools by GLM Team,
THUDM & ZhipuAI.
The abstract from the paper starts with the following:
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This
report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B.

* add Glm by @Cyrilvallez in #33823
### Idefics 3
The Idefics3 model was proposed in Building and better understanding vision-language models: insights and future directions by Hugo Laurençon, Andrés Marafioti, Victor Sanh, and Léo Tronchon.
Idefics3 is an adaptation of the Idefics2 model with three main differences:
- It uses Llama3 for the text model.
- It uses an updated processing logic for the images.
- It removes the perceiver.

* Add Idefics 3! by @andimarafioti in #32473
### PhiMoE
The PhiMoE model was proposed in Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone by Microsoft.
This model is very similar to Mixtral with the main difference of Phi3LongRoPEScaledRotaryEmbedding, where they are
used to extend the context of the rotary embeddings. The query, key and values are fused, and the MLP’s up and gate
projection layers are also fused.

* PhiMoE by @garg-amit in #33363
## Watermarking
This release adds [SynthID](https://www.nature.com/articles/s41586-024-08025-4), a novel state-of-the-art watermarking technique by Google DeepMind. SynthID has a low generation-time computational cost and can be configured to be nearly imperceptible (at the cost of harder watermarking detection). The release also comes with the code to train and run the corresponding detector, which is a machine learning model itself.
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, SynthIDTextWatermarkingConfig
tokenizer = AutoTokenizer.from_pretrained('google/gemma-2-2b', padding_side="left")
model = AutoModelForCausalLM.from_pretrained('google/gemma-2-2b')
# SynthID Text configuration
watermarking_config = SynthIDTextWatermarkingConfig(
keys=[654, 400, 836, 123, 340, 443, 597, 160, 57],
ngram_len=5,
)
# Generation with watermarking
tokenized_prompts = tokenizer(["Once upon a time, "], return_tensors="pt", padding=True)
output_sequences = model.generate(
**tokenized_prompts, watermarking_config=watermarking_config, do_sample=True, max_new_tokens=10
)
watermarked_text = tokenizer.batch_decode(output_sequences, skip_special_tokens=True)
print(watermarked_text)
```
Docs for applying SynthID watermarking: https://huggingface.co/docs/transformers/internal/generation_utils#transformers.SynthIDTextWatermarkLogitsProcessor
Docs for detecting SynthID watermarking: https://huggingface.co/docs/transformers/internal/generation_utils#transformers.SynthIDTextWatermarkDetector
* Add Zamba by @pglorio in #30950
### GLM
The GLM Model was proposed in ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools by GLM Team,
THUDM & ZhipuAI.
The abstract from the paper starts with the following:
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This
report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B.

* add Glm by @Cyrilvallez in #33823
### Idefics 3
The Idefics3 model was proposed in Building and better understanding vision-language models: insights and future directions by Hugo Laurençon, Andrés Marafioti, Victor Sanh, and Léo Tronchon.
Idefics3 is an adaptation of the Idefics2 model with three main differences:
- It uses Llama3 for the text model.
- It uses an updated processing logic for the images.
- It removes the perceiver.

* Add Idefics 3! by @andimarafioti in #32473
### PhiMoE
The PhiMoE model was proposed in Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone by Microsoft.
This model is very similar to Mixtral with the main difference of Phi3LongRoPEScaledRotaryEmbedding, where they are
used to extend the context of the rotary embeddings. The query, key and values are fused, and the MLP’s up and gate
projection layers are also fused.

* PhiMoE by @garg-amit in #33363
## Watermarking
This release adds [SynthID](https://www.nature.com/articles/s41586-024-08025-4), a novel state-of-the-art watermarking technique by Google DeepMind. SynthID has a low generation-time computational cost and can be configured to be nearly imperceptible (at the cost of harder watermarking detection). The release also comes with the code to train and run the corresponding detector, which is a machine learning model itself.
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, SynthIDTextWatermarkingConfig
tokenizer = AutoTokenizer.from_pretrained('google/gemma-2-2b', padding_side="left")
model = AutoModelForCausalLM.from_pretrained('google/gemma-2-2b')
# SynthID Text configuration
watermarking_config = SynthIDTextWatermarkingConfig(
keys=[654, 400, 836, 123, 340, 443, 597, 160, 57],
ngram_len=5,
)
# Generation with watermarking
tokenized_prompts = tokenizer(["Once upon a time, "], return_tensors="pt", padding=True)
output_sequences = model.generate(
**tokenized_prompts, watermarking_config=watermarking_config, do_sample=True, max_new_tokens=10
)
watermarked_text = tokenizer.batch_decode(output_sequences, skip_special_tokens=True)
print(watermarked_text)
```
Docs for applying SynthID watermarking: https://huggingface.co/docs/transformers/internal/generation_utils#transformers.SynthIDTextWatermarkLogitsProcessor
Docs for detecting SynthID watermarking: https://huggingface.co/docs/transformers/internal/generation_utils#transformers.SynthIDTextWatermarkDetector
 * Add SynthID (watermerking by Google DeepMind) by @gante in #34350
## Quantization
### BitNet
[BitNet](https://arxiv.org/abs/2402.17764) is an architecture introduced by Microsoft Research that uses extreme quantization, representing each parameter with only three values: -1, 0, and 1. This results in a model that uses just 1.58 bits per parameter, significantly reducing computational and memory requirements. It replaces traditional Linear layers in Multi-Head Attention and Feed-Forward Networks with specialized layers called BitLinears that use ternary precision (or even binary, in the initial version)

* FEAT : Adding BitNet quantization method to HFQuantizer by @MekkCyber in #33410
### GGUF loading in transformers
More architectures are now supported in our GGUF loader; GGUF files saved with this architecture can now
be loaded directly in transformers to be fine-tuned. We recommend using tooling from llama.cpp to requantize
the models after further training has been done.
* Add gguf support for bloom by @VladOS95-cyber in #33473
* Add falcon gguf by @g-prz in #33437
* Add gguf support for StableLM by @VladOS95-cyber in #33793
* Add gguf support for gpt2 by @VladOS95-cyber in #34044
* Add GGUF for starcoder2 by @VladOS95-cyber in #34094
## Notable improvements and additions
### Pipeline API synchronisation
We are pushing for a unified inference API across multiple libraries. As part of this, we are cleaning up the input and output signatures for our pipeline classes and deprecating some rarely-used arguments. This is still a work-in-progress, but when it's finished, `transformers` pipelines should exactly match workflows in deployment libraries like [transformers.js](https://github.com/huggingface/transformers.js) or [TGI](https://huggingface.co/docs/text-generation-inference/en/index), allowing you to seamlessly move from development to production.
* Sync video classification pipeline with huggingface_hub spec by @Rocketknight1 in #34288
* Image pipelines spec compliance by @Rocketknight1 in #33899
* Make ASR pipeline compliant with Hub spec + add tests by @Rocketknight1 in #33769
* Cleanup return_text and return_full_text options in TextGenerationPipeline by @Rocketknight1 in #33542
* Make audio classification pipeline spec-compliant and add test by @Rocketknight1 in #33730
* Sync QuestionAnsweringPipeline by @Rocketknight1 in #34039
Also, pipelines now fully support the `Processor` class, used by vision-language models. Expect full pipeline support for chatting with VLMs in the very near future!
* Make `pipeline` able to load `processor` by @qubvel in #32514
### Executorch compatibility
[ExecuTorch](https://github.com/pytorch/executorch) is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch ecosystem and supports the deployment of PyTorch models with a focus on portability, productivity, and performance.
We are collaborating with the executorch team so that 🤗 Transformers models can be exported using `torch.export`. The goal of this integration is not only to enable export but also to ensure that the exported artifact can be further lowered and optimized to run efficiently in ExecuTorch, particularly for mobile and edge use cases.
* Add SynthID (watermerking by Google DeepMind) by @gante in #34350
## Quantization
### BitNet
[BitNet](https://arxiv.org/abs/2402.17764) is an architecture introduced by Microsoft Research that uses extreme quantization, representing each parameter with only three values: -1, 0, and 1. This results in a model that uses just 1.58 bits per parameter, significantly reducing computational and memory requirements. It replaces traditional Linear layers in Multi-Head Attention and Feed-Forward Networks with specialized layers called BitLinears that use ternary precision (or even binary, in the initial version)

* FEAT : Adding BitNet quantization method to HFQuantizer by @MekkCyber in #33410
### GGUF loading in transformers
More architectures are now supported in our GGUF loader; GGUF files saved with this architecture can now
be loaded directly in transformers to be fine-tuned. We recommend using tooling from llama.cpp to requantize
the models after further training has been done.
* Add gguf support for bloom by @VladOS95-cyber in #33473
* Add falcon gguf by @g-prz in #33437
* Add gguf support for StableLM by @VladOS95-cyber in #33793
* Add gguf support for gpt2 by @VladOS95-cyber in #34044
* Add GGUF for starcoder2 by @VladOS95-cyber in #34094
## Notable improvements and additions
### Pipeline API synchronisation
We are pushing for a unified inference API across multiple libraries. As part of this, we are cleaning up the input and output signatures for our pipeline classes and deprecating some rarely-used arguments. This is still a work-in-progress, but when it's finished, `transformers` pipelines should exactly match workflows in deployment libraries like [transformers.js](https://github.com/huggingface/transformers.js) or [TGI](https://huggingface.co/docs/text-generation-inference/en/index), allowing you to seamlessly move from development to production.
* Sync video classification pipeline with huggingface_hub spec by @Rocketknight1 in #34288
* Image pipelines spec compliance by @Rocketknight1 in #33899
* Make ASR pipeline compliant with Hub spec + add tests by @Rocketknight1 in #33769
* Cleanup return_text and return_full_text options in TextGenerationPipeline by @Rocketknight1 in #33542
* Make audio classification pipeline spec-compliant and add test by @Rocketknight1 in #33730
* Sync QuestionAnsweringPipeline by @Rocketknight1 in #34039
Also, pipelines now fully support the `Processor` class, used by vision-language models. Expect full pipeline support for chatting with VLMs in the very near future!
* Make `pipeline` able to load `processor` by @qubvel in #32514
### Executorch compatibility
[ExecuTorch](https://github.com/pytorch/executorch) is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch ecosystem and supports the deployment of PyTorch models with a focus on portability, productivity, and performance.
We are collaborating with the executorch team so that 🤗 Transformers models can be exported using `torch.export`. The goal of this integration is not only to enable export but also to ensure that the exported artifact can be further lowered and optimized to run efficiently in ExecuTorch, particularly for mobile and edge use cases.
 * Generate using exported model and enable gemma2-2b in ExecuTorch by @guangy10 in #33707
* Qwen2.5 is ExecuTorch Compatible by @guangy10 in #34102
* Olmo is ExecuTorch Compatible by @guangy10 in #34181
* Llama3 and Llama2 are ExecuTorch compatible by @guangy10 in #34101
### Gradient accumulation bugfix
* Fix Gradient Accumulation issue by @ArthurZucker in #34191
* Enable users to use their own loss functions + deal with prefetching for grad accum by @muellerzr in #34198
* Enable Gradient Accumulation fix across all models + trainer fully in forward() by @muellerzr #34283
## Bugfixes and improvements
* adding positional encoder changes and tests by @manuelsh in #32600
* Uniformize kwargs for chameleon processor by @leloykun in #32181
* [`MllamaProcessor`] Update errors and API with multiple image by @ArthurZucker in #33715
* fix: use correct var names for check_tokenizers script by @niqodea in #33702
* Fix docs and docstrings Omdet-Turbo by @yonigozlan in #33726
* Fix position embeddings singular/plural by @molbap in #33678
* Generate: `can_generate()` recursive check by @gante in #33718
* clean_up_tokenization_spaces=False if unset by @itazap in #31938
* fix: add docstring for `image_size` in Convnextv2 config by @lucianosrp in #33734
* Fix modular model converter unable to generate Processor classes by @tonywu71 in #33737
* fix trainer tr_loss add error by @Wang-Xiaodong1899 in #33651
* Update Albumentations Versions by @vasqu in #33704
* Doc and config mismatch for DeBERTa by @fkrasnov2 in #33713
* [`clean_up_tokenization_spaces`] Pl bart was failing, updating by @ArthurZucker in #33735
* [`MllamaImageProcessing`] Update doc by @ArthurZucker in #33747
* Make siglip examples clearer and error free by @jbn in #33667
* Paligemma support for multi-image by @zucchini-nlp in #33447
* remove warning v2 by @itazap in #33761
* Model addition timeline by @LysandreJik in #33762
* Fix typing in `load_balancing_loss_func` function of `modeling_mixtral.py`. by @PhilipMay in #33641
* Enable non-safetensor ser/deser for TorchAoConfig quantized model 🔴 by @jerryzh168 in #33456
* Fix typo in documentation by @qgallouedec in #33805
* Hqq serialization by @mobicham in #33141
* Add Slow CI reminder bot by @ydshieh in #33506
* [`modular`] fixes! by @ArthurZucker in #33820
* Fix ViT-MAE decoder interpolate by @xenova in #33330
* Fixes for issue #33763 in idefics2 model by @aroun-coumar in #33766
* Fix link in gguf.md by @pogpog in #33768
* minor typo fix by @a-r-r-o-w in #33784
* Fix Mamba slow path bug with dtype mismatch. by @Adibvafa in #32691
* Fix passing str dtype to static cache by @guangy10 in #33741
* fix check for hidden size in text model for deepspeed zero3 auto entries by @winglian in #33829
* post reminder comment only once by @ydshieh in #33848
* Generate: move llama `prepare_inputs_for_generation` to `GenerationMixin` by @gante in #33677
* Refactor image features selection in LlaVa by @kenza-bouzid in #33696
* fix: skip dropout in eval for flash_attn in various models by @fdschmidt93 in #33844
* add attention weight up-cast to float32 in chameleon by @francescortu in #33822
* Workaround for bark issue in pipelines by @Rocketknight1 in #33824
* Fix device mismatch errors by @zucchini-nlp in #33851
* This PR contains additional changes for #33143 by @aroun-coumar in #33581
* Raise `accelerate` dependency error in case of defaulting `low_cpu_mem_usage=True` by @kylesayrs in #33830
* Validate the eval dataset in advance. by @jackyjinjing in #33743
* Add include_loss_for_metrics by @Manalelaidouni in #33088
* Avoid using context that is not accessable from external contributors by @ydshieh in #33866
* fix: repair depth estimation multiprocessing by @niqodea in #33759
* Move weight initilization deformabledetr by @g-prz in #33339
* [Fix] ViViT interpolate_pos_encoding by @RUFFY-369 in #33815
* Repo consistency fix after #33339 by @amyeroberts in #33873
* Add support for custom inputs and batched inputs in ProcessorTesterMixin by @yonigozlan in #33711
* Fix: typo by @TrickEye in #33880
* Uniformize model processors by @molbap in #31368
* Don't run reminder bot for now by @ydshieh in #33883
* populate quantization_config for kv-cache-scheme only configs by @horheynm in #33874
* Allow for nightly packages of `compressed_tensors` by @kylesayrs in #33828
* Fix kwargs passed by AutoQuantizationConfig.from_pretrained by @kylesayrs in #33798
* Add sdpa for DistilBert by @OmarManzoor in #33724
* Trainer - deprecate tokenizer for processing_class by @amyeroberts in #32385
* [Quantization] Switch to optimum-quanto by @SunMarc in #31732
* Optim deformable detr by @yonigozlan in #33600
* Handle Trainer `tokenizer` kwarg deprecation with decorator by @qubvel in #33887
* rename all test_processing_*.py to test_processor_*.py by @yonigozlan in #33878
* uniformize processor Mllama by @yonigozlan in #33876
* Fix dt proj bias reassigned by @HofitBata in #33314
* Update an keyerror on _save_check_point prevent confusion of missing … by @fadingNA in #33832
* VLM Generate: tag `test_static_cache_matches_dynamic` as flaky by @gante in #33630
* Migrate the CI runners to the new clusters by @glegendre01 in #33849
* Fix module initialization for root module under Zero3 by @Ben-Schneider-code in #33632
* Add `SplinterTokenizer` unit test by @ariepratama in #32652
* Generate tests: modality-agnostic input preparation by @gante in #33685
* Fix: use unidic-lite instead of ipadic as the tokenizer dictionary for Japanese by @KanTakahiro in #33372
* [Tests] Diverse Whisper fixes by @ylacombe in #33665
* [PEFT] Support low_cpu_mem_usage option for PEFT loading adapters by @BenjaminBossan in #33725
* add setter for trainer processor by @ArthurZucker in #33911
* Add support for `weights_only` flag when loading state_dict by @jerryzh168 in #32481
* Config: lower `save_pretrained` exception to warning by @gante in #33906
* Uniformize kwargs for Idefics/2 processors by @yonigozlan in #32568
* Remove `logits.float()` by @ringohoffman in #33902
* Minor error condition bug fix by @htahboub in #33781
* Fix distil whisper segment computation by @ylacombe in #33920
* [Doc]: Broken link in Kubernetes doc by @saldanhad in #33879
* [i18n-ru] Fixes typo in the README_ru.md by @Artanias in #33882
* Ignore keys on `validate_rope` by @zucchini-nlp in #33753
* [`PR run-slow`] by @ArthurZucker in #33939
* Add a section on writing tool templates to the chat template docs by @Rocketknight1 in #33924
* Enables CPU AWQ model with IPEX version. by @jiqing-feng in #33460
* 🔴 🚨 Resizing tokens embeddings: initialize from old embeddings' normal distribution. by @abuelnasr0 in #33325
* Removed unnecessary transpose in Switch Transformer Routing by @karan-uppal3 in #33582
* Fix attn mask ignore logic in training-time trace by @zhenglongjiepheonix in #32613
* hot fix `self.position_embeddings->self.position_embedding` by @ArthurZucker in #33958
* fix red check-copies by @ArthurZucker in #33964
* Cache: revert DynamicCache init for BC by @gante in #33861
* Paligemma: fix static cache test by @zucchini-nlp in #33941
* Updating `char_to_token` documentation to note behaviour when `trim_offsets` is True by @Craigacp in #33919
* add test for Jamba with new model jamba-tiny-dev by @yecohn in #33863
* Bug fix gguf qwen2moe by @VladOS95-cyber in #33940
* [`TF`] Fix Tensorflow XLA Generation on limited seq_len models by @vasqu in #33903
* [WIP] Add Tokenizer for MyT5 Model by @tomlimi in #31286
* Add position ids in forward pass to opt model by @avishaiElmakies in #33121
* Flash-attn performance: remove cuda sync during inference by @Cyrilvallez in #33570
* [Docs] Improve VLM docs by @NielsRogge in #33393
* [Docs] Add Developer Guide: How to Hack Any Transformers Model by @MagnusS0 in #33979
* [`Red CIs`] Fix hub failures by @ArthurZucker in #34001
* Fix Tensor + Embedding error in some cases when using SiglipVisionModel by @kaitolucifer in #33994
* properly fix and RUN_SLOW by @ArthurZucker in #33965
* Enable customized optimizer for DeepSpeed by @dataKim1201 in #32049
* [`pytes collection`] Fix flax test collection by @ArthurZucker in #34004
* Fix undefined default_config in configuration_utils.py by @mgoin in #33934
* 🌐 [i18n-KO] Translated `gguf.md` to Korean by @yijun-lee in #33764
* 🌐 [i18n-KO] Translated `swinv2.md` to Korean by @mreraser in #33566
* 🌐 [i18n-KO] Translated `audio_utils.md` to Korean by @yijun-lee in #33802
* 🌐 [i18n-KO] Translated `esm.md` to Korean by @yijun-lee in #33796
* 🌐 [i18n-KO] Translated `time_series_utils.md` to Korean by @yijun-lee in #33806
* 🌐 [i18n-KO] Translated `pipelines_utils.md` to Korean by @yijun-lee in #33809
* 🌐 [i18n-KO] Translated `trainer.md` to Korean by @yijun-lee in #33797
* 🌐 [i18n-KO] Translated `chameleon.md` to Korean by @yijun-lee in #33799
* 🌐 [i18n-KO] Translated `logging.md` to Korean by @chhaewxn in #33543
* 🌐 [i18n-KO] Translated `auto.md` to Korean by @boyunJang in #33590
* 🌐 [i18n-KO] Translated `swin2sr.md` to Korean by @mreraser in #33795
* 🌐 [i18n-KO] Translated `vit.md` to Korean by @mreraser in #33884
* 🌐 [i18n-KO] Translated `gemma.md` to Korean by @yijun-lee in #33936
* Cache: slight change in naming by @zucchini-nlp in #32421
* Add support for __all__ and potentilly deleting functions by @ArthurZucker in #33859
* Processors: don't default padding side by @zucchini-nlp in #33942
* Add auto model for image-text-to-text by @yonigozlan in #32472
* BatchFeature.to() supports non-tensor keys by @Rocketknight1 in #33918
* Improve modular converter by @Cyrilvallez in #33991
* Fixup DeepSpeed things by @muellerzr in #34007
* Fix typing issue by @SunMarc in #34012
* fix awq tests due to ipex backend by @SunMarc in #34011
* Remove `decoder_config=None` by @SunMarc in #34014
* Fix `trainer_seq2seq.py`'s `__init__` type annotations by @benglewis in #34021
* 🌐 [i18n-KO] Translated `feature_extractor.md` to Korean by @yijun-lee in #33775
* 🌐 [i18n-KO] Translated `bertweet.md` to Korean by @ahnjj in #33891
* 🌐 [i18n-KO] Translated `gpt_neox_japanese.md` to Korean by @ahnjj in #33894
* 🌐 [i18n-KO] Translated `rag.md` to Korean by @chhaewxn in #33989
* 🌐 [i18n-KO] Translated `main_classes/quantization.md` to Korean by @fabxoe in #33959
* 🌐 [i18n-KO] Translated `main_classes/configuration.md` to Korean by @fabxoe in #33952
* 🌐 [i18n-KO] Translated `model_doc/mamba.md` to Korean by @fabxoe in #33626
* 🌐 [i18n-KO] Translated `model_doc/autoformer.md` to Korean by @fabxoe in #33574
* 🌐 [i18n-KO] Translated `model_doc/patchtsmixer.md` to Korean by @fabxoe in #33587
* 🌐 [i18n-KO] Translated `�model_doc/clip.md` to Korean by @fabxoe in #33610
* 🌐 [i18n-KO] Translated `model_doc/paligemma.md` to Korean by @fabxoe in #33612
* 🌐 [i18n-KO] Translated `model_doc/llama3.md` to Korean by @fabxoe in #33635
* 🌐 [i18n-KO] Translated `model_doc/mistral.md` to Korean by @fabxoe in #33648
* 🌐 [i18n-KO] Translated `model_doc/cohere.md` to Korean by @fabxoe in #33885
* 🌐 [i18n-KO] Translated `model_doc/dbrx.md` to Korean by @fabxoe in #33951
* 🌐 [i18n-KO] Translated `model_doc/deberta-v2.md` to Korean by @fabxoe in #33968
* 🌐 [i18n-KO] Translated `main_classes/onnx.md` to Korean by @fabxoe in #33601
* 🌐 [i18n-KO] Translated `tokenization_utils.md` to Korean by @yijun-lee in #33813
* 🌐 [i18n-KO] Translated `swin.md` to Korean by @mreraser in #33510
* 🌐 [i18n-KO] Translated `file_utils.md` to Korean by @yijun-lee in #33803
* 🌐 [i18n-KO] Translated `openai-gpt.md` to Korean by @yijun-lee in #33801
* 🌐 [i18n-KO] Translated `biogpt.md` to Korean by @yijun-lee in #33773
* 🌐 [i18n-KO] Translated `blip.md` to Korean by @cjfghk5697 in #33515
* 🌐 [i18n-KO] Translated output.md to Korean by @4N3MONE in #33607
* 🌐 [i18n-KO] Translated `image_processing_utils.md` to Korean by @yijun-lee in #33804
* 🌐 [i18n-KO] Translated `modular_transformers.md` to Korean by @yijun-lee in #33772
* [`Patch helper`] update to not have to checkout main by @ArthurZucker in #34006
* Fix Failed tests with mobile bert resize tokens embedding by @abuelnasr0 in #33950
* Generate: remove most decoder-only LLMs `prepare_inputs_for_generation` by @gante in #33870
* Mllama: fix tests by @zucchini-nlp in #34000
* Fix PIL dep for tests by @muellerzr in #34028
* 🌐 [i18n-KO] Translated `model_doc/bart.md` to Korean by @fabxoe in #33893
* 🌐 [i18n-KO] Translated `model_doc/deberta.md` to Korean by @fabxoe in #33967
* 🌐 [i18n-KO] Translated `main_classes/keras_callbacks.md` to Korean by @fabxoe in #33955
* 🌐 [i18n-KO] Translated `model_doc/mamba2.md` to Korean by @fabxoe in #33629
* 🌐 [i18n-KO] Translated `main_classes/model.md` to Korean by @fabxoe in #33606
* 🌐 [i18n-KO] Translated `model_doc/trajectory_transformer.md` to Korean by @fabxoe in #33597
* 🌐 [i18n-KO] Translated `model_doc/time_series_transformer.md` to Korean by @fabxoe in #33596
* 🌐 [i18n-KO] Translated `model_doc/informer.md` to Korean by @fabxoe in #33585
* 🌐 [i18n-KO] Translated `model_doc/graphormer.md` to Korean by @fabxoe in #33569
* 🌐 [i18n-KO] Translated `modeling_utils.md` to Korean by @yijun-lee in #33808
* 🌐 [i18n-KO] Translated `main_classes/data_collator.md` to Korean by @fabxoe in #33954
* 🌐 [i18n-KO] Translated `model_doc/patchtst.md` to Korean by @fabxoe in #33589
* 🌐 [i18n-KO] Translated `text_generation.md` to Korean by @yijun-lee in #33777
* 🌐 [i18n-KO] Translated `main_classes/callback.md` to Korean by @Jwaminju in #33572
* 🌐 [i18n-KO] Translated `generation_utils.md` to Korean by @yijun-lee in #33818
* Add Translate docs into Arabic - section files CONCEPTUAL GUIDES by @AhmedAlmaghz in #33982
* add sdpa to OPT by @avishaiElmakies in #33298
* Phi3: fix attn for sliding window by @zucchini-nlp in #33586
* HfArgumentParser: allow for hyhenated field names in long-options by @djmarti in #33990
* Fix pipelines tests by @qubvel in #34049
* Specifying torch dtype in Qwen2VLForConditionalGeneration by @htahboub in #33953
* Universal Assisted Generation: Assisted generation with any assistant model (by Intel Labs) by @danielkorat in #33383
* check if eigenvalues of covariance matrix are complex. by @abuelnasr0 in #34037
* [Docs] Update compressed_tensors.md by @mgoin in #33961
* Fix data_seed unused by @MekkCyber in #33731
* [TESTS] ASR pipeline by @ylacombe in #33925
* Update Blip2 `is_pipeline_test_to_skip` method signature by @qubvel in #34067
* provide trust_remote_code for search feat extractor in model config by @eaidova in #34036
* Small Fix to modular converter by @MekkCyber in #34051
* Default `synced_gpus` to `True` when using `FullyShardedDataParallel` by @ringohoffman in #33483
* Idefics: fix position ids by @zucchini-nlp in #33907
* Update SSH workflow file by @ydshieh in #34084
* Tests: upcast `logits` to `float()` by @gante in #34042
* Fix flax failures by @LysandreJik in #33912
* Fix DAC slow tests by @ylacombe in #34088
* Fix failing conversion by @LysandreJik in #34010
* Fix PushToHubMixin when pusing to a PR revision by @Wauplin in #34090
* avoid many failures for ImageGPT by @ydshieh in #34071
* Fix NaNs in cost_matrix for mask2former by @ducha-aiki in #34074
* Fix flaky tests by @zucchini-nlp in #34069
* Generate: move `prepare_inputs_for_generation` in encoder-decoder llms by @gante in #34048
* Avoid many test failures for `LlavaNextVideoForConditionalGeneration` by @ydshieh in #34070
* refactor: benchmarks by @McPatate in #33896
* fix(ci): benchmarks dashboard was failing due to missing quotations by @McPatate in #34100
* Generate: Fix modern llm `generate` calls with `synced_gpus` by @gante in #34095
* Mistral-related models for QnA by @vasqu in #34045
* Fix a typo by @PengWeixuan in #34148
* Fixed error message in mllama by @dmgcsilva in #34106
* Specify that users should be careful with their own files by @LysandreJik in #34153
* Add documentation for docker by @ArthurZucker in #33156
* Update README.md with Enterprise Hub by @gary149 in #34150
* Idefics: enable generation tests by @zucchini-nlp in #34062
* Add sdpa for Vivit by @RUFFY-369 in #33757
* Fix FSDP resume Initialization issue by @Itssshikhar in #34032
* Fix default behaviour in TextClassificationPipeline for regression problem type by @subhalingamd in #34066
* Generate: move `logits` to same device as `input_ids` by @gante in #34076
* Add support for inheritance from class with different suffix in modular by @yonigozlan in #34077
* Fix optuna ddp hp search by @SunMarc in #34073
* [feat] LlavaNext add feature size check to avoid CUDA Runtime Error by @laurentd-lunit in #33608
* 🌐 [i18n-KO] Translated `vivit.md` to Korean by @mreraser in #33935
* 🌐 [i18n-KO] Translated `gemma2.md` to Korean by @yijun-lee in #33937
* 🌐 [i18n-KO] Translated `trainer_utils.md` to Korean by @yijun-lee in #33817
* 🌐 [i18n-KO] Translated `blip-2.md` to Korean by @cjfghk5697 in #33516
* IDEFICS: support inputs embeds by @zucchini-nlp in #34043
* [fix] fix token healing tests and usage errors by @alpertunga-bile in #33931
* Revert `accelerate` error caused by `46d09af` by @steveepreston in #34197
* Fix wrong name for llava onevision and qwen2_vl in tokenization auto by @yonigozlan in #34177
* Avoid using torch's Tensor or PIL's Image in chat template utils if not available by @RezaRahemtola in #34165
* Revert "Fix FSDP resume Initialization issue" by @SunMarc in #34193
* Update `trainer._get_eval_sampler()` to support `group_by_length` arg by @larin92 in #33514
* Fix warning message for fp32_cpu_offloading in bitsandbytes configs by @amosyou in #34079
* Ping team members for new failed tests in daily CI by @ydshieh in #34171
* fix(Wav2Vec2ForCTC): torch export by @chrsmcgrr in #34023
* Fix for tokenizer.apply_chat_template with continue_final_message=True by @schoennenbeck in #34214
* removes decord by @vrnvu in #33987
* Fix bus error when using GPT2 on M1 macs by @chanind in #34031
* Generate: visit non-llm `prepare_inputs_for_generation` by @gante in #34199
* Support Llama 3.2 conversion (text models) by @pcuenca in #33778
* Fix-red-ci by @ArthurZucker in #34230
* BLIP: fix input expansion logic by @zucchini-nlp in #34225
* Fix broken test decorator `require_torch_up_to_2_accelerators` by @byi8220 in #34201
* Informative 2 by @LysandreJik in #34154
* Fix UDOP dtype issue by @Rocketknight1 in #34180
* Only cast logits to float when computing loss by @ringohoffman in #34147
* Generation tests: don't rely on main input name by @zucchini-nlp in #34228
* Change Paligemma import logging to work with modular by @yonigozlan in #34211
* Add DetrImageProcessorFast by @yonigozlan in #34063
* Add a doc section on writing generation prompts by @Rocketknight1 in #34248
* Fix method name which changes in tutorial by @andimarafioti in #34252
* Attn implementation for composite models by @zucchini-nlp in #32238
* VLM: add more modularity by @zucchini-nlp in #34175
* T5 compile compatibilty by @zucchini-nlp in #34089
* [docs] Fix GenerationConfig params by @stevhliu in #34299
* Fix Korean doc _toctree.yml by @regisss in #34293
* Update PR templates by @SunMarc in #34065
* [RT-DETR] Fix onnx inference bug for Optype (Where) by @YHallouard in #33877
* Fix FA2 attention for models supporting sliding window by @Cyrilvallez in #34093
* Fix: tensor of examples of the same length triggers invalid stacking by @pbelcak in #34166
* Add post_process_depth_estimation to image processors and support ZoeDepth's inference intricacies by @alex-bene in #32550
* Add option for running ffmpeg_microphone_live as a background process by @mikamerath in #32838
* Feature: Add `MLFLOW_MAX_LOG_PARAMS` to `MLflowCallback` by @cecheta in #34279
* Fix continue_final_message for image-text-to-text chat templates by @yonigozlan in #34236
* fix error in _get_eval_sampler when group_by_length enabled by @akakakakakaa in #34237
* [docs] fix typo by @faaany in #34235
* 🌐 [i18n-KO] Translated `executorch.md` to Korean by @ahnjj in #33888
* 🌐 [i18n-KO] Translated `bert japanese.md` to Korean by @ahnjj in #33890
* 🌐 [i18n-KO] Translated `model_doc/bartpho.md` to Korean by @Jwaminju in #33981
* Example doc for token classification of Llama and Dependent/Copied Models by @h3110Fr13nd in #34139
* [docs] Fix Korean toctree by @stevhliu in #34324
* Added Deberta model type support by @FilipposVentirozos in #34308
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @manuelsh
* adding positional encoder changes and tests (#32600)
* @ArthurZucker
* [`MllamaProcessor`] Update errors and API with multiple image (#33715)
* [`clean_up_tokenization_spaces`] Pl bart was failing, updating (#33735)
* [`MllamaImageProcessing`] Update doc (#33747)
* [`modular`] fixes! (#33820)
* add setter for trainer processor (#33911)
* [`PR run-slow`] (#33939)
* hot fix `self.position_embeddings->self.position_embedding` (#33958)
* fix red check-copies (#33964)
* [`Red CIs`] Fix hub failures (#34001)
* properly fix and RUN_SLOW (#33965)
* [`pytes collection`] Fix flax test collection (#34004)
* Add support for __all__ and potentilly deleting functions (#33859)
* [`Patch helper`] update to not have to checkout main (#34006)
* Add documentation for docker (#33156)
* Fix Gradient Accumulation issue (#34191)
* Fix-red-ci (#34230)
* @molbap
* Fix position embeddings singular/plural (#33678)
* Uniformize model processors (#31368)
* @vasqu
* Update Albumentations Versions (#33704)
* [`TF`] Fix Tensorflow XLA Generation on limited seq_len models (#33903)
* Mistral-related models for QnA (#34045)
* @VladOS95-cyber
* Add gguf support for bloom (#33473)
* Bug fix gguf qwen2moe (#33940)
* Add gguf support for StableLM (#33793)
* Add gguf support for gpt2 (#34044)
* Add GGUF for starcoder2 (#34094)
* @ydshieh
* Add Slow CI reminder bot (#33506)
* post reminder comment only once (#33848)
* Avoid using context that is not accessable from external contributors (#33866)
* Don't run reminder bot for now (#33883)
* Update SSH workflow file (#34084)
* avoid many failures for ImageGPT (#34071)
* Avoid many test failures for `LlavaNextVideoForConditionalGeneration` (#34070)
* Ping team members for new failed tests in daily CI (#34171)
* @amyeroberts
* Repo consistency fix after #33339 (#33873)
* Trainer - deprecate tokenizer for processing_class (#32385)
* @ylacombe
* [Tests] Diverse Whisper fixes (#33665)
* Fix distil whisper segment computation (#33920)
* [TESTS] ASR pipeline (#33925)
* Fix DAC slow tests (#34088)
* Moshi integration (#33624)
* @ringohoffman
* Remove `logits.float()` (#33902)
* Default `synced_gpus` to `True` when using `FullyShardedDataParallel` (#33483)
* Only cast logits to float when computing loss (#34147)
* @garg-amit
* PhiMoE (#33363)
* @pglorio
* Add Zamba (#30950)
* @tomlimi
* [WIP] Add Tokenizer for MyT5 Model (#31286)
* @yijun-lee
* 🌐 [i18n-KO] Translated `gguf.md` to Korean (#33764)
* 🌐 [i18n-KO] Translated `audio_utils.md` to Korean (#33802)
* 🌐 [i18n-KO] Translated `esm.md` to Korean (#33796)
* 🌐 [i18n-KO] Translated `time_series_utils.md` to Korean (#33806)
* 🌐 [i18n-KO] Translated `pipelines_utils.md` to Korean (#33809)
* 🌐 [i18n-KO] Translated `trainer.md` to Korean (#33797)
* 🌐 [i18n-KO] Translated `chameleon.md` to Korean (#33799)
* 🌐 [i18n-KO] Translated `gemma.md` to Korean (#33936)
* 🌐 [i18n-KO] Translated `feature_extractor.md` to Korean (#33775)
* 🌐 [i18n-KO] Translated `tokenization_utils.md` to Korean (#33813)
* 🌐 [i18n-KO] Translated `file_utils.md` to Korean (#33803)
* 🌐 [i18n-KO] Translated `openai-gpt.md` to Korean (#33801)
* 🌐 [i18n-KO] Translated `biogpt.md` to Korean (#33773)
* 🌐 [i18n-KO] Translated `image_processing_utils.md` to Korean (#33804)
* 🌐 [i18n-KO] Translated `modular_transformers.md` to Korean (#33772)
* 🌐 [i18n-KO] Translated `modeling_utils.md` to Korean (#33808)
* 🌐 [i18n-KO] Translated `text_generation.md` to Korean (#33777)
* 🌐 [i18n-KO] Translated `generation_utils.md` to Korean (#33818)
* 🌐 [i18n-KO] Translated `gemma2.md` to Korean (#33937)
* 🌐 [i18n-KO] Translated `trainer_utils.md` to Korean (#33817)
* @fabxoe
* 🌐 [i18n-KO] Translated `main_classes/quantization.md` to Korean (#33959)
* 🌐 [i18n-KO] Translated `main_classes/configuration.md` to Korean (#33952)
* 🌐 [i18n-KO] Translated `model_doc/mamba.md` to Korean (#33626)
* 🌐 [i18n-KO] Translated `model_doc/autoformer.md` to Korean (#33574)
* 🌐 [i18n-KO] Translated `model_doc/patchtsmixer.md` to Korean (#33587)
* 🌐 [i18n-KO] Translated `�model_doc/clip.md` to Korean (#33610)
* 🌐 [i18n-KO] Translated `model_doc/paligemma.md` to Korean (#33612)
* 🌐 [i18n-KO] Translated `model_doc/llama3.md` to Korean (#33635)
* 🌐 [i18n-KO] Translated `model_doc/mistral.md` to Korean (#33648)
* 🌐 [i18n-KO] Translated `model_doc/cohere.md` to Korean (#33885)
* 🌐 [i18n-KO] Translated `model_doc/dbrx.md` to Korean (#33951)
* 🌐 [i18n-KO] Translated `model_doc/deberta-v2.md` to Korean (#33968)
* 🌐 [i18n-KO] Translated `main_classes/onnx.md` to Korean (#33601)
* 🌐 [i18n-KO] Translated `model_doc/bart.md` to Korean (#33893)
* 🌐 [i18n-KO] Translated `model_doc/deberta.md` to Korean (#33967)
* 🌐 [i18n-KO] Translated `main_classes/keras_callbacks.md` to Korean (#33955)
* 🌐 [i18n-KO] Translated `model_doc/mamba2.md` to Korean (#33629)
* 🌐 [i18n-KO] Translated `main_classes/model.md` to Korean (#33606)
* 🌐 [i18n-KO] Translated `model_doc/trajectory_transformer.md` to Korean (#33597)
* 🌐 [i18n-KO] Translated `model_doc/time_series_transformer.md` to Korean (#33596)
* 🌐 [i18n-KO] Translated `model_doc/informer.md` to Korean (#33585)
* 🌐 [i18n-KO] Translated `model_doc/graphormer.md` to Korean (#33569)
* 🌐 [i18n-KO] Translated `main_classes/data_collator.md` to Korean (#33954)
* 🌐 [i18n-KO] Translated `model_doc/patchtst.md` to Korean (#33589)
* @MekkCyber
* FEAT : Adding BitNet quantization method to HFQuantizer (#33410)
* Fix data_seed unused (#33731)
* Small Fix to modular converter (#34051)
* @AhmedAlmaghz
* Add Translate docs into Arabic - section files CONCEPTUAL GUIDES (#33982)
* @alex-bene
* Add post_process_depth_estimation to image processors and support ZoeDepth's inference intricacies (#32550)
* Generate using exported model and enable gemma2-2b in ExecuTorch by @guangy10 in #33707
* Qwen2.5 is ExecuTorch Compatible by @guangy10 in #34102
* Olmo is ExecuTorch Compatible by @guangy10 in #34181
* Llama3 and Llama2 are ExecuTorch compatible by @guangy10 in #34101
### Gradient accumulation bugfix
* Fix Gradient Accumulation issue by @ArthurZucker in #34191
* Enable users to use their own loss functions + deal with prefetching for grad accum by @muellerzr in #34198
* Enable Gradient Accumulation fix across all models + trainer fully in forward() by @muellerzr #34283
## Bugfixes and improvements
* adding positional encoder changes and tests by @manuelsh in #32600
* Uniformize kwargs for chameleon processor by @leloykun in #32181
* [`MllamaProcessor`] Update errors and API with multiple image by @ArthurZucker in #33715
* fix: use correct var names for check_tokenizers script by @niqodea in #33702
* Fix docs and docstrings Omdet-Turbo by @yonigozlan in #33726
* Fix position embeddings singular/plural by @molbap in #33678
* Generate: `can_generate()` recursive check by @gante in #33718
* clean_up_tokenization_spaces=False if unset by @itazap in #31938
* fix: add docstring for `image_size` in Convnextv2 config by @lucianosrp in #33734
* Fix modular model converter unable to generate Processor classes by @tonywu71 in #33737
* fix trainer tr_loss add error by @Wang-Xiaodong1899 in #33651
* Update Albumentations Versions by @vasqu in #33704
* Doc and config mismatch for DeBERTa by @fkrasnov2 in #33713
* [`clean_up_tokenization_spaces`] Pl bart was failing, updating by @ArthurZucker in #33735
* [`MllamaImageProcessing`] Update doc by @ArthurZucker in #33747
* Make siglip examples clearer and error free by @jbn in #33667
* Paligemma support for multi-image by @zucchini-nlp in #33447
* remove warning v2 by @itazap in #33761
* Model addition timeline by @LysandreJik in #33762
* Fix typing in `load_balancing_loss_func` function of `modeling_mixtral.py`. by @PhilipMay in #33641
* Enable non-safetensor ser/deser for TorchAoConfig quantized model 🔴 by @jerryzh168 in #33456
* Fix typo in documentation by @qgallouedec in #33805
* Hqq serialization by @mobicham in #33141
* Add Slow CI reminder bot by @ydshieh in #33506
* [`modular`] fixes! by @ArthurZucker in #33820
* Fix ViT-MAE decoder interpolate by @xenova in #33330
* Fixes for issue #33763 in idefics2 model by @aroun-coumar in #33766
* Fix link in gguf.md by @pogpog in #33768
* minor typo fix by @a-r-r-o-w in #33784
* Fix Mamba slow path bug with dtype mismatch. by @Adibvafa in #32691
* Fix passing str dtype to static cache by @guangy10 in #33741
* fix check for hidden size in text model for deepspeed zero3 auto entries by @winglian in #33829
* post reminder comment only once by @ydshieh in #33848
* Generate: move llama `prepare_inputs_for_generation` to `GenerationMixin` by @gante in #33677
* Refactor image features selection in LlaVa by @kenza-bouzid in #33696
* fix: skip dropout in eval for flash_attn in various models by @fdschmidt93 in #33844
* add attention weight up-cast to float32 in chameleon by @francescortu in #33822
* Workaround for bark issue in pipelines by @Rocketknight1 in #33824
* Fix device mismatch errors by @zucchini-nlp in #33851
* This PR contains additional changes for #33143 by @aroun-coumar in #33581
* Raise `accelerate` dependency error in case of defaulting `low_cpu_mem_usage=True` by @kylesayrs in #33830
* Validate the eval dataset in advance. by @jackyjinjing in #33743
* Add include_loss_for_metrics by @Manalelaidouni in #33088
* Avoid using context that is not accessable from external contributors by @ydshieh in #33866
* fix: repair depth estimation multiprocessing by @niqodea in #33759
* Move weight initilization deformabledetr by @g-prz in #33339
* [Fix] ViViT interpolate_pos_encoding by @RUFFY-369 in #33815
* Repo consistency fix after #33339 by @amyeroberts in #33873
* Add support for custom inputs and batched inputs in ProcessorTesterMixin by @yonigozlan in #33711
* Fix: typo by @TrickEye in #33880
* Uniformize model processors by @molbap in #31368
* Don't run reminder bot for now by @ydshieh in #33883
* populate quantization_config for kv-cache-scheme only configs by @horheynm in #33874
* Allow for nightly packages of `compressed_tensors` by @kylesayrs in #33828
* Fix kwargs passed by AutoQuantizationConfig.from_pretrained by @kylesayrs in #33798
* Add sdpa for DistilBert by @OmarManzoor in #33724
* Trainer - deprecate tokenizer for processing_class by @amyeroberts in #32385
* [Quantization] Switch to optimum-quanto by @SunMarc in #31732
* Optim deformable detr by @yonigozlan in #33600
* Handle Trainer `tokenizer` kwarg deprecation with decorator by @qubvel in #33887
* rename all test_processing_*.py to test_processor_*.py by @yonigozlan in #33878
* uniformize processor Mllama by @yonigozlan in #33876
* Fix dt proj bias reassigned by @HofitBata in #33314
* Update an keyerror on _save_check_point prevent confusion of missing … by @fadingNA in #33832
* VLM Generate: tag `test_static_cache_matches_dynamic` as flaky by @gante in #33630
* Migrate the CI runners to the new clusters by @glegendre01 in #33849
* Fix module initialization for root module under Zero3 by @Ben-Schneider-code in #33632
* Add `SplinterTokenizer` unit test by @ariepratama in #32652
* Generate tests: modality-agnostic input preparation by @gante in #33685
* Fix: use unidic-lite instead of ipadic as the tokenizer dictionary for Japanese by @KanTakahiro in #33372
* [Tests] Diverse Whisper fixes by @ylacombe in #33665
* [PEFT] Support low_cpu_mem_usage option for PEFT loading adapters by @BenjaminBossan in #33725
* add setter for trainer processor by @ArthurZucker in #33911
* Add support for `weights_only` flag when loading state_dict by @jerryzh168 in #32481
* Config: lower `save_pretrained` exception to warning by @gante in #33906
* Uniformize kwargs for Idefics/2 processors by @yonigozlan in #32568
* Remove `logits.float()` by @ringohoffman in #33902
* Minor error condition bug fix by @htahboub in #33781
* Fix distil whisper segment computation by @ylacombe in #33920
* [Doc]: Broken link in Kubernetes doc by @saldanhad in #33879
* [i18n-ru] Fixes typo in the README_ru.md by @Artanias in #33882
* Ignore keys on `validate_rope` by @zucchini-nlp in #33753
* [`PR run-slow`] by @ArthurZucker in #33939
* Add a section on writing tool templates to the chat template docs by @Rocketknight1 in #33924
* Enables CPU AWQ model with IPEX version. by @jiqing-feng in #33460
* 🔴 🚨 Resizing tokens embeddings: initialize from old embeddings' normal distribution. by @abuelnasr0 in #33325
* Removed unnecessary transpose in Switch Transformer Routing by @karan-uppal3 in #33582
* Fix attn mask ignore logic in training-time trace by @zhenglongjiepheonix in #32613
* hot fix `self.position_embeddings->self.position_embedding` by @ArthurZucker in #33958
* fix red check-copies by @ArthurZucker in #33964
* Cache: revert DynamicCache init for BC by @gante in #33861
* Paligemma: fix static cache test by @zucchini-nlp in #33941
* Updating `char_to_token` documentation to note behaviour when `trim_offsets` is True by @Craigacp in #33919
* add test for Jamba with new model jamba-tiny-dev by @yecohn in #33863
* Bug fix gguf qwen2moe by @VladOS95-cyber in #33940
* [`TF`] Fix Tensorflow XLA Generation on limited seq_len models by @vasqu in #33903
* [WIP] Add Tokenizer for MyT5 Model by @tomlimi in #31286
* Add position ids in forward pass to opt model by @avishaiElmakies in #33121
* Flash-attn performance: remove cuda sync during inference by @Cyrilvallez in #33570
* [Docs] Improve VLM docs by @NielsRogge in #33393
* [Docs] Add Developer Guide: How to Hack Any Transformers Model by @MagnusS0 in #33979
* [`Red CIs`] Fix hub failures by @ArthurZucker in #34001
* Fix Tensor + Embedding error in some cases when using SiglipVisionModel by @kaitolucifer in #33994
* properly fix and RUN_SLOW by @ArthurZucker in #33965
* Enable customized optimizer for DeepSpeed by @dataKim1201 in #32049
* [`pytes collection`] Fix flax test collection by @ArthurZucker in #34004
* Fix undefined default_config in configuration_utils.py by @mgoin in #33934
* 🌐 [i18n-KO] Translated `gguf.md` to Korean by @yijun-lee in #33764
* 🌐 [i18n-KO] Translated `swinv2.md` to Korean by @mreraser in #33566
* 🌐 [i18n-KO] Translated `audio_utils.md` to Korean by @yijun-lee in #33802
* 🌐 [i18n-KO] Translated `esm.md` to Korean by @yijun-lee in #33796
* 🌐 [i18n-KO] Translated `time_series_utils.md` to Korean by @yijun-lee in #33806
* 🌐 [i18n-KO] Translated `pipelines_utils.md` to Korean by @yijun-lee in #33809
* 🌐 [i18n-KO] Translated `trainer.md` to Korean by @yijun-lee in #33797
* 🌐 [i18n-KO] Translated `chameleon.md` to Korean by @yijun-lee in #33799
* 🌐 [i18n-KO] Translated `logging.md` to Korean by @chhaewxn in #33543
* 🌐 [i18n-KO] Translated `auto.md` to Korean by @boyunJang in #33590
* 🌐 [i18n-KO] Translated `swin2sr.md` to Korean by @mreraser in #33795
* 🌐 [i18n-KO] Translated `vit.md` to Korean by @mreraser in #33884
* 🌐 [i18n-KO] Translated `gemma.md` to Korean by @yijun-lee in #33936
* Cache: slight change in naming by @zucchini-nlp in #32421
* Add support for __all__ and potentilly deleting functions by @ArthurZucker in #33859
* Processors: don't default padding side by @zucchini-nlp in #33942
* Add auto model for image-text-to-text by @yonigozlan in #32472
* BatchFeature.to() supports non-tensor keys by @Rocketknight1 in #33918
* Improve modular converter by @Cyrilvallez in #33991
* Fixup DeepSpeed things by @muellerzr in #34007
* Fix typing issue by @SunMarc in #34012
* fix awq tests due to ipex backend by @SunMarc in #34011
* Remove `decoder_config=None` by @SunMarc in #34014
* Fix `trainer_seq2seq.py`'s `__init__` type annotations by @benglewis in #34021
* 🌐 [i18n-KO] Translated `feature_extractor.md` to Korean by @yijun-lee in #33775
* 🌐 [i18n-KO] Translated `bertweet.md` to Korean by @ahnjj in #33891
* 🌐 [i18n-KO] Translated `gpt_neox_japanese.md` to Korean by @ahnjj in #33894
* 🌐 [i18n-KO] Translated `rag.md` to Korean by @chhaewxn in #33989
* 🌐 [i18n-KO] Translated `main_classes/quantization.md` to Korean by @fabxoe in #33959
* 🌐 [i18n-KO] Translated `main_classes/configuration.md` to Korean by @fabxoe in #33952
* 🌐 [i18n-KO] Translated `model_doc/mamba.md` to Korean by @fabxoe in #33626
* 🌐 [i18n-KO] Translated `model_doc/autoformer.md` to Korean by @fabxoe in #33574
* 🌐 [i18n-KO] Translated `model_doc/patchtsmixer.md` to Korean by @fabxoe in #33587
* 🌐 [i18n-KO] Translated `�model_doc/clip.md` to Korean by @fabxoe in #33610
* 🌐 [i18n-KO] Translated `model_doc/paligemma.md` to Korean by @fabxoe in #33612
* 🌐 [i18n-KO] Translated `model_doc/llama3.md` to Korean by @fabxoe in #33635
* 🌐 [i18n-KO] Translated `model_doc/mistral.md` to Korean by @fabxoe in #33648
* 🌐 [i18n-KO] Translated `model_doc/cohere.md` to Korean by @fabxoe in #33885
* 🌐 [i18n-KO] Translated `model_doc/dbrx.md` to Korean by @fabxoe in #33951
* 🌐 [i18n-KO] Translated `model_doc/deberta-v2.md` to Korean by @fabxoe in #33968
* 🌐 [i18n-KO] Translated `main_classes/onnx.md` to Korean by @fabxoe in #33601
* 🌐 [i18n-KO] Translated `tokenization_utils.md` to Korean by @yijun-lee in #33813
* 🌐 [i18n-KO] Translated `swin.md` to Korean by @mreraser in #33510
* 🌐 [i18n-KO] Translated `file_utils.md` to Korean by @yijun-lee in #33803
* 🌐 [i18n-KO] Translated `openai-gpt.md` to Korean by @yijun-lee in #33801
* 🌐 [i18n-KO] Translated `biogpt.md` to Korean by @yijun-lee in #33773
* 🌐 [i18n-KO] Translated `blip.md` to Korean by @cjfghk5697 in #33515
* 🌐 [i18n-KO] Translated output.md to Korean by @4N3MONE in #33607
* 🌐 [i18n-KO] Translated `image_processing_utils.md` to Korean by @yijun-lee in #33804
* 🌐 [i18n-KO] Translated `modular_transformers.md` to Korean by @yijun-lee in #33772
* [`Patch helper`] update to not have to checkout main by @ArthurZucker in #34006
* Fix Failed tests with mobile bert resize tokens embedding by @abuelnasr0 in #33950
* Generate: remove most decoder-only LLMs `prepare_inputs_for_generation` by @gante in #33870
* Mllama: fix tests by @zucchini-nlp in #34000
* Fix PIL dep for tests by @muellerzr in #34028
* 🌐 [i18n-KO] Translated `model_doc/bart.md` to Korean by @fabxoe in #33893
* 🌐 [i18n-KO] Translated `model_doc/deberta.md` to Korean by @fabxoe in #33967
* 🌐 [i18n-KO] Translated `main_classes/keras_callbacks.md` to Korean by @fabxoe in #33955
* 🌐 [i18n-KO] Translated `model_doc/mamba2.md` to Korean by @fabxoe in #33629
* 🌐 [i18n-KO] Translated `main_classes/model.md` to Korean by @fabxoe in #33606
* 🌐 [i18n-KO] Translated `model_doc/trajectory_transformer.md` to Korean by @fabxoe in #33597
* 🌐 [i18n-KO] Translated `model_doc/time_series_transformer.md` to Korean by @fabxoe in #33596
* 🌐 [i18n-KO] Translated `model_doc/informer.md` to Korean by @fabxoe in #33585
* 🌐 [i18n-KO] Translated `model_doc/graphormer.md` to Korean by @fabxoe in #33569
* 🌐 [i18n-KO] Translated `modeling_utils.md` to Korean by @yijun-lee in #33808
* 🌐 [i18n-KO] Translated `main_classes/data_collator.md` to Korean by @fabxoe in #33954
* 🌐 [i18n-KO] Translated `model_doc/patchtst.md` to Korean by @fabxoe in #33589
* 🌐 [i18n-KO] Translated `text_generation.md` to Korean by @yijun-lee in #33777
* 🌐 [i18n-KO] Translated `main_classes/callback.md` to Korean by @Jwaminju in #33572
* 🌐 [i18n-KO] Translated `generation_utils.md` to Korean by @yijun-lee in #33818
* Add Translate docs into Arabic - section files CONCEPTUAL GUIDES by @AhmedAlmaghz in #33982
* add sdpa to OPT by @avishaiElmakies in #33298
* Phi3: fix attn for sliding window by @zucchini-nlp in #33586
* HfArgumentParser: allow for hyhenated field names in long-options by @djmarti in #33990
* Fix pipelines tests by @qubvel in #34049
* Specifying torch dtype in Qwen2VLForConditionalGeneration by @htahboub in #33953
* Universal Assisted Generation: Assisted generation with any assistant model (by Intel Labs) by @danielkorat in #33383
* check if eigenvalues of covariance matrix are complex. by @abuelnasr0 in #34037
* [Docs] Update compressed_tensors.md by @mgoin in #33961
* Fix data_seed unused by @MekkCyber in #33731
* [TESTS] ASR pipeline by @ylacombe in #33925
* Update Blip2 `is_pipeline_test_to_skip` method signature by @qubvel in #34067
* provide trust_remote_code for search feat extractor in model config by @eaidova in #34036
* Small Fix to modular converter by @MekkCyber in #34051
* Default `synced_gpus` to `True` when using `FullyShardedDataParallel` by @ringohoffman in #33483
* Idefics: fix position ids by @zucchini-nlp in #33907
* Update SSH workflow file by @ydshieh in #34084
* Tests: upcast `logits` to `float()` by @gante in #34042
* Fix flax failures by @LysandreJik in #33912
* Fix DAC slow tests by @ylacombe in #34088
* Fix failing conversion by @LysandreJik in #34010
* Fix PushToHubMixin when pusing to a PR revision by @Wauplin in #34090
* avoid many failures for ImageGPT by @ydshieh in #34071
* Fix NaNs in cost_matrix for mask2former by @ducha-aiki in #34074
* Fix flaky tests by @zucchini-nlp in #34069
* Generate: move `prepare_inputs_for_generation` in encoder-decoder llms by @gante in #34048
* Avoid many test failures for `LlavaNextVideoForConditionalGeneration` by @ydshieh in #34070
* refactor: benchmarks by @McPatate in #33896
* fix(ci): benchmarks dashboard was failing due to missing quotations by @McPatate in #34100
* Generate: Fix modern llm `generate` calls with `synced_gpus` by @gante in #34095
* Mistral-related models for QnA by @vasqu in #34045
* Fix a typo by @PengWeixuan in #34148
* Fixed error message in mllama by @dmgcsilva in #34106
* Specify that users should be careful with their own files by @LysandreJik in #34153
* Add documentation for docker by @ArthurZucker in #33156
* Update README.md with Enterprise Hub by @gary149 in #34150
* Idefics: enable generation tests by @zucchini-nlp in #34062
* Add sdpa for Vivit by @RUFFY-369 in #33757
* Fix FSDP resume Initialization issue by @Itssshikhar in #34032
* Fix default behaviour in TextClassificationPipeline for regression problem type by @subhalingamd in #34066
* Generate: move `logits` to same device as `input_ids` by @gante in #34076
* Add support for inheritance from class with different suffix in modular by @yonigozlan in #34077
* Fix optuna ddp hp search by @SunMarc in #34073
* [feat] LlavaNext add feature size check to avoid CUDA Runtime Error by @laurentd-lunit in #33608
* 🌐 [i18n-KO] Translated `vivit.md` to Korean by @mreraser in #33935
* 🌐 [i18n-KO] Translated `gemma2.md` to Korean by @yijun-lee in #33937
* 🌐 [i18n-KO] Translated `trainer_utils.md` to Korean by @yijun-lee in #33817
* 🌐 [i18n-KO] Translated `blip-2.md` to Korean by @cjfghk5697 in #33516
* IDEFICS: support inputs embeds by @zucchini-nlp in #34043
* [fix] fix token healing tests and usage errors by @alpertunga-bile in #33931
* Revert `accelerate` error caused by `46d09af` by @steveepreston in #34197
* Fix wrong name for llava onevision and qwen2_vl in tokenization auto by @yonigozlan in #34177
* Avoid using torch's Tensor or PIL's Image in chat template utils if not available by @RezaRahemtola in #34165
* Revert "Fix FSDP resume Initialization issue" by @SunMarc in #34193
* Update `trainer._get_eval_sampler()` to support `group_by_length` arg by @larin92 in #33514
* Fix warning message for fp32_cpu_offloading in bitsandbytes configs by @amosyou in #34079
* Ping team members for new failed tests in daily CI by @ydshieh in #34171
* fix(Wav2Vec2ForCTC): torch export by @chrsmcgrr in #34023
* Fix for tokenizer.apply_chat_template with continue_final_message=True by @schoennenbeck in #34214
* removes decord by @vrnvu in #33987
* Fix bus error when using GPT2 on M1 macs by @chanind in #34031
* Generate: visit non-llm `prepare_inputs_for_generation` by @gante in #34199
* Support Llama 3.2 conversion (text models) by @pcuenca in #33778
* Fix-red-ci by @ArthurZucker in #34230
* BLIP: fix input expansion logic by @zucchini-nlp in #34225
* Fix broken test decorator `require_torch_up_to_2_accelerators` by @byi8220 in #34201
* Informative 2 by @LysandreJik in #34154
* Fix UDOP dtype issue by @Rocketknight1 in #34180
* Only cast logits to float when computing loss by @ringohoffman in #34147
* Generation tests: don't rely on main input name by @zucchini-nlp in #34228
* Change Paligemma import logging to work with modular by @yonigozlan in #34211
* Add DetrImageProcessorFast by @yonigozlan in #34063
* Add a doc section on writing generation prompts by @Rocketknight1 in #34248
* Fix method name which changes in tutorial by @andimarafioti in #34252
* Attn implementation for composite models by @zucchini-nlp in #32238
* VLM: add more modularity by @zucchini-nlp in #34175
* T5 compile compatibilty by @zucchini-nlp in #34089
* [docs] Fix GenerationConfig params by @stevhliu in #34299
* Fix Korean doc _toctree.yml by @regisss in #34293
* Update PR templates by @SunMarc in #34065
* [RT-DETR] Fix onnx inference bug for Optype (Where) by @YHallouard in #33877
* Fix FA2 attention for models supporting sliding window by @Cyrilvallez in #34093
* Fix: tensor of examples of the same length triggers invalid stacking by @pbelcak in #34166
* Add post_process_depth_estimation to image processors and support ZoeDepth's inference intricacies by @alex-bene in #32550
* Add option for running ffmpeg_microphone_live as a background process by @mikamerath in #32838
* Feature: Add `MLFLOW_MAX_LOG_PARAMS` to `MLflowCallback` by @cecheta in #34279
* Fix continue_final_message for image-text-to-text chat templates by @yonigozlan in #34236
* fix error in _get_eval_sampler when group_by_length enabled by @akakakakakaa in #34237
* [docs] fix typo by @faaany in #34235
* 🌐 [i18n-KO] Translated `executorch.md` to Korean by @ahnjj in #33888
* 🌐 [i18n-KO] Translated `bert japanese.md` to Korean by @ahnjj in #33890
* 🌐 [i18n-KO] Translated `model_doc/bartpho.md` to Korean by @Jwaminju in #33981
* Example doc for token classification of Llama and Dependent/Copied Models by @h3110Fr13nd in #34139
* [docs] Fix Korean toctree by @stevhliu in #34324
* Added Deberta model type support by @FilipposVentirozos in #34308
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @manuelsh
* adding positional encoder changes and tests (#32600)
* @ArthurZucker
* [`MllamaProcessor`] Update errors and API with multiple image (#33715)
* [`clean_up_tokenization_spaces`] Pl bart was failing, updating (#33735)
* [`MllamaImageProcessing`] Update doc (#33747)
* [`modular`] fixes! (#33820)
* add setter for trainer processor (#33911)
* [`PR run-slow`] (#33939)
* hot fix `self.position_embeddings->self.position_embedding` (#33958)
* fix red check-copies (#33964)
* [`Red CIs`] Fix hub failures (#34001)
* properly fix and RUN_SLOW (#33965)
* [`pytes collection`] Fix flax test collection (#34004)
* Add support for __all__ and potentilly deleting functions (#33859)
* [`Patch helper`] update to not have to checkout main (#34006)
* Add documentation for docker (#33156)
* Fix Gradient Accumulation issue (#34191)
* Fix-red-ci (#34230)
* @molbap
* Fix position embeddings singular/plural (#33678)
* Uniformize model processors (#31368)
* @vasqu
* Update Albumentations Versions (#33704)
* [`TF`] Fix Tensorflow XLA Generation on limited seq_len models (#33903)
* Mistral-related models for QnA (#34045)
* @VladOS95-cyber
* Add gguf support for bloom (#33473)
* Bug fix gguf qwen2moe (#33940)
* Add gguf support for StableLM (#33793)
* Add gguf support for gpt2 (#34044)
* Add GGUF for starcoder2 (#34094)
* @ydshieh
* Add Slow CI reminder bot (#33506)
* post reminder comment only once (#33848)
* Avoid using context that is not accessable from external contributors (#33866)
* Don't run reminder bot for now (#33883)
* Update SSH workflow file (#34084)
* avoid many failures for ImageGPT (#34071)
* Avoid many test failures for `LlavaNextVideoForConditionalGeneration` (#34070)
* Ping team members for new failed tests in daily CI (#34171)
* @amyeroberts
* Repo consistency fix after #33339 (#33873)
* Trainer - deprecate tokenizer for processing_class (#32385)
* @ylacombe
* [Tests] Diverse Whisper fixes (#33665)
* Fix distil whisper segment computation (#33920)
* [TESTS] ASR pipeline (#33925)
* Fix DAC slow tests (#34088)
* Moshi integration (#33624)
* @ringohoffman
* Remove `logits.float()` (#33902)
* Default `synced_gpus` to `True` when using `FullyShardedDataParallel` (#33483)
* Only cast logits to float when computing loss (#34147)
* @garg-amit
* PhiMoE (#33363)
* @pglorio
* Add Zamba (#30950)
* @tomlimi
* [WIP] Add Tokenizer for MyT5 Model (#31286)
* @yijun-lee
* 🌐 [i18n-KO] Translated `gguf.md` to Korean (#33764)
* 🌐 [i18n-KO] Translated `audio_utils.md` to Korean (#33802)
* 🌐 [i18n-KO] Translated `esm.md` to Korean (#33796)
* 🌐 [i18n-KO] Translated `time_series_utils.md` to Korean (#33806)
* 🌐 [i18n-KO] Translated `pipelines_utils.md` to Korean (#33809)
* 🌐 [i18n-KO] Translated `trainer.md` to Korean (#33797)
* 🌐 [i18n-KO] Translated `chameleon.md` to Korean (#33799)
* 🌐 [i18n-KO] Translated `gemma.md` to Korean (#33936)
* 🌐 [i18n-KO] Translated `feature_extractor.md` to Korean (#33775)
* 🌐 [i18n-KO] Translated `tokenization_utils.md` to Korean (#33813)
* 🌐 [i18n-KO] Translated `file_utils.md` to Korean (#33803)
* 🌐 [i18n-KO] Translated `openai-gpt.md` to Korean (#33801)
* 🌐 [i18n-KO] Translated `biogpt.md` to Korean (#33773)
* 🌐 [i18n-KO] Translated `image_processing_utils.md` to Korean (#33804)
* 🌐 [i18n-KO] Translated `modular_transformers.md` to Korean (#33772)
* 🌐 [i18n-KO] Translated `modeling_utils.md` to Korean (#33808)
* 🌐 [i18n-KO] Translated `text_generation.md` to Korean (#33777)
* 🌐 [i18n-KO] Translated `generation_utils.md` to Korean (#33818)
* 🌐 [i18n-KO] Translated `gemma2.md` to Korean (#33937)
* 🌐 [i18n-KO] Translated `trainer_utils.md` to Korean (#33817)
* @fabxoe
* 🌐 [i18n-KO] Translated `main_classes/quantization.md` to Korean (#33959)
* 🌐 [i18n-KO] Translated `main_classes/configuration.md` to Korean (#33952)
* 🌐 [i18n-KO] Translated `model_doc/mamba.md` to Korean (#33626)
* 🌐 [i18n-KO] Translated `model_doc/autoformer.md` to Korean (#33574)
* 🌐 [i18n-KO] Translated `model_doc/patchtsmixer.md` to Korean (#33587)
* 🌐 [i18n-KO] Translated `�model_doc/clip.md` to Korean (#33610)
* 🌐 [i18n-KO] Translated `model_doc/paligemma.md` to Korean (#33612)
* 🌐 [i18n-KO] Translated `model_doc/llama3.md` to Korean (#33635)
* 🌐 [i18n-KO] Translated `model_doc/mistral.md` to Korean (#33648)
* 🌐 [i18n-KO] Translated `model_doc/cohere.md` to Korean (#33885)
* 🌐 [i18n-KO] Translated `model_doc/dbrx.md` to Korean (#33951)
* 🌐 [i18n-KO] Translated `model_doc/deberta-v2.md` to Korean (#33968)
* 🌐 [i18n-KO] Translated `main_classes/onnx.md` to Korean (#33601)
* 🌐 [i18n-KO] Translated `model_doc/bart.md` to Korean (#33893)
* 🌐 [i18n-KO] Translated `model_doc/deberta.md` to Korean (#33967)
* 🌐 [i18n-KO] Translated `main_classes/keras_callbacks.md` to Korean (#33955)
* 🌐 [i18n-KO] Translated `model_doc/mamba2.md` to Korean (#33629)
* 🌐 [i18n-KO] Translated `main_classes/model.md` to Korean (#33606)
* 🌐 [i18n-KO] Translated `model_doc/trajectory_transformer.md` to Korean (#33597)
* 🌐 [i18n-KO] Translated `model_doc/time_series_transformer.md` to Korean (#33596)
* 🌐 [i18n-KO] Translated `model_doc/informer.md` to Korean (#33585)
* 🌐 [i18n-KO] Translated `model_doc/graphormer.md` to Korean (#33569)
* 🌐 [i18n-KO] Translated `main_classes/data_collator.md` to Korean (#33954)
* 🌐 [i18n-KO] Translated `model_doc/patchtst.md` to Korean (#33589)
* @MekkCyber
* FEAT : Adding BitNet quantization method to HFQuantizer (#33410)
* Fix data_seed unused (#33731)
* Small Fix to modular converter (#34051)
* @AhmedAlmaghz
* Add Translate docs into Arabic - section files CONCEPTUAL GUIDES (#33982)
* @alex-bene
* Add post_process_depth_estimation to image processors and support ZoeDepth's inference intricacies (#32550)
Release v4.45.2 (2024-10-07)
# Patch release v4.45.2
Mostly some warnings that were not properly removed ⚠️ :
* Ignore keys on validate_rope #33753 by @zucchini-nlp
* remove warning v2 #33761 by @itazap
* Config: lower save_pretrained exception to warning #33906 by @gante
🔴 Had a small regression with dynamic Cache 🔴
*Cache: revert DynamicCache init for BC #33861 by @gante
A small fix for idefic 🐩 :
* Fixes for issue #33763 in idefics2 model #33766 by @aroun-coumar
And a fix for `Siglip` 🤧 !
* hot fix self.position_embeddings->self.position_embedding #33958 and properly fix and RUN_SLOW #33965 thanks to @mranzinger
Patch Release v4.45.1 (2024-09-26)
# Patches for v4.45.1
* [MllamaProcessor] Update errors and API with multiple image (#33715) by @ArthurZucker
* Generate: can_generate() recursive check (#33718) by @gante
* clean_up_tokenization_spaces=False if unset (#31938) by @itazap
Llama 3.2, mllama, Qwen2-Audio, Qwen2-VL, OLMoE, Llava Onevision, Pixtral, FalconMamba, Modular Transformers (2024-09-25)
## New model additions
### mllama
The Llama 3.2-Vision collection of multimodal large language models (LLMs) is a collection of pretrained and instruction-tuned image reasoning generative models in 11B and 90B sizes (text + images in / text out). The Llama 3.2-Vision instruction-tuned models are optimized for visual recognition, image reasoning, captioning, and answering general questions about an image. The models outperform many of the available open source and closed multimodal models on common industry benchmarks.

- Add MLLama #33703, by @qubvel, @zucchini-nlp, @ArthurZucker
### Qwen2-VL
The Qwen2-VL is a major update from the previous Qwen-VL by the Qwen team.
An extract from the Qwen2-VL blogpost available [here]() is as follows:
Qwen2-VL is the latest version of the vision language models based on Qwen2 in the Qwen model familities. Compared with Qwen-VL, Qwen2-VL has the capabilities of:
- SoTA understanding of images of various resolution & ratio: Qwen2-VL achieves state-of-the-art performance on visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, MTVQA, etc.
- Understanding videos of 20min+: Qwen2-VL can understand videos over 20 minutes for high-quality video-based question answering, dialog, content creation, etc.
- Agent that can operate your mobiles, robots, etc.: with the abilities of complex reasoning and decision making, Qwen2-VL can be integrated with devices like mobile phones, robots, etc., for automatic operation based on visual environment and text instructions.
- Multilingual Support: to serve global users, besides English and Chinese, Qwen2-VL now supports the understanding of texts in different languages inside images, including most European languages, Japanese, Korean, Arabic, Vietnamese, etc.

* support qwen2-vl by @simonJJJ in #32318
### Qwen2-Audio
The Qwen2-Audio is the new model series of large audio-language models from the Qwen team. Qwen2-Audio is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions.
They introduce two distinct audio interaction modes:
- voice chat: users can freely engage in voice interactions with Qwen2-Audio without text input
- audio analysis: users could provide audio and text instructions for analysis during the interaction

* Add Qwen2-Audio by @faychu in #32137
### OLMoE
OLMoE is a series of **O**pen **L**anguage **M**odels using sparse **M**ixture-**o**f-**E**xperts designed to enable the science of language models. The team releases all code, checkpoints, logs, and details involved in training these models.

* Add OLMoE by @Muennighoff in #32406
## Llava Onevision
LLaVA-Onevision is a Vision-Language Model that can generate text conditioned on one or several images/videos. The model consists of SigLIP vision encoder and a Qwen2 language backbone. The images are processed with anyres-9 technique where the image is split into 9 patches to better process high resolution images and capture as much details as possible. However, videos are pooled to a total sequence length of 196 tokens each frame for more memory efficient computation. LLaVA-Onevision is available in three sizes: 0.5B, 7B and 72B and achieves remarkable performance on benchmark evaluations.

* Llava Onevision: add model by @zucchini-nlp in #32673
### FalconMamba
The FalconMamba model was proposed by TII UAE (Technology Innovation Institute) in their release.
The model has been trained on approximtely 6T tokens consisting a mixture of many data sources such as RefineWeb, Cosmopedia and Math data.
The team releases an accompanying [blog post](https://huggingface.co/blog/falconmamba).

* Add new model by @younesbelkada in #32615
### Granite Language Models
he Granite model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
PowerLM-3B is a 3B state-of-the-art small language model trained with the Power learning rate scheduler. It is trained on a wide range of open-source and synthetic datasets with permissive licenses. PowerLM-3B has shown promising results compared to other models in the size categories across various benchmarks, including natural language multi-choices, code generation, and math reasoning.

* Granite language models by @mayank31398 in #31502
### Granite MOE
The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
PowerMoE-3B is a 3B sparse Mixture-of-Experts (sMoE) language model trained with the Power learning rate scheduler. It sparsely activates 800M parameters for each token. It is trained on a mix of open-source and proprietary datasets. PowerMoE-3B has shown promising results compared to other dense models with 2x activate parameters across various benchmarks, including natural language multi-choices, code generation, and math reasoning.
* Granitemoe by @mayank31398 in #33207
### Descript-Audio-Codec
The Descript Audio Codec (DAC) model is a powerful tool for compressing audio data, making it highly efficient for storage and transmission. By compressing 44.1 KHz audio into tokens at just 8kbps bandwidth, the DAC model enables high-quality audio processing while significantly reducing the data footprint. This is particularly useful in scenarios where bandwidth is limited or storage space is at a premium, such as in streaming applications, remote conferencing, and archiving large audio datasets.

* Add Descript-Audio-Codec model by @kamilakesbi in #31494
### Pixtral
The Pixtral model was released by the Mistral AI team. Pixtral is a multimodal model, taking images and text as input, and producing text as output. This model follows the [Llava](https://huggingface.co/docs/transformers/main/en/model_doc/llava) family, meaning image embeddings are placed instead of the [IMG] token placeholders.
The model uses [PixtralVisionModel](https://huggingface.co/docs/transformers/main/en/model_doc/pixtral#transformers.PixtralVisionModel) for its vision encoder, and [MistralForCausalLM](https://huggingface.co/docs/transformers/main/en/model_doc/mistral#transformers.MistralForCausalLM) for its language decoder. The main contribution is the 2d ROPE (rotary postiion embeddings) on the images, and support for arbitrary image sizes (the images are not padded together nor are they resized).
* Add support for Pixtral by @ArthurZucker in #33449
### Mimi
The Mimi model was proposed in [Moshi: a speech-text foundation model for real-time dialogue](https://kyutai.org/Moshi.pdf) by Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave and Neil Zeghidour. Mimi is a high-fidelity audio codec model developed by the Kyutai team, that combines semantic and acoustic information into audio tokens running at 12Hz and a bitrate of 1.1kbps. In other words, it can be used to map audio waveforms into “audio tokens”, known as “codebooks”.

* Codec integration by @ylacombe in #33565
### OmDet-Turbo
The OmDet-Turbo model was proposed in [Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head](https://arxiv.org/abs/2403.06892) by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.

* Add OmDet-Turbo by @yonigozlan in #31843
## Quantization
### GGUF
GGUF support continues to be enhanced in the library by offering a way to load GGUF models within `transformers` by unquantizing them, before re-quantizing them for re-use within the GGUF/GGML ecosystem.
* Add Qwen2Moe GGUF loading support by @VladOS95-cyber in #33264
* Fix incorrect vocab size retrieval in GGUF config by @Isotr0py in #32551
* Add chat_template for tokenizer extracted from GGUF model by @Isotr0py in #32908
* 🚨 Support dequantization for most GGML types by @Isotr0py in #32625
* Add support for GGUF Phi-3 by @a8nova in #31844
### Torch AO
An ongoing effort is to add the ability to use `torchao` as a quantization backend. Future PRs will enable saving and fine-tuning with `peft`.
* Add TorchAOHfQuantizer by @jerryzh168 in #32306
### Liger Kernel
The Liger kernel is now supported in the `Trainer` class.
* Integrate Liger (Linkedin GPU Efficient Runtime) Kernel to Trainer by @JasonZhu1313 in #32860
## Modular Transformers
This PR introduces Modularity for transformers, which has always been prohibited when working with transformers (see [blog post](https://huggingface.co/blog/transformers-design-philosophy) for the accompanying design philosophy).
The core idea behind this PR is to facilitate model addition by enabling Pythonic inheritance while keeping true to our single-file policy in which models/processors must be contained within a single file, enabling working around the object without going through 10 layers of abstractions.
It is heavily recommended to read the PR description in order to understand the depth of the change: https://github.com/huggingface/transformers/pull/33248

* Modular `transformers`: modularity and inheritance for new model additions by @ArthurZucker in #33248
## Agents
`Agents` continue being improved at each release; this time making it much simpler to leverage a local engine through a local Transformers Engine.
* Multi agents with manager by @aymeric-roucher in #32687
* Add new documentation page for advanced agent usage by @aymeric-roucher in #33265
* Create local Transformers Engine by @aymeric-roucher in #33218
* Agents use grammar by @aymeric-roucher in #31735
## Dynamic cache for decoder-only models
This PR adds to all decoder-only models (except for XLNet) support for dynamic cache.
The documentation for the Dynamic cache can be found [here](https://huggingface.co/docs/transformers/main/en/internal/generation_utils#transformers.DynamicCache), and documentation related to the KV cache in `transformers` in general can be found [here](https://huggingface.co/docs/transformers/main/en/kv_cache).
* Cache: new Cache format in decoder-only models by @zucchini-nlp in #31421
## Chat templates updates
We've made several updates to our handling of chat models and chat templates. The most noticeable change is that **assistant prefill** is now supported. This means you can end a chat with an `assistant` message, and the model will continue that message instead of starting a new one, allowing you to guide the model's response:
```python
pipe = pipeline("text-generation", model_checkpoint)
chat = [
{"role": "user", "content": "Can you format the answer in JSON?"},
{"role": "assistant", "content": '{"name": "'}
]
output = pipe(chat) # The model will continue outputting JSON!
```
We've also enabled several new functionalities in Jinja that will allow more powerful templates in future, including [Loop Controls](https://jinja.palletsprojects.com/en/3.0.x/templates/#loop-controls) and a `strftime_now` function that can get the current date and time, which is commonly used in system messages. For more details, see the updated [chat template docs](https://huggingface.co/docs/transformers/main/en/chat_templating).
* Enable some Jinja extensions and add datetime capabilities by @Rocketknight1 in #32684
* Update Jinja docs with new functions and general cleanup by @Rocketknight1 in #33097
* Add assistant prefill for chat templates and TextGenerationPipeline by @Rocketknight1 in #33198
* Add a warning to the chat template docs about the tool_calls format by @Rocketknight1 in #33277
* Add tip to clarify tool calling by @Rocketknight1 in #32883
## Bugfixes and improvements
* 🌐 [i18n-KO] Translated `mask_generation.md` to Korean by @jeongiin in #32257
* 🌐 [i18n-KO] Translated `idefics.md` to Korean by @boyunJang in #32258
* 🌐 [i18n-KO] Translated `image_to_image.md` to Korean by @shinhyunji36 in #32327
* Gemma2: add cache warning by @zucchini-nlp in #32279
* enable xla fsdp by @hanwen-sun in #32048
* Fix typo in tokenization_utils_base.py by @blubitz in #32484
* fix broken link in docs by @jorahn in #32491
* Docs: alert for the possibility of manipulating logits by @gante in #32467
* 🌐 [i18n-KO] Translated `gptq.md` to Korean by @1kmmk1 in #32293
* 🌐 [i18n-KO] Translated `prompting.md` to Korean by @chhaewxn in #32294
* 🌐 [i18n-KO] Translated `quantization/quanto.md` to Korean by @fabxoe in #32281
* 🌐 [i18n-KO] Translated `image_feature_extraction.md` to Korean by @mreraser in #32239
* Fix references to model google mt5 small by @JuanFKurucz in #32497
* Docs: Fixed WhisperModel.forward’s docstring link by @Sai-Suraj-27 in #32498
* 🌐 [i18n-KO] Translated `chat_templating.md` to Korean by @enchantee00 in #32362
* Fix link to autoclass_tutorial.md in i18n.md by @JuanFKurucz in #32501
* Fix typo: depracted -> deprecated by @tomaarsen in #32489
* Fix issue #32518: Update llm_tutorial.md by @doomdagadiggiedahdah in #32523
* Change Phi3 `_supports_sdpa` to True by @pocca2048 in #32457
* Uniformize kwargs for processors - GroundingDINO by @SangbumChoi in #31964
* Fix add-new-model-like by @molbap in #31773
* filter flash_attn optional imports loading remote code by @eaidova in #30954
* 🌐 [i18n-KO] Translated `ko-llm_tutorial_optimization.md` to Korean by @010kim in #32372
* 🌐 [i18n-KO] Translated `trainer.md` to Korean by @cjfghk5697 in #32260
* 🌐 [i18n-KO] Translated `eetq.md` to Korean by @jun048098 in #32352
* 🌐 [i18n-KO] Translated `fsdp.md` to Korean by @win2dvp21 in #32261
* 🌐 [i18n-KO] Translated `bitsandbytes.md` to Korean by @SeungAhSon in #32408
* Fix generate with `inputs_embeds` as input by @molbap in #32493
* Fixed test `test_static_cache_exportability` with torch 2.4.0 by @guangy10 in #32516
* Fix code example to load bigcode starcoder2 7b by @JuanFKurucz in #32474
* [docs] Translation guide by @stevhliu in #32547
* Gemma2: fix FA2 generation by @zucchini-nlp in #32553
* Fix a bug in Qwen2Audio by @faychu in #32552
* fix slow integration gemma2 test by @ArthurZucker in #32534
* fix non contiguous tensor value error in save_pretrained by @congcongke in #32422
* 🌐 [i18n-KO] Translated `agent.md` to Korean by @Jwaminju in #32351
* Fix: FA2 with packed training by @zucchini-nlp in #32487
* Fix sliding window attention used in Gemma2FlashAttention2 by @brcps12 in #32522
* fix: Fixed conditional check for `encodec` model names by @Sai-Suraj-27 in #32581
* Fix `.push_to_hub(..., create_pr=True, revision="my-branch")` when creating PR on not-owned repo by @Wauplin in #32094
* Cleanup tool calling documentation and rename doc by @Rocketknight1 in #32337
* 🌐 [i18n-KO] Translated `deepspeed.md` to Korean by @4N3MONE in #32431
* 🌐 [i18n-KO] Translated `awq.md`to Korean by @ahnjj in #32324
* fix: Fixed failing `test_find_base_model_checkpoint` by @Sai-Suraj-27 in #32638
* "to be not" -> "not to be" by @qgallouedec in #32636
* fix: Updated the `is_torch_mps_available()` function to include `min_version` argument by @Sai-Suraj-27 in #32545
* Expand inputs in processors for VLMs by @zucchini-nlp in #30962
* Automatically add `transformers` tag to the modelcard by @LysandreJik in #32623
* Fix tests by @molbap in #32649
* fix tensors on different devices in `WhisperGenerationMixin` by @faaany in #32316
* Add support for GrokAdamW optimizer by @ehartford in #32521
* Add Depth Anything V2 Metric models by @bt2513 in #32126
* Fix: Fixed directory path for utils folder in `test_tokenization_utils.py` by @Sai-Suraj-27 in #32601
* Modify ProcessorTesterMixin for better generalization by @yonigozlan in #32637
* TF_Deberta supporting mixed precision by @pinesnow72 in #32618
* Fix tests recurrent by @molbap in #32651
* Support MUSA (Moore Threads GPU) backend in transformers by @fmo-mt in #31913
* fix: Fixed failing tests in `tests/utils/test_add_new_model_like.py` by @Sai-Suraj-27 in #32678
* Update translation docs review by @stevhliu in #32662
* Fix `JetMoeIntegrationTest` by @ydshieh in #32332
* Update the distributed CPU training on Kubernetes documentation by @dmsuehir in #32669
* fix: Fixed unknown pytest config option `doctest_glob` by @Sai-Suraj-27 in #32475
* Unpin deepspeed in Docker image/tests by @muellerzr in #32572
* Updated workflows to the latest versions by @Sai-Suraj-27 in #32405
* reopen: llava-next fails to consider padding_side during Training by @jp1924 in #32679
* fix: Corrected ` falcon-mamba-7b` model checkpoint name by @Sai-Suraj-27 in #32837
* fix: update doc link for runhouse in README.md by @muddlebee in #32664
* VLMs: small clean-up for cache class by @zucchini-nlp in #32417
* add back the position ids by @ArthurZucker in #32554
* Use head_dim if in config for RoPE by @suiyoubi in #32495
* Generate: unify `LogitsWarper` and `LogitsProcessor` by @gante in #32626
* [tests] make test_sdpa_equivalence device-agnostic by @faaany in #32520
* Cache: use `batch_size` instead of `max_batch_size` by @gante in #32657
* Fix AutoConfig and AutoModel support for Llava-Next-Video by @TKONIY in #32844
* improve _get_is_as_tensor_fns by @zrr1999 in #32596
* Revert PR 32299, flag users when Zero-3 was missed by @muellerzr in #32851
* fix multi-gpu with static cache by @SunMarc in #32543
* Reduce the error log when using core models that need their weights renamed, and provide a step forward by @muellerzr in #32656
* Make beam_constraints.Constraint.advance() docstring more accurate by @alex-calderwood in #32674
* generate: missing `to` in DoLa body, causing exceptions in multi-gpu generation by @gante in #32856
* Add Flax Dinov2 by @MHRDYN7 in #31960
* support torch-speech by @itazap in #32537
* [tests] make `test_sdpa_can_compile_dynamic` device-agnostic by @faaany in #32519
* Add __repr__ for Conv1D by @AaronZLT in #32425
* Support save/load ckpt for XLA FSDP by @yitongh in #32311
* RT-DETR parameterized batchnorm freezing by @AlanBlanchet in #32631
* Mamba / FalconMamba: Fix mamba left padding by @younesbelkada in #32677
* Fix: Mamba2 generation mismatch between input_ids and inputs_embeds by @vasqu in #32694
* Docs: Fixed `whisper-large-v2` model link in docs by @Sai-Suraj-27 in #32871
* Allow-head-dim by @ArthurZucker in #32857
* 🚨🚨🚨 Update min version of accelerate to 0.26.0 by @SunMarc in #32627
* Fix repr for conv by @ArthurZucker in #32897
* fix: jamba cache fails to use torch.nn.module by @xgal in #32894
* Fix: Mamba2 `norm_before_gate` usage by @vasqu in #32686
* Replace `tensor.norm()` with decomposed version for CLIP executorch export by @qubvel in #32887
* link for optimizer names by @nbroad1881 in #32400
* [i18n-ar] add README_ar.md to README.md by @AhmedAlmaghz in #32583
* fix: [whisper] don't overwrite GenerationConfig's `return_timestamps` when `return_timestamps` is not passed to `generate` function by @hrl in #31296
* Update docker image building by @ArthurZucker in #32918
* Jamba: update integration tests by @gante in #32250
* fix: Added missing `huggingface_hub` installation to workflows by @Sai-Suraj-27 in #32891
* fix: no need to dtype A in jamba by @xgal in #32924
* FEAT / Trainer: Add adamw 4bit optimizer by @SunMarc in #31865
* CI: separate step to download nltk files by @gante in #32935
* FIX / Hub: Also catch for `exceptions.ConnectionError` by @younesbelkada in #31469
* Add SynCode to llm_tutorial by @shubhamugare in #32884
* Fix benchmark script by @ydshieh in #32635
* Improve greedy search memory usage by @regisss in #32895
* fix: (issue #32689) `AttributeError` raised when using `Trainer` with `eval_on_start=True` in Jupyter Notebook. by @fshp971 in #32849
* Gemma2: eager attention by default by @gante in #32865
* [run_slow] idefics2 by @andimarafioti in #32840
* Fix regression on `Processor.save_pretrained` caused by #31691 by @leloykun in #32921
* 🌐 [i18n-KO] Translated `knowledge_distillation_for_image_classification.md to Korean" by @JinukHong in #32334
* Generate: Deprecate returning legacy cache by default; Handle `use_cache=False` by @gante in #32863
* docs: fix outdated link to TF32 explanation by @anakin87 in #32947
* Reducing memory usage: removing useless logits computation in generate() by @Cyrilvallez in #31292
* Forbid `PretrainedConfig` from saving `generate` parameters; Update deprecations in `generate`-related code 🧹 by @gante in #32659
* DeviceGuard added to use Deformable Attention more safely on multi-GPU by @DonggeunYu in #32910
* added doctring to SchedulerType class by @Arunprakash-A in #32898
* Updated the custom_models.md changed cross_entropy code by @S-M-J-I in #33118
* CI: add torchvision to the consistency image by @gante in #32941
* Test: add higher `atol` in `test_forward_with_num_logits_to_keep` by @gante in #33093
* mps: add `isin_mps_friendly`, a wrapper function for `torch.isin` by @gante in #33099
* Add changes for uroman package to handle non-Roman characters by @nandwalritik in #32404
* fix: Fixed `pydantic` required version in dockerfiles to make it compatible with DeepSpeed by @Sai-Suraj-27 in #33105
* quickfix documentation by @molbap in #32566
* Fixup py 38 type hints for mps friendly by @muellerzr in #33128
* fix: Fixed CodeGenTokenizationTest::test_truncation failing test by @Sai-Suraj-27 in #32850
* fix: multilingual midel convert to tflite get wrong token by @Ayaa17 in #32079
* disable scheduled daily CI temporarily by @ydshieh in #33136
* CI: fix `efficientnet` pipeline timeout and prevent future similar issues due to large image size by @gante in #33123
* Log additional test metrics with the CometCallback by @Lothiraldan in #33124
* [docs] add quick usage snippet to Whisper. by @Vaibhavs10 in #31289
* Update stateful_callbacks state before saving checkpoint by @pedrobrs in #32115
* fix Idefics2VisionConfig type annotation by @chenzizhao in #33103
* Add a fix for custom code tokenizers in pipelines by @Rocketknight1 in #32300
* Llama: make slow tests green 🟢 by @gante in #33138
* fix redundant checkpointing in example training scripts by @eminorhan in #33131
* update torch req for 4-bit optimizer by @SunMarc in #33144
* 🌐 [i18n-KO] Translated `conversations.md` to Korean by @newfull5 in #32468
* Very small change to one of the function parameters by @alisalamatian1 in #32548
* 🚨 Add Blip2ForImageTextRetrieval by @jpizarrom in #29261
* fix model name and copyright by @mayank31398 in #33152
* Fix: Jamba batched generation by @vasqu in #32914
* [whisper] pass attention_mask to generate_with_fallback() by @benniekiss in #33145
* [RoBERTa-based] Add support for sdpa by @hackyon in #30510
* Fix import paths for test_module by @rasmi in #32888
* Zero-shot pipelines: minor doc changes by @pcuenca in #33127
* Customise the separator used for splicing in DataCollatorWithFlattening by @beep-bebop in #33114
* Fix spell mistakes by @matsuo1234567 in #33149
* update push CI workflow files for security by @ydshieh in #33142
* added quick clarification by @DuyguA in #33166
* pass module to Params4bit.from_prequantized to ensure quant_state by @winglian in #32524
* Mamba2 conversion script for original models by @vasqu in #32580
* Add a static cache that offloads to the CPU or other device by @gerbenvv in #32161
* use a single for loop by @ArthurZucker in #33148
* Pipeline: fix bad generation kwargs docs by @gante in #33205
* Add missing quotes in modeling_llava_next_video.py by @juliendenize in #33214
* Add warning for stop string edge case by @Rocketknight1 in #33169
* Fix local repos with remote code not registering for pipelines by @Rocketknight1 in #33100
* Refactor CI: more explicit by @ArthurZucker in #30674
* 🌐 [i18n-KO] Translated `llm_optims.md` to Korean by @yijun-lee in #32325
* Fix red amin by @ArthurZucker in #33220
* Test fetcher: missing return on filtered tests; don't write empty files by @gante in #33224
* Generate: throw warning when `return_dict_in_generate` is False but should be True by @gante in #33146
* Add video text to text docs by @merveenoyan in #33164
* Add GraniteRMSNorm by @NielsRogge in #33177
* Add duckduckgo search tool by @aymeric-roucher in #32882
* Fix: Suppressed 'use_reentrant=False' warning by @ankush13r in #33208
* docs: Replace package abbreviations with full name(`bitsandbytes`) in docstrings by @rapsealk in #33230
* Generate: fix assistant in different device by @gante in #33257
* remove to restriction for 4-bit model by @SunMarc in #33122
* Fixed typo repeated word in DETR docs by @sergiopaniego in #33250
* Fix: use `torch.from_numpy()` to create tensors for np.ndarrays by @shinyano in #33201
* remove torch input dependant control flow by @ArthurZucker in #33245
* Fix: `num_logits_to_keep` in composite models by @zucchini-nlp in #33168
* Fix Bark saving by @ylacombe in #33266
* Update chat template docs to remove Blenderbot by @Rocketknight1 in #33254
* Add sdpa support for Albert by @OmarManzoor in #32092
* Only disallow DeepSpeed Zero-3 for auto bs finder by @muellerzr in #31731
* fix the parallel number of CI nodes when it is smaller than number of tests by @ArthurZucker in #33276
* Repo checks: check documented methods exist by @gante in #32320
* Fix: multigpu training by @zucchini-nlp in #33271
* Cache docs: update by @zucchini-nlp in #32929
* Config: unified logic to retrieve text config by @gante in #33219
* [fix] LlavaNextProcessor '_get_unpadded_features' method by @laurentd-lunit in #33263
* wait 15m before SSH into runner workflow stops by @ydshieh in #33300
* Bugfix/alexsherstinsky/fix none check for attention factor in rope scaling 2024 08 28 0 by @alexsherstinsky in #33188
* [InstructBLIP] qformer_tokenizer is required input by @amyeroberts in #33222
* [BUG] fix upper nltk version by @ylacombe in #33301
* Fix excessive CPU memory usage with FSDP and cpu_ram_efficient_loading by @matthewdouglas in #33154
* Add validate images and text inputs order util for processors and test_processing_utils by @yonigozlan in #33285
* Fix: Fix `FalconMamba` training issues due to incompatible kernels by @younesbelkada in #33195
* Add paper link by @Muennighoff in #33305
* 🚨 Fix `torch.jit.trace` for `interpolate_pos_encoding` in all vision models by @xenova in #33226
* Update SECURITY.md by @Michellehbn in #32680
* simple align qwen2vl kv_seq_len calculation with qwen2 by @simonJJJ in #33161
* Add a community notebook for fine-tuning with QLoRA, PEFT, and MLflow by @daniellok-db in #33319
* Fix: StaticCache & `inputs_embeds` by @zucchini-nlp in #32932
* Docs: add more cross-references to the KV cache docs by @gante in #33323
* [whisper] alternative fix for long-form timestamps by @sanchit-gandhi in #32131
* fix qwen2vl vision eager-attention by @simonJJJ in #33213
* Load dynamic module (remote code) only once if code isn't change by @XuehaiPan in #33162
* support loading model without config.json file by @itazap in #32356
* Add validation for maximum sequence length in modeling_whisper.py by @AmirMohammadFakhimi in #33196
* add self.head_dim for VisionAttention in Qwen2-VL by @GeLee-Q in #33211
* support 3D attention mask in bert by @gathierry in #32105
* Support reading tiktoken tokenizer.model file by @itazap in #31656
* red-ci on main, fix copies by @ArthurZucker in #33356
* RoPE: fix BC warning by @gante in #33331
* Fix Prefill docs by @Rocketknight1 in #33352
* Update author for QLorA/PEFT community notebook by @daniellok-db in #33338
* add sdpa mbart by @nbroad1881 in #32033
* Fix quantized cache tests by @zucchini-nlp in #33351
* schedulefree optimizers by @winglian in #30079
* Add visit webpage tool by @aymeric-roucher in #33353
* Fixed Majority of the Typos in `transformers[en]` Documentation by @nnilayy in #33350
* Compile compatibilty for decoder-only models by @zucchini-nlp in #32617
* Adjust templates by @LysandreJik in #33384
* Remove repeated prepare_images in processor tests by @amyeroberts in #33163
* Fix import of `FalconMambaForCausalLM` by @younesbelkada in #33381
* Import structure & first three model refactors by @LysandreJik in #31329
* VLM: fixes after refactor by @zucchini-nlp in #32907
* fixed Mask2Former image processor segmentation maps handling by @maciej-adamiak in #33364
* Bug Fix: Update hub.py to fix NoneType error by @rishiraj in #33315
* Update WhisperTokenizer Doc: Timestamps and Previous Tokens Behaviour by @bruno-hays in #33390
* Make StaticCache configurable at model construct time by @guangy10 in #32830
* use diff internal model in tests by @itazap in #33387
* Fix `FbgemmFp8Linear` not preserving tensor shape by @vgel in #33239
* Fix failing windows by @LysandreJik in #33436
* Remove deprecated task in load_dataset by @albertvillanova in #33433
* Dynamic number of speculative tokens in order to accelerate speculative decoding by @jmamou in #33258
* Fix: Cast prefetch_bucket_size to integer for deepspeed >= 0.15 by @kiddj in #33402
* [docs] add the missing huggingface hub username by @faaany in #33431
* [docs] add the missing tokenizer when pushing models to huggingface hub by @faaany in #33428
* Update stale.yml by @LysandreJik in #33434
* Docs - update formatting of llama3 model card by @MichaelCurrin in #33438
* Fix incomplete sentence in `Zero-shot object detection` documentation by @sergiopaniego in #33430
* Fix flax whisper tokenizer bug by @hannan72 in #33151
* Clean-up deprecated code by @zucchini-nlp in #33446
* Fix default revision for pipelines by @ankane in #33395
* Revive AMD scheduled CI by @ydshieh in #33448
* Allow send `SSH into runner` info. to DM by @ydshieh in #33346
* Correct Whisper's beam search scores computation by @ylacombe in #32336
* Qwen2-VL: clean-up and add more tests by @zucchini-nlp in #33354
* [whisper] Clarify error message when setting max_new_tokens by @benniekiss in #33324
* [docs] refine the doc for `train with a script` by @faaany in #33423
* Return image hidden states by @zucchini-nlp in #33426
* add a callback hook right before the optimizer step by @winglian in #33444
* Enable `padding_side` as call time kwargs by @zucchini-nlp in #33385
* Mitigate a conflict when using sentencepiece by @tengomucho in #33327
* [Phi-3] Bug on stale kv cache by @garg-amit in #33129
* Fix the initialization of the cache when we have multi gpu by @SunMarc in #33303
* Enable finetuning with torchao quantized model by @SunMarc in #33361
* Corrected `Agents and tools` documentation links typos by @sergiopaniego in #33471
* chore: fix typo in comment in tokenization_utils_base.py by @DavidLemayian in #33466
* Cohere: update RoPE structure by @gante in #33408
* Fix SSH workflow by @ydshieh in #33451
* Add keypoint-detection task guide by @merveenoyan in #33274
* Uniformize kwargs for LLaVa processor and update docs by @yonigozlan in #32858
* `Agents, supercharged - Multi-agents, External tools, and more` docs typo fixed by @sergiopaniego in #33478
* [i18n-ar] Add File : `docs/source/ar/_toctree.yml` by @AhmedAlmaghz in #32696
* [Whisper test] Fix some failing tests by @ylacombe in #33450
* Fix: Qwen2-VL training on video datasets by @hiyouga in #33307
* Updated Trainer's liger-kernel integration to call correct patching API by @shimizust in #33502
* Replace `accelerator.use_fp16` in examples by @hlky in #33513
* Fix parametrization-based weight norm by @ylacombe in #33275
* Fix number of patch check for different vision feature select strategy by @insujang in #32494
* chore: migrate coverage cfg to pyproject.toml by @SauravMaheshkar in #32650
* idefics2 enable_input_require_grads not aligned with disable_input_re… by @sywangyi in #33194
* Update chameleon.md — fix runtime type error by @maxwbuckley in #33494
* Add explicit example for RAG chat templating by @A-Duss in #33503
* CI Build image - move runners by @glegendre01 in #33530
* fix to jamba config, asserting attention and expert offset by @ErezSC42 in #33316
* Fix missing `sequences_scores` in the Whisper beam search output by @Nik-Kras in #32970
* Uniformize kwargs for Pixtral processor by @yonigozlan in #33521
* Add revision to trainer push_to_hub by @teamclouday in #33482
* fix patch_attention_mask incorrect setting which leads to the differe… by @sywangyi in #33499
* Support LLaVa-OV-Chat by @zucchini-nlp in #33532
* Decorator for easier tool building by @aymeric-roucher in #33439
* Fix for slow the bug tokenizer adding spaces to single id decodes by @DuyguA in #32564
* Chat template: save and load correctly for processors by @zucchini-nlp in #33462
* Fix missing head_dim in llama config from gguf model by @Isotr0py in #33526
* [i18n-ur] Added README_ur.md file by @akkefa in #33461
* fix the wandb logging issue by @ZIYU-DEEP in #33464
* Fix tests in ASR pipeline by @ylacombe in #33545
* Added support for bfloat16 to zero-shot classification pipeline by @umarbutler in #33554
* Pipeline: no side-effects on `model.config` and `model.generation_config` 🔫 by @gante in #33480
* Return attention mask in ASR pipeline to avoid warnings by @Rocketknight1 in #33509
* enforce original size to be a list by @dom-dziela in #33564
* Improve compiled RT-DETR inference speed by @yonigozlan in #33412
* Fix bnb dequantization by @SunMarc in #33546
* Load and save video-processor from separate folder by @zucchini-nlp in #33562
* VLMs: enable generation tests by @zucchini-nlp in #33533
* rag: fix CI by @gante in #33578
* Cache: don't show warning in forward passes when `past_key_values` is None by @gante in #33541
* fix tests with main revision and read token by @molbap in #33560
* add uniform processors for altclip + chinese_clip by @molbap in #31198
* Generate: check that `attention_mask` is 2D by @gante in #33575
* change sequence_bias type of SequenceBiasLogitsProcessor to list, add… by @VladOS95-cyber in #33375
* [`Mamba2`] Move dt calculations to kernel by @vasqu in #33520
* Cache: don't throw warnings on `gemma2` when instantiating a new cache by @gante in #33595
* Uniformize kwargs for Paligemma processor and update docs by @yonigozlan in #33571
* [tests] skip tests for xpu by @faaany in #33553
* [tests] enable GemmaIntegrationTest on XPU by @faaany in #33555
* Fix Llama 3 TikToken conversion by @pcuenca in #33538
* Docs: add the ability to manually trigger jobs by @gante in #33598
* Fix CircleCI nightly run by @ydshieh in #33558
* Allow CI could be run on private forked repositories (e.g. new model additions) by @ydshieh in #33594
* [tests] make more tests device-agnostic by @faaany in #33580
* Update modeling_mamba2.py, fix pad size by @klae01 in #32599
* Generate: remove flakyness in `test_generate_from_inputs_embeds_decoder_only` by @gante in #33602
* Remove unnecessary CPM model tests by @amyeroberts in #33621
* Add sdpa for BioGpt by @OmarManzoor in #33592
* VLM generate: tests can't generate image/video tokens by @gante in #33623
* Fix missing test in `torch_job` by @ydshieh in #33593
* Add support for args to ProcessorMixin for backward compatibility by @yonigozlan in #33479
* Fix contrastive search to correctly handle input with padding by @ducviet00 in #33507
* Generate: assistant should sample when the main model samples by @gante in #33534
* Fix some missing tests in circleci by @ydshieh in #33559
* Update daily ci to use new cluster by @ydshieh in #33627
* Fix qwen2vl float16 inference bug by @GeLee-Q in #33312
* Fix typos by @litianjian in #33583
* enable low-precision pipeline by @jiqing-feng in #31625
* Pixtral update example checkpoint by @amyeroberts in #33633
* Sdpa dino v2 by @avishaiElmakies in #33403
* Clean up Unpack imports by @molbap in #33631
* Fix DPT /Dinov2 sdpa regression on main by @molbap in #33660
* handle dependency errors in check_imports by @molbap in #33622
* add back self.max_position_embeddings = config.max_position_embeddings by @chengchengpei in #33550
* Fix Llava conversion for LlavaQwen2ForCausalLM with Clip vision tower by @Isotr0py in #33613
* Uniformize kwargs for Udop processor and update docs by @yonigozlan in #33628
* Generation: deprecate `PreTrainedModel` inheriting from `GenerationMixin` by @gante in #33203
* Enable BNB multi-backend support by @jiqing-feng in #31098
* Fix error string after refactoring into get_chat_template by @tibor-reiss in #33652
* uniformize git processor by @yonigozlan in #33668
* Fix CIs post merging modular transformers by @ArthurZucker in #33681
* Fixed docstring for cohere model regarding unavailability of prune_he… by @mnauf in #33253
* Generation tests: update imagegpt input name, remove unused functions by @gante in #33663
* Improve Error Messaging for Flash Attention 2 on CPU by @sizhky in #33655
* Gemma2: fix config initialization (`cache_implementation`) by @gante in #33684
* Fix ByteLevel alphabet missing when Sequence pretokenizer is used by @umarbutler in #33556
* Uniformize kwargs for image-text-to-text processors by @yonigozlan in #32544
* 🚨🚨 Setting default behavior of assisted decoding by @jmamou in #33657
* tests: fix pytorch tensor placement errors by @dvrogozh in #33485
* bump tokenizers, fix added tokens fast by @ArthurZucker in #32535
* [Pixtral] Improve docs, rename model by @NielsRogge in #33491
## Significant community contributions
The following contributors have made significant changes to the library over the last release:
* @enchantee00
* 🌐 [i18n-KO] Translated `chat_templating.md` to Korean (#32362)
* @faychu
* Add Qwen2-Audio (#32137)
* Fix a bug in Qwen2Audio (#32552)
* @010kim
* 🌐 [i18n-KO] Translated `ko-llm_tutorial_optimization.md` to Korean (#32372)
* @cjfghk5697
* 🌐 [i18n-KO] Translated `trainer.md` to Korean (#32260)
* @younesbelkada
* Add new model (#32615)
* Mamba / FalconMamba: Fix mamba left padding (#32677)
* FIX / Hub: Also catch for `exceptions.ConnectionError` (#31469)
* Fix: Fix `FalconMamba` training issues due to incompatible kernels (#33195)
* Fix import of `FalconMambaForCausalLM` (#33381)
* @4N3MONE
* 🌐 [i18n-KO] Translated `deepspeed.md` to Korean (#32431)
* @jerryzh168
* Add TorchAOHfQuantizer (#32306)
* @MHRDYN7
* Add Flax Dinov2 (#31960)
* @kamilakesbi
* Add Descript-Audio-Codec model (#31494)
* @Isotr0py
* Fix incorrect vocab size retrieval in GGUF config (#32551)
* Add chat_template for tokenizer extracted from GGUF model (#32908)
* 🚨 Support dequantization for most GGML types (#32625)
* Fix missing head_dim in llama config from gguf model (#33526)
* Fix Llava conversion for LlavaQwen2ForCausalLM with Clip vision tower (#33613)
* @AhmedAlmaghz
* [i18n-ar] add README_ar.md to README.md (#32583)
* [i18n-ar] Add File : `docs/source/ar/_toctree.yml` (#32696)
* @simonJJJ
* support qwen2-vl (#32318)
* simple align qwen2vl kv_seq_len calculation with qwen2 (#33161)
* fix qwen2vl vision eager-attention (#33213)
* @jpizarrom
* 🚨 Add Blip2ForImageTextRetrieval (#29261)
* @mayank31398
* Granite language models (#31502)
* fix model name and copyright (#33152)
* Granitemoe (#33207)
* @hackyon
* [RoBERTa-based] Add support for sdpa (#30510)
* @Muennighoff
* Add OLMoE (#32406)
* Add paper link (#33305)
* @VladOS95-cyber
* Add Qwen2Moe GGUF loading support (#33264)
* change sequence_bias type of SequenceBiasLogitsProcessor to list, add… (#33375)
* @jiqing-feng
* enable low-precision pipeline (#31625)
* Enable BNB multi-backend support (#31098)
Release v4.44.2 (2024-08-22)
Patch release v4.44.2, mostly 2 regressions that were not caught for Jamba and for processors!
- Fix: Jamba cache fails to use torch.nn.module (#32894) Authored by @xgal
- Fix: No need to dtype A in Jamba (#32924) @xgal
- Fix: Regression on Processor.save_pretrained caused by #31691 (#32921) Authored by @leloykun
Patch release v4.44.1 (2024-08-20)
## Here are the different fixes, mostly Gemma2 context length, nits here and there, and generation issues
- is_torchdynamo_compiling -- cast a wide exception net (#32476) by @gante
- Revert "fixes to properly shard FSDP across cpu and meta for cpu_effcient_loading for prequantized 4bit (#32276)" (#32477) by @gante and @matthewdouglas
- Gemma2: fix FA2 generation (#32553) by @zucchini-nlp
- Fix: FA2 with packed training (#32487) by @zucchini-nlp
- Fix sliding window attention used in Gemma2FlashAttention2 (#32522) by @brcps12
- Automatically add transformers tag to the modelcard (#32623) by @LysandreJik
- add back the position ids (#32554) by @ArthurZucker
- Use head_dim if in config for RoPE (#32495) @suiyoubi @ArthurZucker
- Revert PR 32299, flag users when Zero-3 was missed (#32851) by @muellerzr
- fix multi-gpu with static cache (#32543) by @SunMarc
- Reduce the error log when using core models that need their weights r… (#32656) by @muellerzr
- Fix VLM generation issues (#32836) by @zucchini-nlp
- Fix generate with inputs_embeds as input (#32493) (this PR has some cherry-pick)
**Full Changelog**: https://github.com/huggingface/transformers/compare/v4.44.0...v4.44.1
Release v4.44.0 (2024-08-06)
# Release v4.44.0: End to end compile generation!!! Gemma2 (with assisted decoding), Codestral (Mistral for code), Nemotron, Efficient SFT training, CPU Offloaded KVCache, torch export for static cache
This release comes a bit early in our cycle because we wanted to ship important and requested models along with improved performances for everyone!
All of these are included with examples in the awesome https://github.com/huggingface/local-gemma repository! 🎈 We tried to share examples of what is now possible with all the shipped features! Kudos to @gante, @sanchit-gandhi and @xenova
## 💥 End-to-end generation compile
*Generate: end-to-end compilation #30788 by @gante*: `model.generate` now supports compiling! There are a few limitations, but here is a small snippet:
```python3
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import copy
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3.1-8B", torch_dtype=torch.bfloat16, device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3.1-8B")
# compile generate
compiled_generate = torch.compile(model.generate, fullgraph=True, mode="reduce-overhead")
# compiled generate does NOT accept parameterization except a) model inputs b) a generation config
generation_config = copy.deepcopy(model.generation_config)
generation_config.pad_token_id = model.config.eos_token_id
model_inputs = tokenizer(["Write a poem about the market crashing in summer"], return_tensors="pt")
model_inputs = model_inputs.to(model.device)
output_compiled = compiled_generate(**model_inputs, generation_config=generation_config)
print(output_compiled)
```
## ⚡ 3 to 5x compile speedup (compilation time 👀 not runtime)
* 3-5x faster torch.compile forward compilation for autoregressive decoder models #32227* by @fxmarty .
As documented on the PR, this makes the whole generation a lot faster when you re-use the cache!
You can see this when you run `model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)`
## 🪶 Offloaded KV cache: offload the cache to CPU when you are GPU poooooor 🚀
* Offloaded KV Cache #31325* by @n17s : you just have to set `cache_implementation="offloaded"` when calling `from_pretrained` or using this:
``` python3
from transformers import GenerationConfig
gen_config = GenerationConfig(cache_implementation="offloaded", # other generation options such as num_beams=4,num_beam_groups=2,num_return_sequences=4,diversity_penalty=1.0,max_new_tokens=50,early_stopping=True)
outputs = model.generate(inputs["input_ids"],generation_config=gen_config)
```
## 📦 Torch export for static cache
`pytorch` team gave us a great gift: you can now use `torch.export` directly compatible with [Executorch](https://pytorch.org/executorch/main/index.html)! Find examples [here](https://github.com/huggingface/transformers/pull/31706).
* Make static cache compatible with torch.export #32168 by @guangy10
This also unlocks support for prompt reuse:
```python3
import os, torch, copy
from transformers import AutoModelForCausalLM, AutoTokenizer, DynamicCache
device = "cuda"
ckpt = "meta-llama/Meta-Llama-3.1-8B-Instruct"
INITIAL_PROMPT = "From now on, you are going to answer all my questions with historical details. Make sure to always add a bit of french here and there, for style."
model = AutoModelForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16)
model.to(device)
tokenizer = AutoTokenizer.from_pretrained(ckpt)
prompt_cache = DynamicCache()
inputs = tokenizer(INITIAL_PROMPT, return_tensors="pt").to("cuda")
prompt_cache = model(**inputs, past_key_values = prompt_cache).past_key_values
prompt = "Why are french people obsessed with french?"
new_inputs = tokenizer(INITIAL_PROMPT + prompt, return_tensors="pt").to("cuda")
past_key_values = copy.deepcopy(prompt_cache)
outputs = model.generate(**new_inputs, past_key_values=past_key_values,max_new_tokens=20)
response = tokenizer.batch_decode(outputs)[0]
print(response)
prompt = "What is the best city to swim in?"
new_inputs = tokenizer(INITIAL_PROMPT + prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**new_inputs, past_key_values=copy.deepcopy(prompt_cache),max_new_tokens=20)
response = tokenizer.batch_decode(outputs)[0]
```
## Gemma2: assisted decoding
*Gemma 2: support assisted generation #32357* by @gante
We now have a 2B Gemma 2 model -- a perfect sidekick for the 27B with assisted generation. We've enabled assisted generation in gemma 2, with a caveat: assisted generation currently requires the use of a windowless cache (as opposed to the default cache for gemma 2), so you might observe some output mismatch on long sequences. Read more about it [here](https://huggingface.co/blog/gemma-july-update#assisted-generation).
```py
# transformers assisted generation reference:
# https://huggingface.co/docs/transformers/main/en/llm_optims#speculative-decoding
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# we DON’T recommend using the 9b model with the 2b model as its assistant
assistant_model_name = 'google/gemma-2-2b-it'
reference_model_name = 'google/gemma-2-27b-it'
tokenizer = AutoTokenizer.from_pretrained(reference_model_name)
model = AutoModelForCausalLM.from_pretrained(
reference_model_name, device_map='auto', torch_dtype=torch.bfloat16
)
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_name, device_map='auto', torch_dtype=torch.bfloat16
)
model_inputs = tokenizer("Einstein's theory of relativity states", return_tensors="pt").to(model.device)
generation_options = {
"assistant_model": assistant_model,
"do_sample": True,
"temperature": 0.7,
"max_new_tokens": 64,
}
outputs = model.generate(**model_inputs, **generation_options)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
```
## Nemotron support

> Nemotron-4-340B-Instruct is a large language model (LLM) that can be used as part of a synthetic data generation pipeline to create training data that helps researchers and developers build their own LLMs. It is a fine-tuned version of the Nemotron-4-340B-Base model, optimized for English-based single and multi-turn chat use-cases. It supports a context length of 4,096 tokens.
The conversion script should be able to cover Minitron and Nemotron, thanks and kudos to @suiyoubi. See:
* Add Nemotron HF Support #31699
## Codestral support

> Codestral is trained on a diverse dataset of 80+ programming languages, including the most popular ones, such as Python, Java, C, C++, JavaScript, and Bash. It also performs well on more specific ones like Swift and Fortran. This broad language base ensures Codestral can assist developers in various coding environments and projects.
Codestral saves developers time and effort: it can complete coding functions, write tests, and complete any partial code using a fill-in-the-middle mechanism. Interacting with Codestral will help level up the developer’s coding game and reduce the risk of errors and bugs.
It's mamba2 architecture, was a bit of a pain to remove all einops but hope we made it better for everyone!
* Add codestral mamba2 #32080 by @molbap and @vasqu
## Breaking changes:
We removed the chat template **in the code**, they should all be on the hub!
* 🚨 No more default chat templates #31733 by @Rocketknight1
## Long-form decoding for whisper, even faster:
Our great @sanchit-gandhi worked on porting the recent compile upgrades to long form decoding in
* [whisper] compile compatibility with long-form decoding #31772
## What's Changed
* Enhancing SFT Training Efficiency Using Packing and FlashAttention2 with Position IDs by @RhuiDih in https://github.com/huggingface/transformers/pull/31629
* Updated `ruff` to the latest version by @Sai-Suraj-27 in https://github.com/huggingface/transformers/pull/31926
* fix by @gante in https://github.com/huggingface/transformers/pull/32162
* fix: Fixed an if condition that is always evaluating to true by @Sai-Suraj-27 in https://github.com/huggingface/transformers/pull/32160
* [docs] change temperature to a positive value by @faaany in https://github.com/huggingface/transformers/pull/32077
* adds: extra_repr() to MambaRMSNorm to include hidden size / size of weights in the layer by @rohitdwivedula in https://github.com/huggingface/transformers/pull/32171
* fix: default value reflects the runtime environment variables rather than the ones present at import time. by @junrae6454 in https://github.com/huggingface/transformers/pull/32153
* Update qwen2.md by @ArtificialZeng in https://github.com/huggingface/transformers/pull/32108
* Remove conversational pipeline tests by @amyeroberts in https://github.com/huggingface/transformers/pull/32099
* RoPE: relaxed rope validation by @gante in https://github.com/huggingface/transformers/pull/32182
* let's not warn when someone is running a forward by @ArthurZucker in https://github.com/huggingface/transformers/pull/32176
* Fix resize embedding with Deepspeed by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32192
* Fix float8_e4m3fn in modeling_utils by @SunMarc in https://github.com/huggingface/transformers/pull/32193
* Support dequantizing GGUF FP16 format by @PenutChen in https://github.com/huggingface/transformers/pull/31783
* :rotating_light: No more default chat templates by @Rocketknight1 in https://github.com/huggingface/transformers/pull/31733
* fix: Replaced deprecated `unittest method` with the correct one by @Sai-Suraj-27 in https://github.com/huggingface/transformers/pull/32198
* [whisper] fix short-form output type by @sanchit-gandhi in https://github.com/huggingface/transformers/pull/32178
* remove unnecessary guard code related with pytorch versions 1.4.2 ~ 1.7.0 by @statelesshz in https://github.com/huggingface/transformers/pull/32210
* Update question_answering.py by @avlewis in https://github.com/huggingface/transformers/pull/32208
* [BigBird Pegasus] set _supports_param_buffer_assignment to False by @kashif in https://github.com/huggingface/transformers/pull/32222
* [warnings] fix E721 warnings by @kashif in https://github.com/huggingface/transformers/pull/32223
* Follow up for #31973 by @ydshieh in https://github.com/huggingface/transformers/pull/32025
* translate philosophy.md to chinese by @statelesshz in https://github.com/huggingface/transformers/pull/32177
* Allow a specific microphone to be used by the ffmpeg audio pipeline utility functions. Default to using the currently active microphone on Mac by @jrhe in https://github.com/huggingface/transformers/pull/31846
* Fix code snippet for Grounding DINO by @qubvel in https://github.com/huggingface/transformers/pull/32229
* Generation: stop at `eos` for assisted decoding by @zucchini-nlp in https://github.com/huggingface/transformers/pull/31301
* Llava: generate without images by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32183
* Resize embeds with DeepSpeed by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32214
* don't log base model architecture in wandb if log model is false by @joaonadkarni in https://github.com/huggingface/transformers/pull/32143
* Refactor: Removed un-necessary `object` base class by @Sai-Suraj-27 in https://github.com/huggingface/transformers/pull/32230
* Adds: extra_repr for RMSNorm layers in most models by @rohitdwivedula in https://github.com/huggingface/transformers/pull/32204
* Add check for `target_sizes is None` in `post_process_image_guided_detection` for owlv2 by @catalys1 in https://github.com/huggingface/transformers/pull/31934
* [tests] fix `static` cache implementation is not compatible with `attn_implementation==flash_attention_2` by @faaany in https://github.com/huggingface/transformers/pull/32039
* Flash-Attn: fix generation when no attention mask or no pading by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32241
* More flexible trigger condition by @ydshieh in https://github.com/huggingface/transformers/pull/32251
* Llama 3.1: replace for loop by tensor ops at inv_freq initialization by @gante in https://github.com/huggingface/transformers/pull/32244
* 🚨 Bloom support for cache class by @zucchini-nlp in https://github.com/huggingface/transformers/pull/31445
* Upload new model failure report to Hub by @ydshieh in https://github.com/huggingface/transformers/pull/32264
* Optimize t5 tokenize logic to avoid redundant calls by @leejet in https://github.com/huggingface/transformers/pull/32270
* fix: Fixed wrong argument passed to `convert_blip_checkpoint` function call by @Sai-Suraj-27 in https://github.com/huggingface/transformers/pull/32262
* Repo: remove exceptions in `check_docstrings` by @gante in https://github.com/huggingface/transformers/pull/32259
* make `p_mask` a numpy array before passing to `select_starts_ends` by @faaany in https://github.com/huggingface/transformers/pull/32076
* fix(docs): Fixed a link in docs by @Sai-Suraj-27 in https://github.com/huggingface/transformers/pull/32274
* Generate: end-to-end compilation by @gante in https://github.com/huggingface/transformers/pull/30788
* Whisper tokenizer word level timestamps by @kamilakesbi in https://github.com/huggingface/transformers/pull/32197
* [pipeline] fix padding for 1-d tensors by @sanchit-gandhi in https://github.com/huggingface/transformers/pull/31776
* Make static cache compatible with torch.export by @guangy10 in https://github.com/huggingface/transformers/pull/32168
* Add stream messages from agent run for gradio chatbot by @aymeric-roucher in https://github.com/huggingface/transformers/pull/32142
* use torch 2.4 in 2 CI jobs by @ydshieh in https://github.com/huggingface/transformers/pull/32302
* Docs: fix GaLore optimizer code example by @gil2rok in https://github.com/huggingface/transformers/pull/32249
* Fix GGUF dequantize for `gguf==0.9.1` by @Isotr0py in https://github.com/huggingface/transformers/pull/32298
* Cast epochs_trained to int when resuming training by @teddy-f-47 in https://github.com/huggingface/transformers/pull/32286
* feat(ci): set `fetch-depth: 0` in trufflehog checkout step by @McPatate in https://github.com/huggingface/transformers/pull/31663
* Fix M4T for ASR pipeline by @ylacombe in https://github.com/huggingface/transformers/pull/32296
* Docs: formatting nits by @gante in https://github.com/huggingface/transformers/pull/32247
* Alternative agent plan by @plaggy in https://github.com/huggingface/transformers/pull/32295
* fix: Added missing raise keyword for few exceptions by @Sai-Suraj-27 in https://github.com/huggingface/transformers/pull/32333
* fixes to properly shard FSDP across cpu and meta for cpu_efficient_loading for prequantized 4bit by @winglian in https://github.com/huggingface/transformers/pull/32276
* fixes #32329 : The Torch code is correct - to get an average of 10% o… by @fkrasnov2 in https://github.com/huggingface/transformers/pull/32335
* Repo checks: skip docstring checks if not in the diff by @gante in https://github.com/huggingface/transformers/pull/32328
* Fix slow GemmaTokenizer and improve SPM slow -> fast conversion process by @xenova in https://github.com/huggingface/transformers/pull/32191
* LLaVA-NeXT: fix anyres shapes by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32314
* Gemma2 and flash-attention by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32188
* Llama 3.1: Fix incorrect `inv_freq` assignment by @gante in https://github.com/huggingface/transformers/pull/32330
* [Idefics2] - Fix FA2 call for Perceiver layer by @amyeroberts in https://github.com/huggingface/transformers/pull/32275
* Gemma 2: support assisted generation by @gante in https://github.com/huggingface/transformers/pull/32357
* Fix error when streaming to gradio with non-string tool arguments by @aymeric-roucher in https://github.com/huggingface/transformers/pull/32360
* >3-5x faster torch.compile forward compilation for autoregressive decoder models by @fxmarty in https://github.com/huggingface/transformers/pull/32227
* fix: Fixed `staticmethods` with self as first argument by @Sai-Suraj-27 in https://github.com/huggingface/transformers/pull/32361
* fix: warmup_steps check for training_args by @Ricardo-L-C in https://github.com/huggingface/transformers/pull/32236
* LLaVa: add cache class attribute by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32278
* [enc-dec cache] fix bug in indexing by @sanchit-gandhi in https://github.com/huggingface/transformers/pull/32370
* [whisper] compile compatibility with long-form decoding by @sanchit-gandhi in https://github.com/huggingface/transformers/pull/31772
* Remove size check between attn_weights and kv_seq_len for phi3 by @helunwencser in https://github.com/huggingface/transformers/pull/32339
* add missing attribute _supports_param_buffer_assignment for gpt-j. by @nv-guomingz in https://github.com/huggingface/transformers/pull/32359
* Check device map for saving tokenizer config on TPU (fix for issue #31971) by @ayukh in https://github.com/huggingface/transformers/pull/32043
* update clean_up_tokenization_spaces warning by @itazap in https://github.com/huggingface/transformers/pull/32371
* Empty list in defaults for LLaMA special tokens during weights conversion by @ViktorooReps in https://github.com/huggingface/transformers/pull/32342
* Fix conflicting key in init kwargs in PreTrainedTokenizerBase by @OmarManzoor in https://github.com/huggingface/transformers/pull/31233
* Offloaded KV Cache by @n17s in https://github.com/huggingface/transformers/pull/31325
* Docker: add `speech` dep to the consistency docker image by @gante in https://github.com/huggingface/transformers/pull/32374
* Fixed Hybrid Cache Shape Initialization. by @OsamaS99 in https://github.com/huggingface/transformers/pull/32163
* Yell at the user if zero-3 init wasn't performed, but expected to have been done by @muellerzr in https://github.com/huggingface/transformers/pull/32299
* Update docs by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32368
* RoPE: Add numerical tests ✨ by @gante in https://github.com/huggingface/transformers/pull/32380
* [generate] only require an attention mask for mps with torch<2.4 by @sanchit-gandhi in https://github.com/huggingface/transformers/pull/32367
* fix: (issue #32124) Exception raised when running `transformers/examples/flax/language-modeling/t5_tokenizer_model.py`. by @fshp971 in https://github.com/huggingface/transformers/pull/32157
* MixtralFlashAttention2: put "plus 1" inside parentheses when calculating rotary_seq_len, allowing None position_ids input. by @Luke20000429 in https://github.com/huggingface/transformers/pull/31500
* Bump keras from 2.8.0 to 2.13.1 in /examples/research_projects/decision_transformer by @dependabot in https://github.com/huggingface/transformers/pull/32393
* fix: SeamlessM4TFeatureExtractor stride remainder by @TechInterMezzo in https://github.com/huggingface/transformers/pull/32088
* Phi3 tests: fix typing for Python 3.8 by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32388
* #32184 save total_vocab_size by @itazap in https://github.com/huggingface/transformers/pull/32240
* add values for neftune by @nbroad1881 in https://github.com/huggingface/transformers/pull/32399
* Fix documentation references to google/bit-50 model by @JuanFKurucz in https://github.com/huggingface/transformers/pull/32407
* Persist embedding type of BART and mBART models after resize by @AbdiHaryadi in https://github.com/huggingface/transformers/pull/32242
* fix: Updated `test_embeded_special_tokens` for luke and mluke models by @Sai-Suraj-27 in https://github.com/huggingface/transformers/pull/32413
* Respect the config's attn_implementation if set by @amyeroberts in https://github.com/huggingface/transformers/pull/32383
* Fix documentation links and code reference to model llava-next by @JuanFKurucz in https://github.com/huggingface/transformers/pull/32434
* Cache: create docs by @zucchini-nlp in https://github.com/huggingface/transformers/pull/32150
* Llava: fix checkpoint_doc by @RUFFY-369 in https://github.com/huggingface/transformers/pull/32458
* add the missing flash attention test marker by @faaany in https://github.com/huggingface/transformers/pull/32419
* Update kwargs validation for `preprocess` with decorator by @qubvel in https://github.com/huggingface/transformers/pull/32024
* Fix get large model config for Switch Transformer encoder only tester by @JuanFKurucz in https://github.com/huggingface/transformers/pull/32438
* Dependencies: fix typo by @gante in https://github.com/huggingface/transformers/pull/32389
* Add Nemotron HF Support by @suiyoubi in https://github.com/huggingface/transformers/pull/31699
* Generate: fix end to end compilation by @gante in https://github.com/huggingface/transformers/pull/32465
* Add codestral mamba2 by @molbap in https://github.com/huggingface/transformers/pull/32080
## New Contributors
* @RhuiDih made their first contribution in https://github.com/huggingface/transformers/pull/31629
* @rohitdwivedula made their first contribution in https://github.com/huggingface/transformers/pull/32171
* @ArtificialZeng made their first contribution in https://github.com/huggingface/transformers/pull/32108
* @avlewis made their first contribution in https://github.com/huggingface/transformers/pull/32208
* @jrhe made their first contribution in https://github.com/huggingface/transformers/pull/31846
* @joaonadkarni made their first contribution in https://github.com/huggingface/transformers/pull/32143
* @catalys1 made their first contribution in https://github.com/huggingface/transformers/pull/31934
* @leejet made their first contribution in https://github.com/huggingface/transformers/pull/32270
* @guangy10 made their first contribution in https://github.com/huggingface/transformers/pull/32168
* @gil2rok made their first contribution in https://github.com/huggingface/transformers/pull/32249
* @teddy-f-47 made their first contribution in https://github.com/huggingface/transformers/pull/32286
* @plaggy made their first contribution in https://github.com/huggingface/transformers/pull/32295
* @fkrasnov2 made their first contribution in https://github.com/huggingface/transformers/pull/32335
* @helunwencser made their first contribution in https://github.com/huggingface/transformers/pull/32339
* @nv-guomingz made their first contribution in https://github.com/huggingface/transformers/pull/32359
* @ayukh made their first contribution in https://github.com/huggingface/transformers/pull/32043
* @n17s made their first contribution in https://github.com/huggingface/transformers/pull/31325
* @OsamaS99 made their first contribution in https://github.com/huggingface/transformers/pull/32163
* @fshp971 made their first contribution in https://github.com/huggingface/transformers/pull/32157
* @Luke20000429 made their first contribution in https://github.com/huggingface/transformers/pull/31500
* @TechInterMezzo made their first contribution in https://github.com/huggingface/transformers/pull/32088
* @AbdiHaryadi made their first contribution in https://github.com/huggingface/transformers/pull/32242
* @RUFFY-369 made their first contribution in https://github.com/huggingface/transformers/pull/32458
* @suiyoubi made their first contribution in https://github.com/huggingface/transformers/pull/31699
**Full Changelog**: https://github.com/huggingface/transformers/compare/v4.43.4...v4.44.0
v4.43.4 Patch Release (2024-08-05)
# Patch Release v4.43.4
There was a mick mack, now deepseep issues are properly pushed with:
- Resize embeds with DeepSpeed https://github.com/huggingface/transformers/pull/32214
🤗 Enjoy holidays
v4.43.3 Patch deepspeed (2024-07-26)
Patch release v4.43.3:
We still saw some bugs so @zucchini-nlp added:
~- Resize embeds with DeepSpeed #32214~
- don't log base model architecture in wandb if log model is false #32143
Other fixes:
- [whisper] fix short-form output type #32178, by @sanchit-gandhi which fixes the short audio temperature fallback!
- [BigBird Pegasus] set _supports_param_buffer_assignment to False #32222 by @kashif, mostly related to the new super fast init, some models have to get this set to False. If you see a weird behavior look for that 😉
v4.43.2: Patch release (2024-07-24)
- Fix float8_e4m3fn in modeling_utils (#32193)
- Fix resize embedding with Deepspeed (#32192)
- let's not warn when someone is running a forward (#32176)
- RoPE: relaxed rope validation (#32182)